






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
数据驱动模型的血液物种光谱检测技术
[李宏霄1  , 孙美秀
, 孙美秀1 , 向志光2 , 汪毅3 , 林凌3 , 秦川2 , 李迎新1, * ]
, 孙美秀]
|
|


作者简介: 李宏霄, 1986年生, 中国医学科学院生物医学工程研究所助理研究员 e-mail: tjlhx253@126.com
介绍一种基于光谱检测和数据驱动模型的非接触式血液物种识别技术。 选取了4个物种(猴144, 大鼠203, 狗133, 人169)共计649个血样作为原始样本。 超连续谱激光光源的波长范围是450~2 400 nm。 分别采集抗凝管盛装血液样本的后向散射可见光谱(294~1 160 nm)和十个不同空间位点的前向散射近红外光谱(1 021~1 757 nm), 将十一条光谱数据顺序连接为一维数据作为每个样本的原始数据。 利用主成分分析法对数据集进行特征信息提取, 保留原始差异信息量的99.99%, 同时将数据量压缩为原始数据量的1.5%, 提高分类识别的运算效率。 对不同数量的训练集和验证集进行训练预测实验表明, 十折交叉验证的识别误差率随着样本数量的增加而降低, 样本库规模的增大可以提高识别的精确度。 由于数据驱动模型是基于机器学习算法的数据流处理模型, 因而可以采用多种不同的分类算法实现。 通过比较人工神经网络、 支持向量机、 偏最小二乘回归、 多元线性回归、 随机森林和朴素贝叶斯的识别效果可以发现, 不同算法的识别效果具有类别差异性, 即各个算法的正确识别率排序在不同的物种中是有差异的。 因而实际应用中, 在选择数据驱动模型时, 除了需要考虑算法的整体识别率之外, 当对部分类别的识别效果有额外要求时, 还应该考虑算法本身的类别差异性。
This paper proposed a non-contact blood species recognition technique based on spectral detection and data driven model. A total of 649 blood samples were selected from 4 species (monkey 144, rat 203, dog 133, and human 169) as the original samples. The wavelength range of the super continuum laser source was 450~2 400 nm. The backward scattered visible spectrum (294~1 160 nm) and the forward scattered near-infrared spectra of ten different spatial sites were collected from each blood sample contained in anticoagulant tubes. Then the eleven spectra were sequentially connected into one-dimensional data as the original data of each sample. The principal component analysis was used to extract the feature information of the dataset, which retained 99.99% of the original variance information, while compressing the data amount to 1.5% of the original data volume, such to improve the computational efficiency of classification and recognition. Experiments on different numbers of training sets and verification sets showed that the recognition error rate of ten-fold cross-validation decreases with the increase of the number of samples, and the increase of sample bank size can improve the recognition accuracy. Because the data driven model is a data stream processing model based on machine learning algorithms, in which a variety of different classification algorithms can be used to realize this model. By comparing the recognition effects of six algorithms (artificial neural network, support vector machine, partial least-squares regression, multiple linear regression, random forest and Naïve Bayes), it was found that the recognition effects of different algorithms have the category differences, that is, the sort of these algorithms in terms of their correct recognition rate are different for different species. Therefore, when choosing the data driven model as a solution, in addition to considering the overall recognition rate of the algorithm, the scheme should also consider the category differences of the algorithm if there are additional requirements on the recognition effect of some certain categories.
