

{kind=link}
{kind=link}
基于高阶残差量化的光谱二值编码新方法
[康孝岩1, 2  , 张爱武
, 张爱武1, 2, * ]
, 张爱武]
|
|


作者简介: 康孝岩, 1989年生, 首都师范大学资源环境与旅游学院博士研究生 e-mail: xy.kang@cnu.edu.cn
光谱二值和多值编码技术能够实现目标光谱的快速匹配、 识别和分类等应用, 但这类量化编码方法会损失大量的光谱细节信息, 且不能解码出与原始光谱近似的重构光谱, 应用有限。 为了解决上述问题, 提出一种高阶残差量化的光谱编码新方法HOBC(high-order binary coding)。 首先, 对光谱向量进行去均值的规范化处理, 得到值域为(-1, 1)的光谱序列; 然后, 求解规范化光谱的±1编码、 编码系数和残差(即一阶残差); 基于一阶残差, 逐阶解算2至K阶残差的±1编码及其系数; 最后得到K个编码序列及其系数, 即为HOBC的编码结果。 选择典型波谱库数据集, 对比光谱0/1二值编码BC01(binary coding with 0 and 1)、 光谱分析编码SPAM(spectral analysis manager)、 二值/四值混合编码SDFC(spectral derivative feature coding)和DNA四值编码等4种方法, 进行了光谱量化编码和解码重构实验, 分别统计了光谱形状特征和斜率特征编码的信息熵和存储量、 光谱形状特征编码与原始光谱之间的光谱矢量距离SVD (spectral vector distance)、 谱间Pearson相关系数SCC (spectral correlation coefficient)和光谱角SAM (spectral angle mapping)。 结果表明, 在编码存储量上, HOBC的1~4阶编码分别与以上4种编码相等; 在编码信息熵上, HOBC的1~2阶编码分别与BC01和SPAM相等, 而HOBC的3~4阶编码分别高于SDFC和DNA编码; 在SCC上, HOBC1阶编码与BC01相等, 而2~4阶编码均分别优于SPAM, SDFC和DNA编码; 在SAM方面, HOBC 1~4阶编码均分别明显优于4种对比方法; 4种对比方法不能明确解码重构, 而HOBC可简便重构出与原始光谱近似的解码序列, 且SVD逐阶递减。 进一步, 基于临泽草地试验站公开光谱数据集, 进行了10类地物目标的光谱编码和监督分类实验, 实验结果表明, 在Kappa系数, 总体分类精度和平均分类精度等3种性能评价指标上, HOBC均明显优于4种对比方法, 尤其是, HOBC 4阶编码优于原始光谱的分类性能; 对样本数量较少且类间相似性较高的难分类地物, HOBC亦具有优于其他算法的鲁棒性。 说明HOBC编码在大幅压缩数据量的同时, 其编码序列能保留较高的信息量, 且具有较高的光谱可分性, 可用于光谱高精度快速识别和分类; 其解码重构序列与原始光谱序列具有较高的相似性, 理论上可适用于目标识别和分类等应用。
Spectral binary coding and multivalued coding technology can make objects spectra match, identify, and classify fast; but this kind of quantization coding methods will lose a lot of spectral details, and they cannot decode the reconstructed spectra similar to the original spectra. So they were only used for coarse horizontal applications in the past, such as rough classification. For resolving the above problems, a new spectral coding method, namely, HOBC (High-Order Binary Coding) was proposed based on high-order residual quantization. First, the original spectra were standardized by subtracting their own vector-mean, and thus the spectral sequences with a range of (-1, 1) were obtained. Second, the code with -1 and 1, its coding coefficient, and the residual (i. e., the first order residual) of a normalized spectrum