

{kind=link}
{kind=link}
{kind=link}
基于变量优选和ELM算法的土壤含水量预测研究
[蔡亮红1, 2  , 丁建丽
, 丁建丽1, 2, * ]
, 丁建丽]
|
|


作者简介: 蔡亮红, 1991年生, 新疆大学资源与环境科学学院硕士研究生 e-mail: 1173716776@qq.com
土壤水分含量(SMC)的快速估测对干旱半干旱地区的精准农业发展具有重要的意义。 以渭干河-库车河绿洲为靶区, 采用小波变换(WT)对反射光谱进行1~8层小波分解, 通过相关性分析确定最大分解层数, 再通过竞争性自适应重加权(CRAS)、 连续投影算法(SPA)和CARS-SPA耦合算法进行特征波长筛选。 基于全波段构建BP神经网络模型和基于特征波长构建BP神经网络、 支持向量机、 随机森林和极限学习机模型, 并进行对比分析。 结果显示: (1)随着小波分解的进行, 总体上L6在去噪的同时还尽可能的保留了光谱原始特征, 为最大分解层; (2)小波变换和CARS-SPA算法的结合使其在建立模型时较为彻底的去除噪声和无信息变量, 同时消除变量间的共线性; (3)在所有的SMC预测模型中, 相对于BP神经网络、 SVM, ELM和RF具有更好的预测能力, 其中L6-CARS-SPA-ELM精度最高, 其RMSEC=0.015 1,
The rapid estimation of soil moisture content (SMC) is of great significance to precision agriculture in arid areas, and hyperspectral remote sensing technology had been widely used in the estimation of soil moisture content due to its non-destructive, rapid, and high spectral resolution characteristics. Meanwhile, there are many prediction models of soil moisture content, such as BP, SVM, RF and so on, but the prediction model has some shortcomings. Recently, the extreme learning machine(ELM) as a new algorithm began to emerge in the field of soil property prediction. In the present study, a total of 39 soil samples at 0~20 cm depth were collected from delta oasis in Weigan-Kuqain, Xinjiang Province. We brought back to the laboratory to dry it naturally, groundnd and passed through a 2 mm hole scree, and then the sample holders were clear black boxs in 12 cm diameter and 1.8 cm deep, which were filled and leveled at the rim with a spatula. Reflectance of soil samples were measured using ASD Fieldspec 3 Spectrometer in a dark room. We used the following steps to process soil reflectance: First, discrete wavelet