随着中国医药行业的飞速发展, 血液生物材料的出入国境需求日益增加。 目前海关对血液来源物种的判断依据有两方面, 其一是申报人提供的血样信息, 其二是检测机构提供的检验结果; 前者的信息真实性难以保证, 后者的检验过程耗时繁多, 且血液样品可能被检测操作污染, 或者血液样品自身可能携带致病因子, 对检测人员造成职业暴露。 因此, 有必要引入光谱检测法以实现对血液物种的非接触式鉴别。
20世纪70年代, 美国杜克大学的Frans F. Jö bsis[1]首次提出了将血液的近红外光谱用于血液成分含量检测的设想, 此后, 世界各国的研究人员纷纷展开了对血液光谱的分析研究, 旨在通过血液光谱分析法检测血液中多种成分的含量[2, 3, 4, 5]。 随着光谱分析技术的进一步发展, 在临床化学等领域该技术还被用于快速生物医学诊断的研究[6]。
通过分析现有研究进展可以发现, 光谱技术在血液相关的研究工作中主要用于检测血液成分含量, 其基本研究思路为: 首先, 采集血液的红外光谱, 并利用生化法测量血液中目标成分的含量, 作为标准含量数据; 然后, 利用统计分析方法构建血液光谱数据与标准含量数据之间的关联数学模型; 最后, 利用该模型和血液光谱数据预测血液中目标成分的含量, 实现非接触式的血液成分含量检测。 常用的统计分析方法有: 偏最小二乘回归(partial least square regression, PLSR)和多元线性回归(multiple linear regression, MLR)等, 随着机器学习理论的发展, 越来越多机器学习领域的算法被引入光谱预测模型的构建中, 例如人工神经网络(artificial neural network, ANN)[3]和支持向量机(support vector machine, SVM)[7]等。
上述内容表明, 光谱法可以定量地分析血液中的生化成分, 这是使用光谱法检测血样物种的技术理论基础, 而使用光谱法检测血样物种的生物学基础则是不同物种之间的血液差异。 物种是生物界发展的连续性与间断性统一的基本间断形式, 在有性生物中, 物种呈现为统一的繁殖群体, 由占有一定空间, 具有实际或潜在繁殖能力的种群所组成, 而且与其他这样的群体在生殖上是隔离的[8]。 研究表明, 不同物种的血液成分含量有显著差异[9, 10]。
综上所述, 利用光谱技术检测血液物种的理论基础是完备的。 在此将依次介绍血样物种识别的数据驱动理论模型、 光谱检测设备和数据实验结果, 最后对本研究进行总结。
由于光谱技术可以检测血液成分含量, 而不同物种的血液成分又具有显著差异, 因此, 可以在此理论基础上设计一个血液物种识别的逻辑模型, 如图1所示。 在逻辑模型中, 每一种血液成分都会建立一个光谱预测模型, 通过这些光谱预测模型可以预测得到所有血液成分的含量, 然后根据血液成分含量的差异性区分血液物种类别。
 | 图1 血液物种检测的逻辑推理模型Fig.1 Logical model for blood species detection |
血液中的成分种类非常多, 如果要辨别不同血液物种类别的有效成分, 最好的方法就是将所有可能性都试验一遍, 其中包括所有的血液成分和所有需要分辨的物种类别的不同组合, 但是, 这种方法的实现困难很大。