were computed. Third, the binary codes with ±1 and their coding coefficients of the residuals from Two-Order to K-Order were computed order by order. At last, the K coding sequences and their corresponding coefficients were obtained. Using a typical spectral library dataset, spectral quantization encoding and decoding reconstruction experiments were carried out, compared with BC01 (spectral Binary Coding with 0 and 1), SPAM (SPectral Analysis Manager), a binary/quaternary hybrid coding, namely SDFC (Spectral Derivative Feature Coding), and a quaternary coding, namely DNA. During the experiments, first, the information entropy and memory storage of spectral shape feature and slope feature were calculated, respectively. Second, the spectral vector distance (SVD), spectral correlation coefficient (SCC), and spectral angle mapping (SAM) between the spectral shape feature and the original spectrum were calculated. The results of above experiments demonstrate that, on coding memory storage, HOBC 1—4 order encodings are equal to BC01, SPAM, SDFC, and DNA, respectively; on coding information entropy, HOBC 1—2 order encodings are equal to BC01 and SPAM, respectively, but HOBC 3—4 order encodings are higher than SDFC and DNA, respectively; on SCC, HOBC one order encoding is equal to BC01, but HOBC 2—4 order encodings are better than SPAM, SDFC, and DNA, respectively; on SAM, HOBC 1—4 order encodings are superior to the above four methods obviously, respectively; the four methods cannot be explicitly decoded and reconstructed, but it is easy to reconstruct the decoding sequence similar to the original spectrum for HOBC, and the SVDs of the reconstruct spectra are diminishing from a lower order to a higher order. Furthermore, the spectral coding and supervised classification experiments of 10 types of ground objects were carried out on the open spectral dataset of the Linze grassland foci experimental area. Results show that, on the three performance evaluation indices, i. e., Kappa value, overall classification accuracy, and average classification accuracy, HOBC is superior to the four coding methods. Especially, the