transformation (DWT) was used to decompose the original spectral in 8 levels using db4 wavelet basis by MATLAB programming language. In order to select the maximum level of DWT, correlation coefficients between SMC and the spectra of each level was computed. Secondly, On the basis of wavelet transform, CARS (the adaptive variable weighting algorithm), SPA (successive projections algorithm) and CARS-SPA were used to filter the redundant variables, the wavelength variables with better correlation with SMC were screened out. Thirdly, On the basis of the preferred wavelengths, BP neural network, SVM (support vector machine), RF (random forest) and ELM (extreme learning machine) prediction models were employed to build the hyperspectral estimation models of SMC, and the advantages and disadvantages of the model were further analyzed. Statistical parameters of root mean square error of calibration (RMSEC), determination coefficient of calibration (
土壤水分含量(soil moisture content, SMC)是土壤系统中物质和能量循环的载体, 对土壤特性、 植被生长分布以及区域生态系统有着重要的影响[1, 2]。 然而, 土壤水分非常容易受环境的影响, 并且SMC传统的监测方法由于费时费力, 难以用于田间尺度和满足精准农业的要求[3], 因此, SMC的监测需要一种高效、 精准的方法。 近年来, 高光谱遥感技术以其大面积、 非接触、 时效性等优势, 在SMC的监测研究中得到重视[4]。 然而, 通过高光谱技术所获取的土壤光谱原始数据存在明显的光谱噪声和严重的散射现象, 土壤高光谱中必然存在与SMC不相关的噪声[5], 这将会增加SMC的探测难度, 再加上高光谱本身的海量数据, 因此, 较为彻底的去噪和变量优选成为建立精度较高模型的关键。
研究以渭库-绿洲土壤样品为研究对象, 基于小波变换(wavelet transform, WT)对反射光谱进行分解, 并根据各层特征光谱与SMC之间的相关关系来确定最大分解尺度, 在此基础上引入竞争性自适应重加权(competitive adaptive reweighted sampling, CRAS)、 连续投影算法(successive projections algorithm, SPA)和CARS-SPA耦合算法等三种变量优选方法进行特征波段的筛选, 并建立(extreme learning machine, ELM)预测模型, 为了检验模型的有效性, 将ELM模型与基于BP神经网络、 支持向量机(support vector machine, SVM)和随进森林(random forest, RF)的土壤水分含量预测模型进行比较, 以期选择最优模型, 为土壤水分含量等研究及当地精准农业提供科学支撑和参考。