受到近年来飞速发展的机器学习和人工智能技术的启发, 考虑用一个黑箱来替换逻辑模型中的血液成分含量建模过程, 形成一个如图2所示的数据驱动模型, 也就是说依靠光谱数据来驱动黑箱的模型生成过程。 黑箱中包含了一种从血液光谱到血液物种类别的对应关系, 显而易见, 这种关系是非线性的, 数据驱动模型的目的就是通过数据驱动来拟合逼近这种非线性关系, 从而构建一个从血液光谱到血液物种类别的预测模型。 由于人工神经网络在理论上可以无限逼近任意的非线性连续函数[11], 首先选择人工神经网络作为数据驱动模型的实现算法, 该算法可以看作是数据驱动模型中的驱动装置。
 | 图2 血液物种检测的数据驱动模型Fig.2 Data driven model for blood species detection |
由于海关出入境的血液制品通常存放于抗凝管中, 所以本研究考虑的检测对象为抗凝管中的血样。 为了能够同时检测血样的前向和后向散射光谱信息, 设计了如图3所示的样品夹持装置。
其中, 盛放血样的抗凝管位于一个半封闭的腔体内, 以便隔绝干扰光源, 腔体的两侧分别设计了对称的窗孔, 用于插入光纤, 其中一根光纤连接到宽带激光器上, 作为光源的接入端口, 另外两根光纤连接到光谱仪上, 作为散射光的导出端口。
为了提高光谱数据的稳定性和抗噪性能, 并获取更多的血样光谱信息, 我们将一个光纤探头安装在一个超精密电动位移平台上, 由该平台带动光纤探头在竖直方向移动可以获得抗凝管中血样在管轴方向上多个位置的光谱数据。
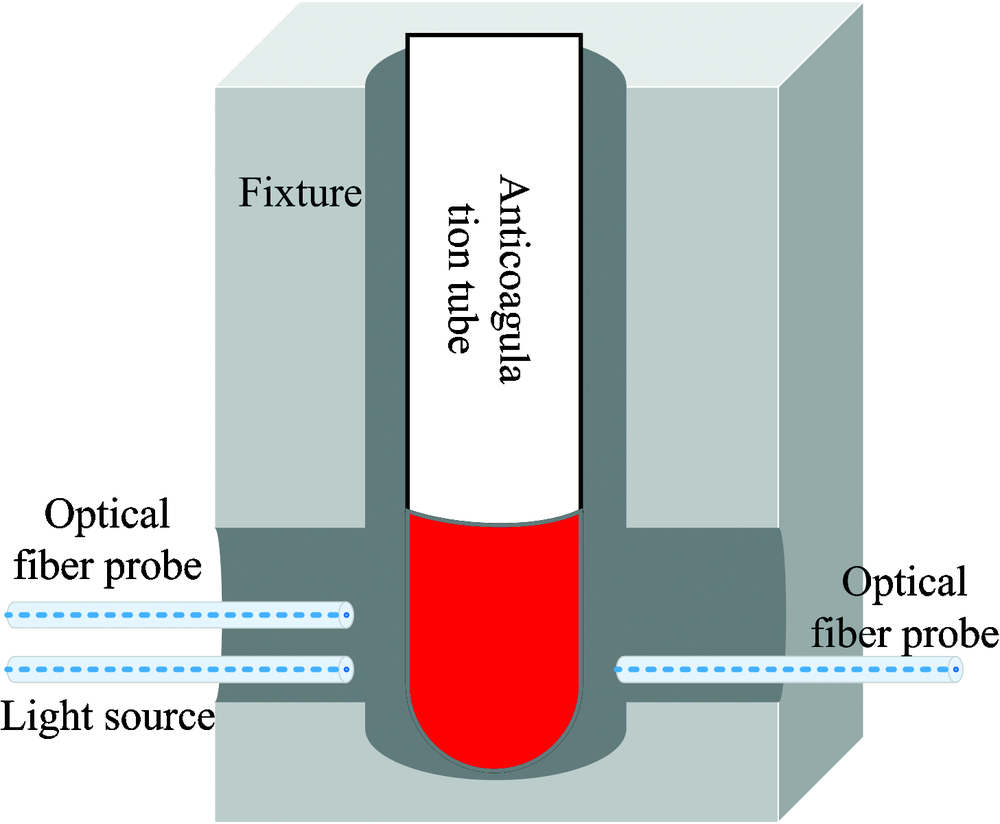 | 图3 样品夹持装置示意图Fig.3 Schematic diagram of sample clamping device |
检测装置采用的宽带激光光源为武汉安扬激光技术有限责任公司生产的超连续谱光源SC-5-FC, 波长范围450~2 400 nm, 光谱数据采集装置是北京爱万提斯科技有限公司的可见光谱仪AvaSpec-HS1024x58TEC-USB2, 光谱检测范围294~1 160 nm, 均匀采集952个不同波长的数据点, 和红外光谱仪AvaSpec-NIR256-1.7(TEC), 光谱检测范围1 021~1 757 nm, 均匀采集255个不同波长的数据点。
由于生物组织对近红外光的吸收和散射比可见光弱, 因此, 在后向散射固定位置采集可见光谱, 前向散射可移动位置采集10个不同位点的近红外光谱, 相邻位点间隔0.381 mm。 光源功率为240 mW, 可见光谱仪积分时间1 000 ms, 红外光谱仪积分时间50 ms。
实验使用的4个物种(猴144, 大鼠203, 狗133, 人169)共计649个血样, 由中国医学科学院医学实验动物研究所提供, 血样存放于VACUETTE 5ml EDTA K3采血管中。
每个血样的光谱数据包含一条可见光谱数据和10条红外光谱数据。 为了方便后续处理, 将这11条光谱数据按照可见到红外的顺序依次串联成一条一维数据, 包含3502个光谱变量。 首先, 对光谱数据进行归一化预处理, 然后, 利用主成分分析对光谱数据进行降维处理, 保留变量数量的1.5%作为主成分(累积差异信息量大于99.99%), 之后, 利用数据驱动模型, 以预处理后的训练数据为材料, 学习得到血样物种的识别模型。
