
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于近红外光谱的粳稻种子快速鉴别方法研究
[谢欢1  , 陈争光
, 陈争光1, * , 张庆华2 ]
, 陈争光, 张庆华|
|


作者简介: 谢 欢, 女, 1994年生, 黑龙江八一农垦大学电气与信息学院硕士研究生 e-mail: byxh1010@sina.cm
黑龙江省是我国最大的粳稻产区和商品粮生产基地。 水稻种植过程中, 选择合适的水稻品种是实现高产的关键环节。 在农业生产中, 水稻品种的选择受多方面因素影响, 一般说来, 同一积温带所种植的不同水稻品种在外观上差别不大, 甚至没有差别, 很难通过肉眼观察进行准确区分。 为了快速鉴别肉眼不便区分的不同类别粳稻种子, 提出了一种基于近红外光谱技术的粳稻品种快速无损鉴别方法。 以黑龙江垦区大量种植的3种不同品种的粳稻种子(垦粳5号、 垦粳6号和绥粳4号)作为研究对象, 每个品种选取40个样本, 其中30个样本做为建模集, 10个样本作为预测集, 扫描获取全部120个样本的近红外光谱数据。 对原始光谱数据(11 520~4 000 cm-1)两端进行裁剪, 选取吸光度较强的8 250~5 779cm-1范围内的光谱数据进行研究。 首先建立参照模型, 即直接对光谱数据建立BP模型1, 同时光谱数据经过一阶导数和Savitzky-Golay平滑预处理后建立BP模型2。 模型1的分类正确率为93.3%, 预测集均方根误差RMSEP=0.232 8, 迭代时间 t=3 882.9 s。 模型2的分类正确率为100%, RMSEP=0.070 6, 迭代时间 t=954.5 s。 比较两种模型的评价参数RMSEP发现FD+SG预处理可以提高模型的预测能力, 但是由于两种模型未进行降维处理, 数据量过大, 模型的输入节点过多, 迭代时间太长, 不利于实际应用。 因此利用小波变换多分辨率的特点对数据进行降维处理, 采用预测集残差平方和Press值作为评价指标, 在多个小波类别和参数中选取分解尺度为5的sym2(symlet2)小波对光谱数据进行压缩和降维处理, 将光谱数据由601维降到21维。 以小波变换结果作为神经网络输入, 建立模型3, 并与模型1比较, 模型3的分类正确率为93.3%, RMSEP=0.225 0, 迭代时间 t缩短至198.9 s, 比较结果显示小波降维可以减少神经网络的输入, 简化神经网络的结构, 从而提高迭代速度, 但对提高模型的预测能力效果不明显。 上述三种模型比较结果表明, FD+SG预处理可以提高模型的预测能力, 小波降维可以提高模型的迭代速度, 综合上述三种模型的比较结果分析, 最终建立“FD+SG+小波降维”的21输入、 15个隐层、 3个输出的神经网络鉴别模型4, 其分类正确率达100%, RMSEP=0.029 3, 迭代时间为98.8 s, 表明模型4能够完全实现对三种不同水稻品种的快速、 准确、 无损鉴别。 因此, 所提出的基于近红外光谱的小波降维和反向传播人工神经网络鉴别模型的方法完全可以用于粳稻种子的快速无损鉴别, 同时也为其他农作物种子的快速鉴别提供了参考。