以新疆塔里木盆地中北部的渭-库绿洲作为实验区, 并且依据其土壤、 地形等特征, 布设了39个采样点, 同时通过GPS将采样点的坐标进行记录, 目的在于后期验证。 每个采样点采用5点混合法进行采样, 采集深度为0~20 cm, 每个采样点采集2份样本, 分别装入铝盒和塑料袋中, 将铝盒中的土壤样本带回实验室进行土壤含水量的测定, 测定方法为烘干法, 即将土壤样本置于温度为105 ℃恒温箱中进行48 h烘干。 另一份样本放置在遮阴处, 避免土壤水分的流失, 以保持土壤样本的野外实际状态, 并及时获取其光谱数据。 光谱数据的详细测定方法见文献[6]中1.1。
由于原始光谱数据存在大量的噪声信息, 需要对其进行去噪, 而小波变换作为一种新的数据处理方法, 其具备傅里叶分析方法的优势, 同时又填补了该方法的缺点[7], 小波变换的表达式见文献[6]中1.2。 于雷等[8]的研究结果表明, 在进行小波变换时, 当小波母函数为db4时的分解效果最佳。 本研究利用这个结论对原始光谱数据进行8层分解, 同时获取其相应的特征光谱(L1~L8)。
由于高光谱数据量大, 所以小波系数重构后仍存在大部分冗余和共线信息, 导致计算量大和模型复杂, 对光谱的定量分析造成严重影响[9]。 采用CARS算法, SPA算法和CARS-SPA耦合算法筛选最优变量, 降低数据的共线性和冗余, 使构建的模型简化。 CARS算法借助自适应重加权采样技术(adaptive reweighted sampling, APS)、 指数衰减函数(exponentially decreasing function, EDP)和十折交互检验确定最优变量子集, 它可筛选出对土壤属性较敏感的波长变量, 并可以解决变量筛选时的组合爆炸问题。 SPA算法是一种前向选择算法, 当校正模型的交互验证均方根误差RMSECV最低时, 相应的波长变量集为筛选的共线性最小的最佳特征波长变量集。 CARS-SPA耦合算法是通过CARS算法先筛选出土壤属性的特征波长, 但波长变量之间仍然存在共线性, 为了更加有效的筛选出最少的特征变量, 经CARS筛选特征波长后再利用SPA进行二次特征波长筛选。
引入ELM构建SMC预测模型, 并且比较BP, SVM, RF和ELM模型的稳定性。 由于BP, SVM和ELM严格意义上均属于神经网络系列的预测模型, 而RF属于非线性回归模型, 因此选择两种具备代表性的本质同类算法BP和SVM, 一种本质异类算法RF, 使得构建的模型更具有现实意义。
BP是多层前馈神经网络[10], 作为常用的预测模型中的一种, 其结构简练、 准确度较高; SVM最早是一种用有导师学习方式来解决二分类问题的模型, 它能找出多维空间数据的分离最优超平面, 并尽可能让所有训练集到该超平面的误差最小[11]; RF模型是建立在决策树基础上, 通过多次bootstrap 抽样获得随机样本, 并通过这些样本分别建立相对应的决策树, 对于回归问题, 其最终的结果为所有决策树得到的结果的均值[12], RF模型建立的过程中涉及到2个关键的参数: 决策树的数量(ntree)和节点分裂的次数(mtry), 本文预测设定ntree为1 000, mtry为2; ELM算法是近年提出的单隐层前馈神经网络[13], 它在算法执行过程中随机设定输入层与隐含层之间的权值和阈值, 不用重复更新迭代网络的输入权值以及隐元的偏置, 并可以得到最优解, 因此其运算时间短、 移植性强[14]。
为了评估模型的效果, 选择如下参数来进行评价, 如决定系数(determination of coefficients, R2)、 均方根误差(root mean square error, RMSE)和相对分析误差(residual predictive deviation, RPD), 即相对于建模集来说, 分别为
通过对研究区SMC进行统计可知, 如表1。 其中建模集样本和验证集样本的土壤水分含量的平均值分别为0.146和0.148, 其整体样本土壤含水量平均值为0.147, 变异系数(coefficient of variation, CV)为0.388, 属于中等变异。