实验用十折交叉验证来评价数据驱动模型的效果。 十折交叉验证会将数据集随机分成等量的10个子数据集, 然后做10次模型训练及模型验证实验, 每次实验选出1个子数据集作为验证数据集, 其余9个子数据集作为训练数据集, 10次实验即可将所有的子数据集作为验证集遍历一次, 将所有子数据集中验证识别错误的样本数量记为NErr, 设总样本数量为NTotal, 则该十折交叉验证实验的识别误差率为
数据驱动模型的基础是数据, 因此首先探讨数据量对识别效果的影响。 实验设定为: 基于649个样本数据, 设计一个数据群组, 其中包含7个数据集, 各数据集包含的样本数分别为100, 200, 300, 400, 500, 600, 649, 这些数据集都是从649样本中随机抽取得到。 为了排除随机抽样的偶然性因素对结果的影响, 按照上述方法, 以不同的随机数生成器再准备9个相同规格的数据群组。
对上述所有的70个数据集进行十折交叉验证, 数据驱动模型中选用的驱动算法是人工神经网络算法, 采用网格搜索法选取最优参数。 图4所示为十组不同样本量数据集的十折交叉验证误差率均值及其标准差。 图4表明, 随着样本集中样本数量的增加, 数据驱动模型的十折交叉验证误差率会随之下降, 该结果与数据驱动模型的特点是吻合的, 因为, 样本量增加则意味着数据量的增加, 从而使得数据驱动模型对样本总体空间特征的覆盖范围更广, 则相应的识别误差率也会更小。 该结果表明, 本文提出的数据驱动模型是有效的。
此外, 从图4中还可以发现, 随着样本量的增加, 误差率的标准差也在逐渐变小, 这主要是由于数据集的生成方式为随机抽取而导致的。 以样本量为100的数据集(简称为100数据集)为例, 十组数据群组中的100数据集是以完全不同的随机数生成器从649个样本中抽取出来的, 因此, 这十个100数据集的交集是较小的, 但是当样本量变成200甚至更大的时候, 则十个200数据集或者样本量更大的数据集之间的交集就会变大, 直至最后, 十个649样本集内的样本是完全相同的, 只是排列顺序不同。 显然, 十组样本集之间的交集越大, 则各个样本集的识别误差率之间的差异也会越小。
 | 图4 十折交叉验证误差率随样本数增加而下降Fig.4 The ten fold cross validation error rate decreases with the increase of sample size |
与人工神经网络类似的可以拟合非线性关系的算法还有很多, 在工程实践中较为常用的有: 支持向量机, 偏最小二乘回归, 多元线性回归, 随机森林(random forest, RF)和朴素贝叶斯(Naive Bayes, NB)等[12]。 这些算法虽然没有完备的数学理论证明其效能, 但是在广泛的工程实践中都有出色的表现。 因此, 采用上述五种算法作为数据驱动模型的实现算法进行了实验, 对比分析各种算法的效果。 其中, 各个算法均采用网格搜索法选取最优参数, 实验数据与3.2节的设定相同, 评价指标按3.1节的设定。