Heilongjiang Province is the largest japonica rice producing area and commodity grain base in China. In the process of rice planting, selecting suitable rice varieties is the key to achieving high yield. In agricultural production, the selection of rice varieties is influenced by factors in many aspects. Generally speaking, different rice varieties planted in the same temperate zone have little difference in appearance, or even no difference. It is difficult to make an accurate distinction by visual observation. In order to accurately distinguish different varieties of japonica rice seeds that are difficult to distinguish by naked eyes, a rapid non-destructive discrimination method for japonica rice based on near-infrared spectroscopy (NIRS) was proposed. 3 varieties of japonica rice seeds (seeds 5th, seeds 6th and Sui japonica 4th) planted in Heilongjiang reclamation area were selected as the research object. For each variety, 40 samples were selected, 30 of which were used as modeling set and 10 as prediction set. The NIRS data of all 120 samples were obtained by scanning. The noise at both ends of the original spectral data (11 520~4 000 cm-1) were clipped, the spectral data in the range of 8 250~5 779 cm-1 with strong absorbance were selected as the research band. Firstly, a reference model was established, that is, BP model 1 was established directly from raw spectral data, and BP model 2 was established from the spectral data preprocessed by first derivative (FD) and Savitzky-Golay (SG). The classification accuracy of model 1 was 93.3% with RMSEP=0.232 8, and the iteration time was t=3 882.9 s. The classification accuracy of model 2 was 100% with