| 表1 土壤样品SMC统计特征 Table 1 Statistical characteristics of SMC of soil samples |
通过db4母函数对土壤光谱进行8层分解, 同时对相应分解层的小波系数进行重构, 得到L1— L8, 共8层特征光谱, 分解结果如图1。 在图1(a)(L0为原始光谱)中有2个较为明显的水分吸收峰(1 400和1 900 nm)和2个较为微弱的吸收峰(450和2 200 nm)。 图1(b)中由于原始光谱反射率自身的噪声进行传递, 使得在350~400 nm表现为“ 小毛刺” , 但是当分解到图1f时, 由于噪声传递被削弱, 导致此时的噪声已经被大量去除; 在小波分解的过程中, 由于细节信息不断被滤除, 使得光谱曲线越来越平滑, 同时一些土壤水分特征峰也逐渐消失, 在图1(g)中1 400和1 900 nm处仍然有显著的吸收峰, 但是在图1(h)中完全不能呈现。
 | 图1 小波变换1— 8层重构光谱Fig.1 Reconstruction spectra of original spectrum under 1— 8 wavelet level |
对小波变换后L1— L8与SMC进行相关性分析可知(表2), 表中相关性均通过0.01(阈值为± 0.408)的显著性检验, 其中L1与SMC两者之间有393个波段通过显著性, 在L1~L6中其显著性波段数量呈现增加趋势, 当进行到L6时其波段数量为602个, 达到最大, 当进行到L4时相关系数为0.619, 达到最大正相关, L6之后其显著波段数量及其相关系数发生骤减。 总的来说, L6在去噪的同时还尽可能的保留了光谱原始特征。 故本研究选择第6层为最大分解层数, 同时以L6为基础进行后续分析。
| 表2 SMC与各层特征光谱相关分析 Table 2 Correlation analysis between SMC and spectra from wavelet analysis in each level |
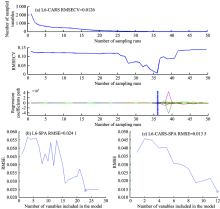
在小波变换后L6的基础上, 分别基于CARS, SPA和CARS-SPA算法筛选SMC的特征波长, 如图2所示。 从图2可知, 随着CARS算法进行特征波长筛选的进行, 在1~36次运行中, RMSECV逐渐趋于0, 这体现出L6与SMC之间的大量的无效信息被滤除, 当运行次数达到36次以后, 其值开始增大, 可能是由于在波长变量筛选的同时, 也滤除了与SMC相关的主要变量。 总体上来说, 在运行36次时RMSECV最小, 为0.012 6, 所对应的特征波长为81个。 图2(b)和(c)分别是利用SPA算法对全波段和CARS筛选结果进行二次筛选的RMSE曲线图, 随着筛选变量的增加, RMSE整体上呈下降趋势, 图2(b)和(c)中空心方块表示通过SPA算法筛选出的最优特征波长, 分别为23和12个。
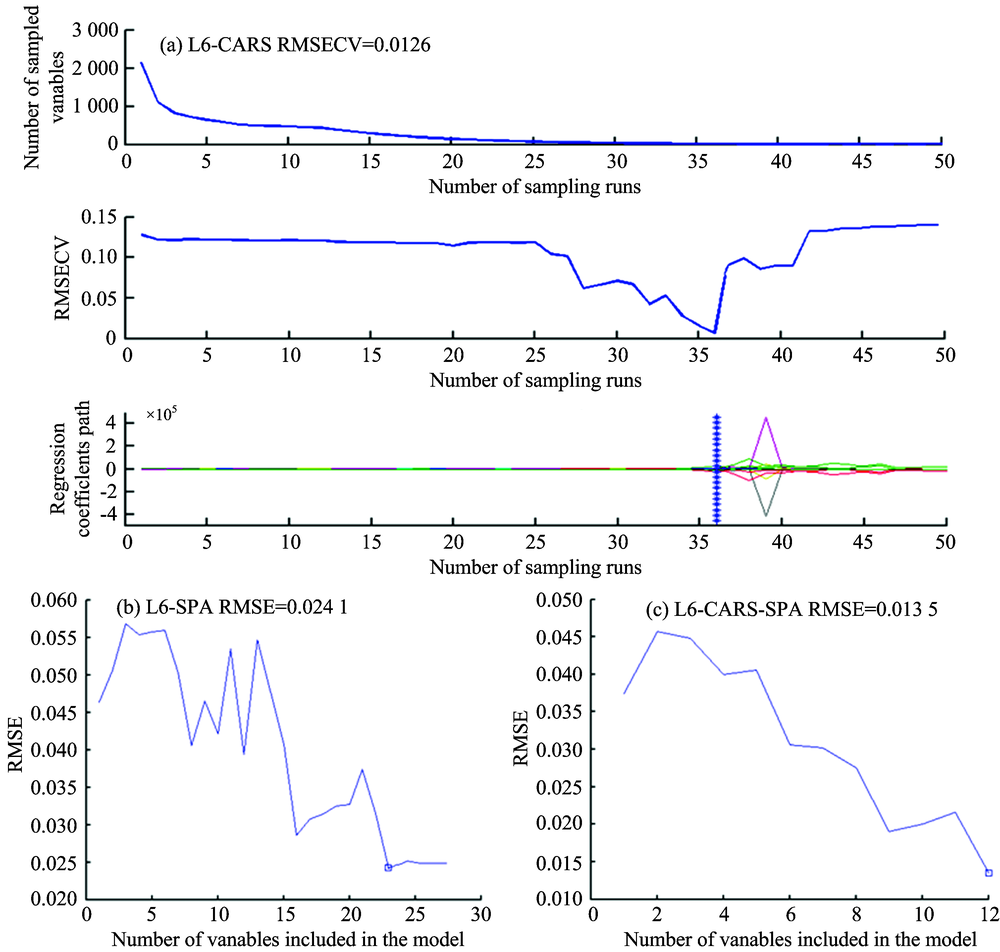 | 图2 变量优选过程Fig.2 Variable optimization process |
由表3可知, 在小波变换后L6的基础上, 通过CARS算法筛选出的特征波长数量要比用SPA, CARS-SPA算法筛选出的要多。 SPA算法筛选出23个波长变量, 占全波段的1.07%, 占CARS算法筛选变量的28.40%。 在经过CARS和SPA算法后, 所筛选的变量个数均减少, 本研究在CARS算法筛选变量的基础上引入SPA算法进行变量的二次筛选, 得到12个波长变量, 占全波段的0.56%, 占CARS的14.81%, 占SPA的52.17%, 使得波长变量个数大大减少。
| 表3 L6特征光谱变量优选结果 Table 3 The optimal variables of the spectral characteristics of the levels of L6 |