classification performance of HOBC 4-order encoding is better than that of the original spectra. For the objects difficult to classify with small-sample and high similarity between classes, HOBC is also superior to other methods, and it is more robust. Therefore, first, HOBC can dramatically compress data. Meanwhile, its coding sequence can retain more information and have higher spectral separability, which can be used for fast identification and classification of spectra with high accuracy. At last, its decoding reconstruct data can also be used for the applications of target recognition and classification etc., theoretically, for the high similarity between the reconstruction spectra and original spectra.
作为一种重要的识别信息, 物质的光谱(spectrum, 亦称波谱)特征主要表现为, 当电磁波与物质表面发生相互作用时, 物质在不同谱段上的反射、 热红外辐射、 微波辐射和散射特征等[1]。 光谱测量技术能够精细刻画物质的反射或发射光谱信息, 形成一条连续或若干条分段连续的曲线, 即光谱曲线, 被广泛用于物质检测、 地物探测[1]、 环境监测和天体观测[2]等领域中。 典型物质波谱库的建设对测谱技术的应用具有重要作用, 目前通用的波谱库有美国地质调查局波谱库、 美国约翰霍普金斯大学波谱库等[1]。 在波谱库中, 一种物质的光谱曲线被记录为一组浮点数组成的向量, 辅助数据包括实物照片和谱段描述等元数据。
随着国内外波谱库的建设和完善[1], 尤其是一些大型光谱观测实验数据的陆续发布, 如中国天文光谱观测望远镜已发布700多万条天体光谱曲线[2], 光谱数据的量级将逐渐增加, 以浮点型来存储、 传输和处理光谱数据将会大大增加数据存储和传输的成本及降低处理效率, 前人学者逐渐开发出一些光谱量化编码方法[3, 4, 5, 6]来应对这些问题。 1988年, Mazer等在0~1二值光谱形状(shape)编码BC01 (binary coding with 0 and 1)的基础上, 提出了SPAM (spectral analysis manager)编码方法, 增加了光谱斜率(slope)特征的编码, 一定程度上弥补了BC信息量的不足[3]。 考虑到二值化对光谱细节描述的损失, Chang等在SPAM的基础上, 引入四值编码QC(quaternary coding)对光谱斜率特征进行刻画, 提出了一种BC/QC混合编码方法SDFC(spectral derivative feature coding), 其中, 光谱形状特征以二值编码表示[7]。 近年来, 有关学者提出了一种用于人工DNA计算的编码方式来表征光谱形状特征、 斜率特征、 振幅(amplitude)特征以及梯度(gradient)特征等[4, 5, 8, 9]; 实际上, DNA编码是一种纯四值编码方式, 即所有光谱特征均以四值表示。
与浮点型原始数值相比, 上述光谱编码方式的优势在于其大幅降低了数据存储和传输成本, 并且有效提高了运算效率; 缺点在于①损失掉了大量信息, 仅可用于粗匹配和粗分类等业务, 如BC编码, ②与BC相比, QC在成倍增加编码长度的同时, 也成倍增加了存储量, ③缺失有效解码方式。 与BC01不同, 深度神经网络学者Bengio所领导的团队提出以± 1二值编码(+1 or -1 binary coding, BC± 1)对网络中的权重进行压缩编码; 在此基础上, Rastegari等将BC± 1推广至卷积层的样本编码, 提出了一种仅依赖异或门逻辑运算即可实现的XNOR-net(eXclusive NOR network), 实现了网络的大幅压缩和快速运算, 但与使用浮点型网络相比, XNOR-net精度有所降低; 基于此, 2017年, Li等提出了一种高阶残差量化加速模型HORQ(high-order residual quantization), 与XNOR-net相比, HORQ-net对兼顾了BC± 1编码压缩和算法精度的高性能[10]。