RMSEP=0.070 6, and the iteration time was t=954.5 s. Comparing the evaluation parameter RMSEP of the two models, it was found that FD+SG preprocessing can improve the prediction ability of the model. However, because the two models do not reduce the dimension, the amount of data is too large, the input nodes of the model are too many and the iteration time is too long, which is not conducive to the practical application. Therefore, the wavelet transform with multi-resolution characteristic was used to reduce the dimension of the data. The residual sum of squares of the prediction set (Press value) were used as the evaluation index. Sym2(symlet2) wavelet with decomposition scale 5 was selected to compress and reduce the dimension of the spectral data from 601 dimension to 21 dimension. The results of wavelet transform were used as the input of BP model 3, which was compared with model 1. The classification accuracy of the model 3 was 93.3% with RMSEP=0.225 0, and the iteration time was shortened to 198.9 s. The comparison results showed that dimensionality reduction based on wavelet transformation can reduce the input of the neural network, thus simplifying the structure of the neural network and improving the iterative speed, but the effect of improving the prediction ability of the model is not obvious. The comparison results of the three models showed that FD+SG preprocessing can improve the prediction ability of the model, and the wavelet transform can improve the iteration speed of the model. Based on above analysis results, a neural network discrimination model 4 with 21 inputs, 15 hidden layers and 3 outputs of FD+SG+wavelet transform was established. Moreover, its recognition rate of classification was 100% with RMSEP=0.029 3 and the iteration time was t=98.8 s, which could identify three different japonica rice varieties quickly, accurately and non-destructively. Therefore, the method of wavelet reduction and back propagation artificial neural network (BP) discrimination model based on near infrared spectroscopy can be used for rapid and nondestructive discrimination of japonica rice seeds, providing a reference method for other crop seeds recognition.
我国稻区播种面积约占粮食作物总面积的1/4, 因为不同稻区的自然生态环境、 社会经济条件和水稻生产状况等有明显差异, 为使水稻产量或经济效益达到最大化, 对于不同水稻种植区域, 选择合适的水稻品种显得尤为重要。 由于同一地区种植的水稻品种外观差异很微小甚至没有差异, 很难通过肉眼区分, 农业生产中选错水稻品种的情况时有发生[1], 因此水稻种子的品种鉴别对目前农业生产具有重要意义。
近红外光谱分析技术是利用化学计量学方法在样品待测属性值与近红外光谱数据之间建立一个关联模型, 包括定性和定量分析。 由于近红外光谱技术具有速度快、 效率高、 成本低、 无污染、 测量方便等优点[2], 已经被广泛应用于食品[3]、 石油化工[4]、 医药[5]、 农业等各个方面。 近年来近红外光谱分析技术在食品农业方面已经取得了一些成果, 例如在肉制品的鉴别[6]、 水果的品质鉴别[7]等方面。 在对水稻品种鉴别方面, 目前仅有的研究主要是以我国南方籼稻作为研究对象[8], 而应用于东北地区的水稻品种鉴别还少有报道。 东北地区是我国粳稻主产区, 其中黑龙江省是全国最大的粳稻产区。 黑龙江种植的粳稻在外形上有长粒形, 圆形和椭圆形三种外形特征。 一般说来, 在一个积温带种植的水稻品种尽管多样, 但是其外观差异不大, 很难通过肉眼观察进行区分。 本工作以黑龙江垦区的3种外观相似的不同品种水稻作为研究对象, 采集试验中的三种水稻种子的近红外光谱数据, 针对近红外光谱数据的高维和高相关性特点, 利用小波变换对光谱数据降维, 最后结合BP神经网络寻找基于近红外光谱技术的水稻品种鉴别的快速有效的方法。
使用德国Bruker公司的TANGO型号的近红外光谱仪, 分辨率为8 cm-1, 谱区范围11 520~4 000 cm-1。 分析软件采用CAMO公司的Unscrambler X10.3和MathWorks公司的Matlab2016a。