从图5和图6可以看出, 在识别精准度方面, ANN, PLSR和SVM处于第一梯队, RF和MLR处于第二梯队, NB则不适合该应用场合。 在训练耗时的比较中, SVM表现出众, 这得益于SVM只需要寻找少量支持向量即可构建模型的特征, 这一特点在大规模数据挖掘应用中尤其突出; 而ANN需要对多个节点及权重进行多次迭代计算, 因此训练耗时支出远超其他算法。 在测试耗时的比较中, 第一和第二梯队中各种算法的表现基本相当。 因此, 当模型建好后, 预测耗时因素对算法选择的影响较小。
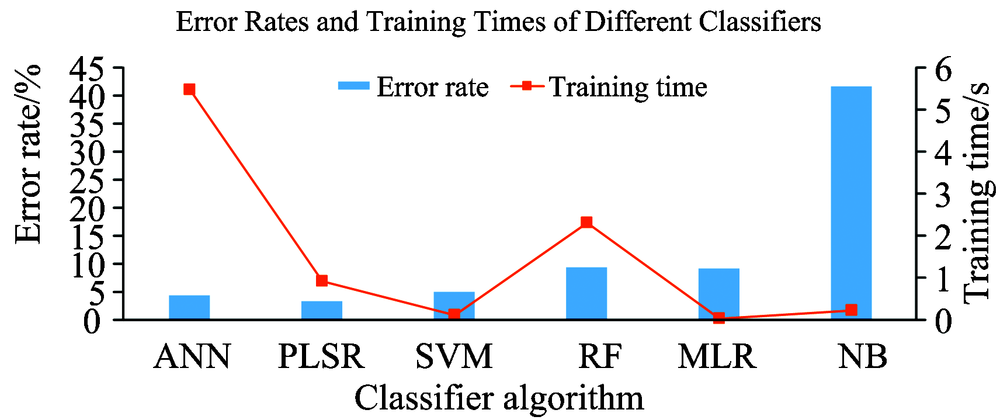 | 图5 不同分类器算法的误差率和训练耗时综合对比Fig.5 Comprehensive comparison of error rates and training times for different classifier algorithms |
 | 图6 不同分类器算法的误差率和测试耗时综合对比Fig.6 Comprehensive comparison of error rates and testing times for different classifier algorithms |
在图7中展示了第一梯队三种算法对649样本集进行十折交叉验证的预测结果中各个物种类别被正确识别的数量。 图6显示PLSR的总体误差率最小, 但是从图7可以发现, PLSR并非在所有物种类别上的误差率都是最小的。 如图7所示, 在rat和human两个类别中, ANN正确识别的数量是高于PLSR的。 这表明, 不同算法的识别效果具有类别差异性, 即某一算法对某一类样本有高于对全体样本整体识别准确率的表现。 因此, 在实际应用中, 当我们要求在兼顾样本整体识别率的同时, 又希望识别模型能够对人类血样具有更高的识别准确率时, 就需要比较多种算法的效果并进行类别特异性选择。
 | 图7 三种分类器算法对各个物种正确识别数量的对比Fig.7 Comparison of correct identification numbers of three classifier algorithms for each species |
介绍了一套基于光谱技术的非接触式识别血样物种的装置及其算法模型。 该装置采集抗凝管盛装血样的前向散射红外光谱和后向散射可见光谱, 然后根据提出的数据驱动模型, 利用多种分类算法构建了基于光谱的血液物种识别模型。 实验结果表明, 数据量的增加可以降低十折交叉验证的识别误差率, 这是数据驱动模型的一个特征, 因为数据量的增加意味着有效信息量的增加, 因而可以提高模型的识别性能。 这个结果也同时表明, 数据驱动模型能够有效解决该识别问题, 并具有进一步提升的潜力。 在数据驱动模型中使用不同的分类算法, 在识别误差率、 训练耗时、 预测耗时等方面比较了多种算法的表现。 此外, 还具体分析了三种识别能力较高的算法对每个物种类别的识别效果。 结果表明, 总体误差率的差异不会平均表现在每个物种类别上, 具体到单个类别上, 不同算法的识别效果与总体识别误差率表现出来的结果有差异。 因此在实际应用中, 需要根据具体需要选择合适的算法实现数据驱动模型。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|