日臻完善的通用和专业型波谱库的建设发布[1]以及海量光谱数据的采集[2]带来了光谱数据存储、 传输和分析性能提升的需求。 当前, 基于HORQ的BC± 1编码主要用于普通RGB图片的空间维数据的量化压缩; 而工作主要: 尝试将HORQ空间维量化方法引入到光谱分析中, 提出一种光谱高阶二值编码方法HOBC(high-order binary coding), ①基于典型光谱数据集, 对比BC, SPAM, SDFC和DNA等编码方式, 验证HOBC在光谱量化与光谱重构等应用中的优势; ②通过多目标光谱分类实验, 对比验证HOBC在光谱分类应用中的算法性能优劣。
首先简单介绍BC01, SPAM, SDFC和DNA等4种对比方法; 然后介绍HORQ网络编码方法, 并提出HOBC光谱编码与解码流程。
为了满足特定目标光谱与波谱库中已有物质的快速匹配需求, 可将浮点型光谱数据用1比特(bit)的0~1序列来表示[3], 即
式(1)中, x(n)为目标光谱曲线在第n通道(Channel, 亦称波段, Band)的反射率(0, 1), N为通道总数; T为阈值, 一般选为光谱反射率均值。
BC01编码下不同物质的光谱可分性较差, 一般用于光谱粗匹配和粗分类等任务。
作为一种典型的硬阈值编码, BC01对光谱曲线形状特征进行了粗略表示; 在此基础上, SPAM引入了光谱斜率信息来弥补BC01编码信息的损失。 形式上, SPAM编码由两部分码链组成, 即SPAM={SPAMshape, SPAMslope}, 其中前者与BC01编码相同, 后者的定义如下
式(2)中参数与式(1)相同。 显然, SPAMslope码链长度为N-2, SPAM码长近为BC01的两倍; 但两者在存储方面均仅需1 bit。
Chang等参考空间纹理特征编码方法[11], 提出了一种光谱斜率特征的四值编码方法SDFCslope[7]。 通过比较光谱曲线上某波段反射率[x(n)]与前后相邻波段[x(n+1), x(n-1)]的差异程度来定义其斜率特征为如下4种类型之一
式(3)中, Δ 为光谱反射率变化的容限度, 当相邻光谱值变化小于该值时, 认为无变化, 其定义如式(4)
式(4)中各参数与式(3)相同。 那么对于SDFCslope的编码如式(5)
基于此, Chang等提出了一种BC-QC混合方法SDFC={SDFCshape, SDFCslope}, 其中前者与BC01编码相同。 与SPAM相比, SDFC的码链长度也为2N-2, 形状和斜率特征分别以1和2 bits数值存储, 或全存为2 bits数值, 这将使光谱存储量翻倍。
DNA编码是一种纯QC方式, 其对光谱斜率的编码方式与SDFC相同, 并借鉴QC来对光谱形状进行编码[4, 5, 8], 即DNA={DNAshape, DNAslope}, 其中, DNAslope与SDFCslope相同; 而DNAshape需首先将光谱数据以3个阈值划分为4个区间, 然后依次编码为00, 01, 10和11。 光谱DNA码链长度也为2N-2, 并且均为2 bits的四进制数值。
与其他4种编码方式不同, XNOR和HORQ采用± 1码字。 对于N维实向量X∈ RN, 假设可将其量化近似为X≈ β 1H1, 其中, β 1∈ R, β 1> 0, H1∈ {+1, -1}N, XNOR-net使用最小二乘估计最小化X-β 1H1的l2范数, 即通过式(6)求解β 1和H1
可得解析解为(详细求解过程见文献[10])
式(7)中, sign(X)为X的符号函数, x(n)∈ X, 当x(n)≥ 0时, sign(x(n))=+1; 当x(n)< 0时, sign(x(n))=-1。
以上即为XNOR-net的向量量化编码过程, 基于此, Li等定义了X的一阶残差为
并认为前人的二值量化方法忽略了残差信息, 而使得网络训练模型精度不高; 进而提出了X的高阶残差量化近似的编码方式
式(9)中,
如此, 通过式(10)的K阶残差量化, 可将X近似编码为K个{-1, +1}N向量。 在此基础上, Li等重点研究了二阶残差量化网络在手写字体(MNIST)和普适物体(CIFAR-10)的识别应用, 发现二阶HORQ-net比XNOR-net降低了50%以上的误差, 同时网络加速为非量化网络的30倍[10]。 在形式上, 一阶残差量化编码即XNOR-net, 与BC01编码相似, 如表1所示。
| 表1 光谱编码方法概况 Table 1 Overviews of spectral coding methods |
在编码存储空间大小上, BC01, SPAM, SDFC和DNA四种编码分别与HORQ的一阶至四阶残差编码相当。
当前, HORQ主要用于计算机视觉领域的图像空间维数值量化编码, 通过误差反向传播的迭代调参来提升网络精度; 其应用重点在于网络压缩(编码), 而非数据重构(解码)[10]。 数据编码压缩学者美国Nebraska大学教授Khalid认为, 数据压缩是一门实验科学, 适用于文本压缩的方法不一定适用于图像, 一种方法之所以能适用于某个特定应用, 很大程度上取决于数据的特定结构[12]。 基于此, 尝试将HORQ引入到光谱分析中, 提出一种光谱高阶二值量化方法HOBC, 其主要分为如下的编码和解码两部分:

从式(9)— 式(10)和伪代码可知, HOBC的高阶编码可以解码低阶序列, 如4阶编码可以分别重构出1~4阶的解码序列。
鉴于光谱反射率取值在区间[0, 1], 为避免一阶量化表示全部取+1码字, 本研究对原始光谱序列进行去均值处理, 以精简量化阶数。 为与四种典型方法比较, 设定HOBC编码阶数为4阶, 1~4阶解码分别对应于BC01, SPAM, SDFC和DNA编码。
为定量探究光谱高阶二值量化编码的特性, 首先采用典型光谱库的光谱数据, 对比经典方法来验证本方法HOBC在光谱量化编码与光谱近似等方面的优劣; 其次, 选用第三方多目标光谱数据, 通过监督分类, 比较不同量化编码算法的分类性能。
从通用型波谱库中选择典型光谱进行实验, 数据为ENVI软件自带的美国地质调查局波谱库(第6版)矿物光谱(minerals_nicolet_4024), 测量仪器为Nicolet光谱仪, 波谱范围为1.28~216 μ m, 波段数为4 024个, 共有185条光谱。
对实验光谱分别进行了BC01, SPAM, SDFC, DNA和HOBC的编码, 统计了各编码方法中光谱形状特征和光谱斜率特征的信息熵(Entropy)和存储量(Memory)[12], 光谱形状特征与原始光谱序列之间的光谱矢量距离(spectral vector distance, SVD)、 谱间Pearson线性相关系数(spectral correlation coefficient, SCC)和光谱角(spectral angle mapping, SAM)[16]等, 如表2所示。
| 表2 不同编码方法对典型光谱的编码性能比较 Table 2 Coding performance comparison of different encoding methods for typical spectra |
结合表2和表1可知, ①HOBC可逐阶逼近原始光谱, 在与原始光谱的共变趋势上, 明显优于其他四种编码: HOBC的SVD呈现逐阶递减趋势, 3阶编码的SCC已达0.97以上, 其SAM的余弦值为0.996; BC01的SCC与HOBC1阶相等, 但其SAM远高于HOBC1阶; SPAM的SCC明显低于HOBC2阶, 且其SAM远高于HOBC2阶; SDFC和DNA的情况与SPAM类似。 ②HOBC的1~4阶编码存储量分别与BC01, SPAM, SDFC和DNA相当: BC01, SPAM, SDFC和DNA编码过程中产生1到4个数量不等的阈值, 但并不能用于其解码, 故原算法中并未加以存储; 而HOBC具有明确的解码重构方法, 存储了辅助数据(K+1个, 1个光谱均值Ave和K个编码系数β KO), 因此, 在不考虑解码的情况下, 1~4阶HOBC存储量分别与对应的四种编码相等。 此外, 各方法的编码特征不同: BC01和HOBC仅对形状特征进行编码; 而其他三种对形状和斜率均进行编码。 以实验数据集中的阳起石(Actinolite HS22.3B)光谱为例, 各方法的编码结果如图1(a— i)。
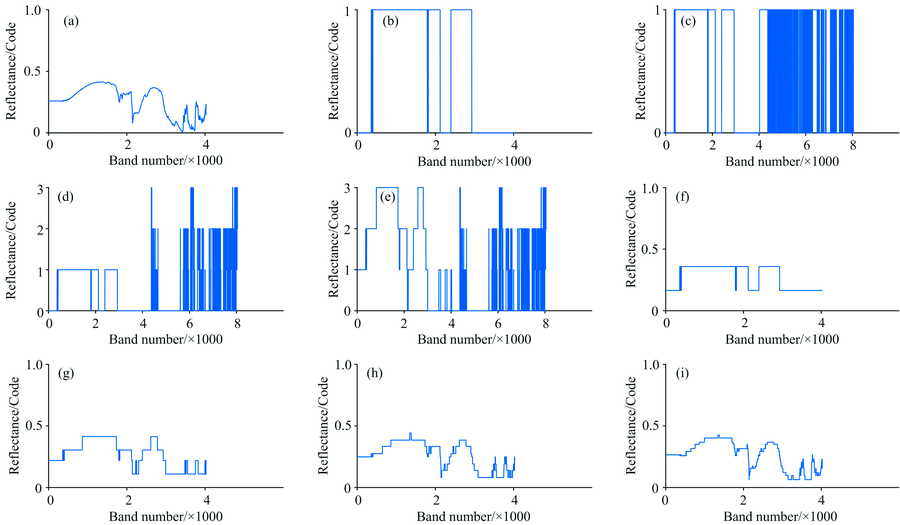 | 图1 各编码方法对阳起石光谱的编码/解码比较(a): 原始光谱; (b): BC01; (c): SPAM; (d): SDFC; (e): DNA; (f): HOBC 1阶; (g): HOBC 2阶; (h): HOBC 3阶; (i): HOBC 4阶Fig.1 Encoding/Decoding comparison of different coding methods for the spectrum of Actinolite HS22.3B(a): Original spectrum; (b): BC01 coding; (c): SPAM coding; (d): SDFC coding; (e): DNA coding; (f): HOBC 1-order decoding; (g): HOBC 2-order decoding; (h): HOBC 3-order decoding; (i): HOBC 4-order decoding |
从编码的目视效果上看, ①HOBC逐阶解码的重构序列与原始光谱之间的近似程度越来越高[图1(f— i)], 尤其在反射率变化较大的邻近波段, 3和4阶解码均有对应的相似表示, 如第2 000波段前后(2.53 μ m, 近红外与中红外谱段交接处)和第4 000波段左侧(108 μ m, 超远红外谱段), 这些细节在其他编码方式中未见反映。 ②SPAM, SDFC和DNA中, 1— 4024为其形状特征编码, 4025— 8046为其对斜率特征的编码; 就形状特征而言, 与BC01[图1(b— d)]相比, DNA四值编码[图1(e)]虽显示出一些波形细节, 但与原始光谱仍有较大差异; 就斜率特征而言, 四值编码[图1(d, e)]比二值编码[图1(c)]多出一些细节信息, 但其作用需在具体应用中加以验证。