选取黑龙江八一农垦大学实验基地2017年收获的3个不同品种的水稻为研究对象, 分别为垦粳5号、 垦粳6号和绥粳4号, 粒形均为椭圆形。 称取10 g作为一个试验样本, 每个品种取40个样本, 共120个样本, 置于室内自然干燥, 平均含水率8.73%, 含水率方差为8.332× 10-6, 标准差为0.002 9。 使用光谱仪对每个样本扫描32次取平均值作为一个样本的光谱数据。
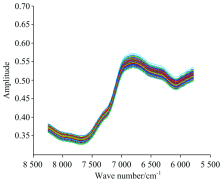
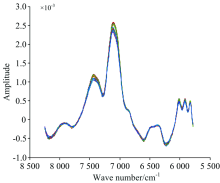
对采集的光谱进行3类预处理操作: 裁剪、 求导和平滑。 光谱曲线在首尾端的噪声较大且吸光度不明显, 因此裁剪掉光谱曲线首尾两端的数据, 保留8 250~5 779 cm-1范围内的光谱数据(如图1所示)作为三个水稻品种分类鉴别的波数范围。 经一阶导数(first deviation, FD)消除基线和其他背景干扰[9], 并在此基础上施加窗口大小为9的Savitzky-Golay(SG)平滑, 降低光谱数据本身所携带的随机噪声。 经过FD+SG预处理后的光谱曲线如图2所示。
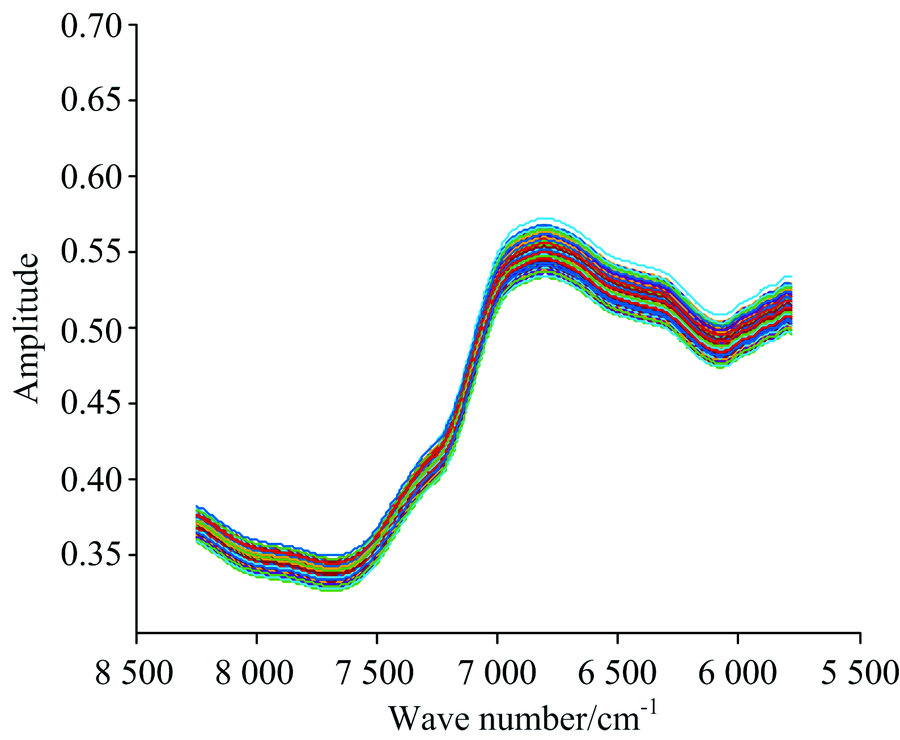 | 图1 经裁剪的原始光谱数据Fig.1 Original NIR spectra after cutting edge |
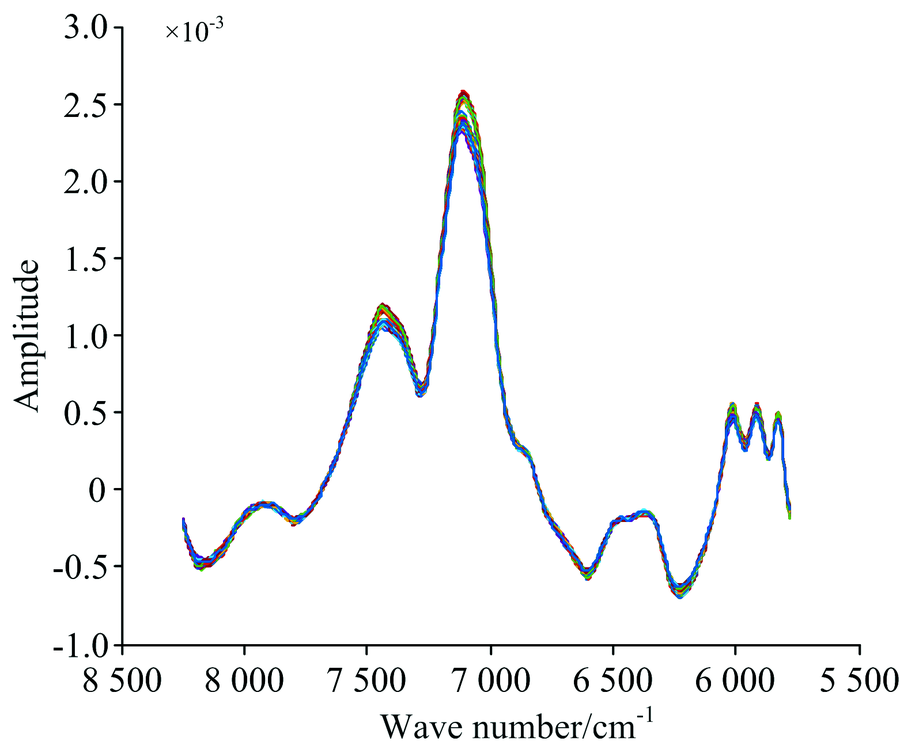 | 图2 经过一阶导数和卷积平滑预处理的近红外光谱数据Fig.2 NIR Spectrum after 1st Der and S-G smoothing |
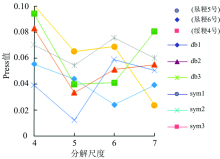
为了减少模型输入规模, 提高模型效率, 利用小波变换对光谱数据进行压缩降维[10]。 考虑到不同的小波基和分解尺度对模型预测能力的影响, 利用模型预测集的预测残差平方和Press值[式(1)]作为评价标准选取小波基和分解尺度。
式中: n为预测集的样本个数, yi为预测集第i个样本实测值,
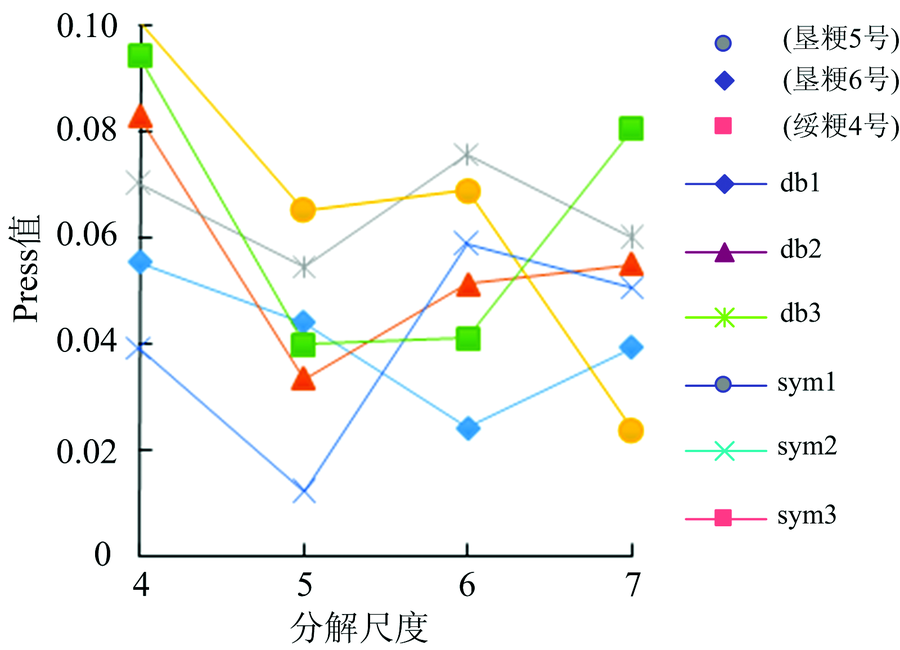 | 图3 不同小波基和分解尺度的Press值Fig.3 Press values of different wavelets and decomposition scales |
选取分解尺度为5的小波基sym2对120个样本进行小波变换压缩, 将601个波长点变量经过小波变换压缩到21个, 压缩倍数约为28, 极大降低了数据处理规模, 提高了模型效率。
人工神经网络通过模拟人脑细胞(神经元)的工作原理, 建立非线性模型实现分类和预测。 目前使用最广泛的是反向传播人工神经网络[12](back propagation, BP), 即多层结构的误差反向传播学习算法, 它具有信息前向传递、 误差反向传递调节网络节点权值和阈值, 使输出尽可能接近期望值的特点。 由于小波压缩后光谱数据有21个结点, 水稻品种有3个类别, 因此BP神经网络输入层有21个输入节点, 输出层有3个节点。 网络各层传递函数采用S型函数, 网络指定参数中学习速率为0.1, 目标误差为0.000 1, 最大迭代次数设为2 000, 经过反复试验, 当隐含层单元数为15时模型效果最好。 最终得到一个21个输入、 15个隐含单元和3个输出单元的3层BP神经网络模型。
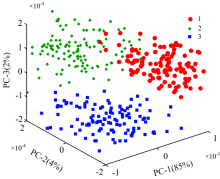