在小波变换后L6的基础上, 基于CARS, SPA和CARS-SPA算法筛选出SMC的特征波长分别为81, 23和12个, 并且分别构建基于特征波段的BP, SVM, RF和ELM四种SMC的预测模型, 为了更好的突出变量优选的优势, 引入全波段的BP模型进行对比, 结果见表4。 从表4可以看出, 基于全波段的BP预测模型的精度是最低的, 说明通过变量筛选后的模型的建模波段大大减少, 其稳定性更好。
| 表4 土壤水分含量预测结果 Table 4 Results of estimation for SMC |
在相同的SMC预测模型中, 对于不同筛选方法均表现为: L6-CARS-SPA> L6-CARS> L6-SPA的排列顺序, 相对于CARS算法来说, SPA算法所筛选的特征波长较少, 但基于SPA算法所构建的模型中精度最高的L6-SPA-ELM的RPD仅为1.416 3, 模型精度较差, 这是由于光谱数据存在大量与SMC不相关的冗余信息, 而其与真正有效信息呈非共线关系, 以致SPA算法获得的23个特征波长中存在部分冗余信息, 从而降低了SPA相应模型的预测精度。 而CARS-SPA算法获得的12个特征波长所构建的模型的精度均要高于相应模型, 这说明利用SPA算法对CARS算法所获取的特征波段进行二次筛选, 不仅可以简化模型, 而且可以提升模型精度。
在不同的SMC模型中, 其RPD≥ 2的较好模型共三种, 按其预测精度排序为: L6-CARS-SPA-ELM> L6-CARS-SPA-RF> L6-CARS-ELM, 而1.4≤ RPD< 2效果一般的预测模型也有三种, 按其预测模型预测精度排序为: L6-CARS-RF> L6-SPA-ELM> L6-SPA-RF, 其余模型基本无预测能力。 其中基于L6-CARS-SPA-ELM模型预测精度最高, 其RMSEC=0.015 1,
综上所述, 在小波变换后L6的基础上, 相对于CARS和SPA, 在CARS算法基础上进行SPA算法的二次筛选, 其建模波段最少, 而模型稳定性较好, 这有助于简化模型结构, 并且提升稳定性。 在不同的预测模型中, L6-CARS-SPA-ELM模型的预测效果最优, 其次是L6-CARS-SPA-RF。
图3为小波变换后L6, 基于CARS-SPA算法进行变量筛选后的ELM预测模型建模集和预测集检验结果。
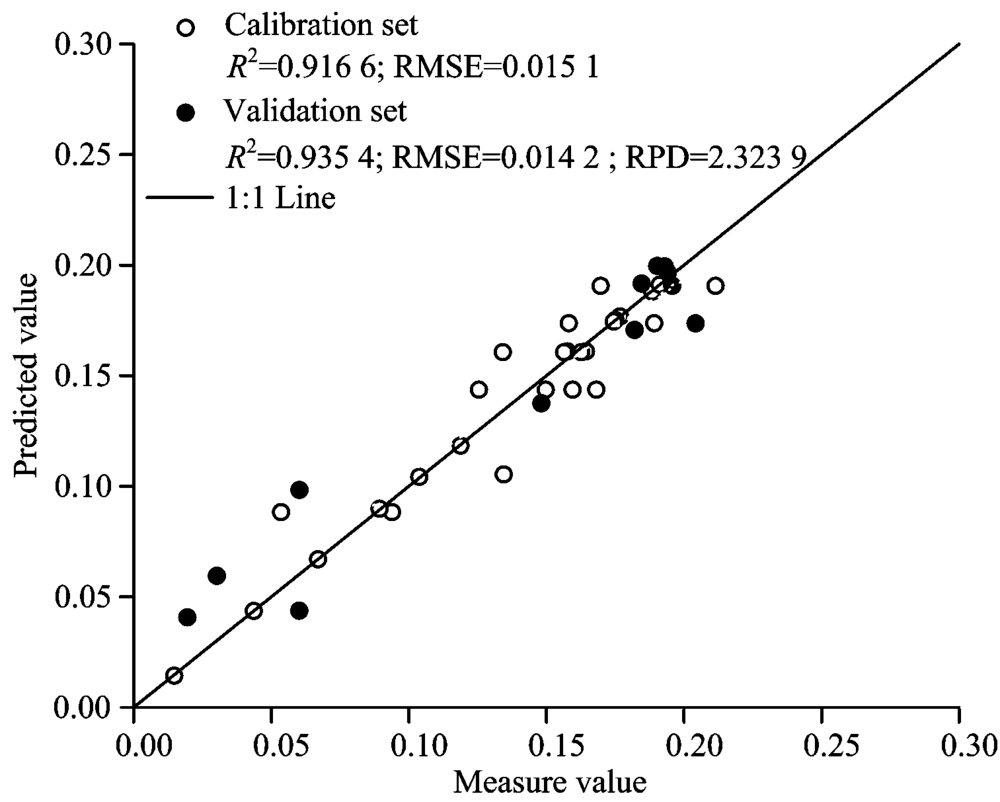 | 图3 实测值与估算值的比较Fig.3 Comparison between measured and estimated SMC values |
利用小波变换进行预处理, 并引入CARS, SPA和CARS-SPA算法进行特征波长优选, 并基于所选的特征波长构建BP, SVM, RF和ELM四种SMC预测模型, 通过比较分析, 得到如下结论:
(1)随着小波分解的进行, 总体上L6在去噪的同时还尽可能的保留了光谱原始特征, 为最大分解层。
(2)在L6的基础上, 引入CARS, SPA和CARS-SPA算法进行特征波长优选, 总体上, 基于优选波长所构建的模型的精度均比全波段要高, 其中基于L6-CARS-SPA构建的模型在相应的SMC预测模型中的精度最高, 说明小波变换和CARS-SPA算法的结合使其在建立模型时较为彻底的去除噪声和无信息变量, 并消除变量间的共线性。
(3)在所有的SMC预测模型中, 具有预测能力的共六种, 排序为: L6-CARS-SPA-ELM> L6-CARS-SPA-RF> L6-CARS-ELM> L6-CARS-RF> L6-SPA-ELM> L6-SPA-RF, 由此可知, 相对于BP, SVM, ELM和RF的预测能力更好, 其中L6-CARS-SPA-ELM精度最高, 其RMSEC=0.015 1,
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|