2.1节探讨了HOBC与四种对比方法在光谱编码与重构近似方面的特性, 本节将研究各编码方法下目标分类的性能优劣。 研究选择第三方公开数据集[13]作为样例, 观测仪器为ASD FS3光谱仪, 光谱分辨率为3 nm@350~1 000 nm, 10 nm@1 000~2 500 nm, 样例中共有10种地物[图2(a— k)], 光谱范围为350~2 500 nm, 光谱数据间隔为1 nm, 除去噪声谱段(1 350~1 420和1 800~1 975 nm)后, 剩余1 904个波段。
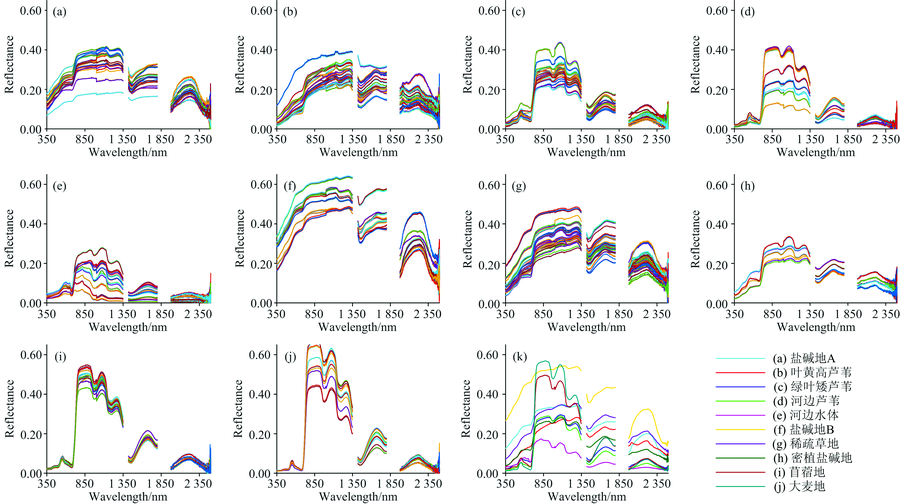 | 图2 临泽草地加密观测区地物光谱观测数据集(a): 盐碱地A; (b): 叶黄高芦苇; (c): 绿叶矮芦苇; (d): 河边芦苇; (e): 河边水体; (f): 盐碱地B; (g): 稀疏草地; (h): 密植盐碱地; (i): 苜蓿地; (j): 大麦地; (k): 地物光谱均值Fig.2 Dataset of spectral reflectance observations in the Linze grassland foci experimental area(a): Saline-alkali soil A; (b): Tall reeds with yellow leaves; (c): Low reeds with green leaves; (d): Reeds by riverside; (e): Water by riverside; (f): Saline-alkali soil B; (g): Sparse grassland; (h): Densely planted saline alkali soil; (i): Alfalfa fields; (j): Barley land; (k): The mean spectra of each kind of object above mentioned |
对10种地物的每条光谱分别进行四种对比方法和HOBC 1— 4阶的编码, 为了与BC01等方法进行客观比较, HOBC在本实验中仅使用编码, 而非解码重构光谱, 如HOBC2阶编码为长度2N的± 1序列。 分类器选择为随机森林(random forest), 决策树数量为100; 对每种地物的光谱随机选择30%作为训练, 其余光谱用于测试, 分类性能指标有Kappa系数, 总体精度(overall accuracy, OA)和平均分类精度AA(average accuracy); 分类实验独立进行100次, 取平均值作为最终结果(表3)。
| 表3 不同编码方法下地物分类精度统计 Table 3 Classification accuracies for different encoding methods |
统计结果表明了本文方法HOBC在地物光谱分类上的优势, HOBC 1— 2阶分别与编码存储量相等的BC01和SPAM达到相似的分类精度; 而HOBC 3— 4阶编码则明显高于SDFC和DNA编码, 亦高于SPAM和BC01。 从各类地物分类细节上看, 密植盐碱地的分类精度较低, 包括原始光谱在内, SPAM, SDFC和DNA三种方法对该类的分类精度均低于50%; 其次是河边芦苇一类, 考虑到另有两种芦苇地类, 且河边芦苇的样本相对较少, 故而其分类精度较低, 尤其是BC01, SPAM及SDFC三种编码均低于30%的正确率, 而使得它们的总体和平均分类性能下降。 而在这两类地物上, HOBC均保持了相对较高的分类精度, 鲁棒性较高, 尤其对密植盐碱地, HOBC各阶编码的分类精度甚至高于原始光谱。
引入空间维数据量化方法HORQ, 提出了一种高阶残差光谱编码方法HOBC。 光谱编码与近似的实验结果表明, 与其他4种算法相比, 在保持与之相当的压缩水平下, HOBC能够简便解码重构出与原始光谱近似的解码序列(4阶重构序列与原始光谱的光谱矢量距离小于0.02, 相关系数可达0.98以上, 光谱角小于2.6° ), 远优于对比方法; 多目标地物光谱分类的实验表明, 与其他算法相比, HOBC编码具有最优的光谱分类性能, 且有着较高的鲁棒性。
HOBC方法侧重于光谱向量的量化编码, 实验结果表明了其在光谱量化和光谱分类应用中的适用性和鲁棒性。 与光谱曲线数据相比, 高光谱图像兼顾光谱与空间结构信息, 其量化编码的基本单元可为光谱向量, 可为单个波段, 亦可为光谱/波段混合编码, 即其编码策略并无唯一, 相对复杂。 在下一步的研究工作中, 将系统地探究高光谱影像数据的高残差量化方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|