对预处理之后的水稻光谱进行主成分分析, 前3个主成分累积贡献率为91%。 用前3个主成分绘制得分图如图4所示, 从图4可以看出, 垦粳5号(1)与垦粳6号(2)和绥粳4号(3)之间有明显的特征差异。 不同品种的水稻具有良好的聚类效果, 定性描述了3种不同水稻品种的特征差异, 为本研究实现水稻种子分类预测提供了依据。
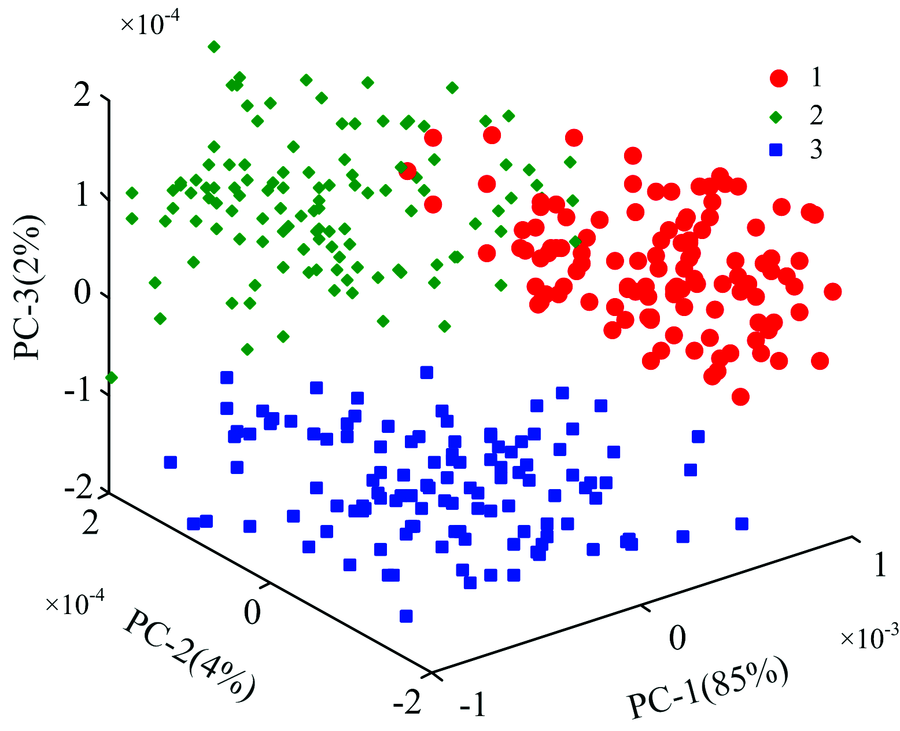 | 图4 120个水稻样本的前3个主成分得分图Fig.4 First 3 PCA score plots for 120 rice seed sample |
利用Kennard-Stone算法按3:1的比例, 将120个样本数据划分为建模集和预测集, 即建模集90个样本(每个品种30个), 预测集30个样本(每个样本10个)。 基于8 250~5 779 cm-1范围内的光谱数据, 根据流程图(图5所示)建立四种BP模型, 即模型1、 模型2、 模型3和模型4。 其中, 神经网络的输入节点数由各自输入的数据维度决定, 即模型1和模型2的输入节点数为601, 模型3和模型4的输入节点为21。 输出节点数由水稻品种数决定, 4个模型均为3个输出, 并分别以100, 010, 001表示垦粳5号(1)、 垦粳6号(2)和绥粳4号(3)。
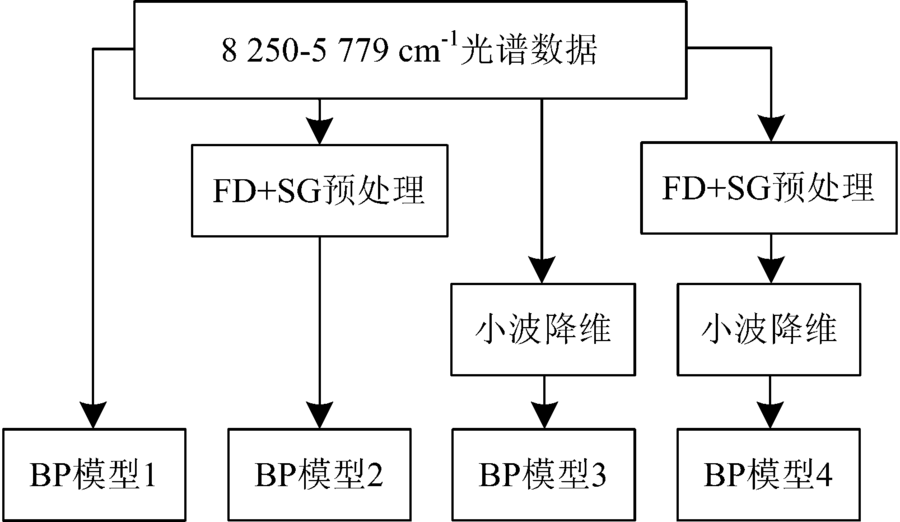 | 图5 基于8 250~5 779 cm-1范围内光谱数据的建模流程图Fig.5 A schematic diagram of modeling based on spectra data in 8 250~5 779 cm-1 |
对上述4种模型的建模集进行训练, 模型1、 模型2、 模型3和模型4的迭代次数和迭代时间如表1所示, 由表1可知模型4的迭代时间最短, 由于模型1和模型2没有采用小波降维以减少输入规模, 因此迭代时间较长; 而模型1和模型3没有进行预处理消除噪声等, 因此迭代次数较多。 由此可见, 预处理和小波降维对建模效率的提高非常明显。 利用相应模型的预测集进行预测, 预测结果如表2所示。 四种模型预测能力的评价参数选取RMSEP、 相关系数r、 分类正确率, 其中RMSEP越小, r越接近于1, 模型预测效果越好。
| 表1 4种模型的迭代次数和迭代时间 Table 1 Number of iterations and iteration time for the four models |
| 表2 4种BP模型对三种不同水稻品种鉴别的结果 Table 2 Discrimination of three japonica rice varieties by four BP models |
为了验证FD+SG预处理组合对预测结果的影响, 比较模型1和模型2的预测结果, 模型1的RMSEP=0.232 8, r=0.869 5, 对预测集的30个未知样本的识别结果: 垦粳5号(1)识别全部正确, 垦粳6号(2)和绥粳4号(4)的误判数均为1个, 三个品种的分类总体正率只达到93.33%。 在增加了FD+SG预处理后建立的模型2效果较好, 迭代时间缩减至954.5 s, RMSEP减小到0.070 6, r提高至0.988 7, 对预测集的30个未知样本的三个品种的水稻种子分类全部正确, 正确率达100%。 同样, 在进行了FD+SG预处理的模型4的各项指标都优于没有进行FD+SG预处理的模型3。
由此可见, 原始数据经过FD+SG预处理后建立的模型, 模型的预测能力和精度得到了提高, 模型更加稳定可靠。 这是因为光谱数据经过FD预处理后可以消除基线和其他背景干扰, 分辨重叠峰、 提高分辨率和灵敏度, 再经过SG卷积平滑处理后可以消除随机噪声。 FD+SG预处理消除了光谱数据诸多的影响因素, 光谱数据的特征变得更为明显, 经过FD+SG预处理的数据用来建模可以提高模型的预测能力和精确度, 从而提高模型的稳定性和可靠性。 FD+SG预处理对模型的优化在徐文杰的基于近红外光谱技术的淡水鱼品种快速鉴别[13]中有相同效果, 但在林艳的基于近红外光谱技术建立沉香含油量预测模型的研究[14]中FD+SG预处理组合并未提高模型的精度, 因此不同实验对象采用相同的预处理方法优化模型结果可能不一样。
为了验证小波降维对模型预测的有效性, 利用模型1和模型3进行比较, 模型3的迭代时间缩短至模型1的1/19(表1), 迭代速度显著加快, 小波降维减少了神经网络的输入, 极大地降低了数据处理规模, 提高了模型的迭代速度, 这与相关研究在小波变换与神经网络融合法在油页岩近红外光谱分析中的应用得出的结果类似。 小波变换对高维数据降维时保留绝大部分光谱信息, 光谱数据中的大部分无关信息也保留了下来, 因此模型3预测精度比模型1有稍微优化, RMSEP和r值提高不是很明显。
经过上述比较可知: FD+SG预处理能有效提高模型的精度, 小波降维能快速提高模型的迭代速度, 基于这一特点, 在模型2的基础上增加小波降维得到模型4, 模型4的预测效果更好, 迭代时间为98.8 s(表1), RMSEP=0.029 3最小, r=0.998 1最接近于1, 且对30个样本中三个品种的水稻种子样本分类全部正确, 正确率达100%。 即“ FD+SG+小波降维” 的建模方法完全能实现对实验所用的3个品种水稻种子进行快速、 准确分类。
对于小样本分类问题, 支持向量机(support vector machine, SVM)具有良好的分类效果, 为了验证本试验中利用BP建立模型的优势, 对“ FD+SG+小波降维” 的光谱数据建立SVM鉴别模型。 默认线性核函数, 利用网格搜索算法求出SVM建模的最优c值0.062 5和最优g值0.088 4, 建立的SVM模型对预测集的分类结果如表3所示。
| 表3 SVM模型对三种不同水稻品种鉴别的结果 Table 3 Discrimination of three japonica rice varieties by SVM models |
表3表明, 建立的SVM模型对试验中的水稻种子具有良好的鉴别, 模型对3个品种的分类总体正确率为96.7%。 其中对垦粳5号和绥粳4号均能实现100%的鉴别效果, 而对垦粳6号的鉴别正确率为90%, 有一个识别错误。 试验结果表明, 对于本文的研究对象, BP模型对预测集的鉴别效果优于SVM。
以黑龙江垦区粳稻种子定性判别分类为例, 探讨了基于小波变换的近红外光谱数据压缩方法的有效性, 小波变换降维不仅保留了整个光谱数据的绝大部分信息, 而且有效地降低了高维空间数据, 减少了神经网络的输入规模, 简化了神经网络的网络结构, 加快了模型的迭代速度。
研究表明应用近红外光谱分析技术结合小波变换和BP神经网络建立的不同水稻品种鉴别模型具有分类准确、 鉴别速度快、 而且不会破坏样品的特点。 说明利用该方法可以实现准确、 快速、 无损地对不同水稻品种进行鉴别分类, 本方法对基于近红外光谱的其他农产品分类具有一定的指导意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|