
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
可见、 近红外光谱和深度学习CNN-ELM算法的煤炭分类
[
LE Ba Tuan1, 3  , 肖冬
, 肖冬1, * , 毛亚纯2 , 宋亮2 , 何大阔1 , 刘善军2 ]
, 肖冬, 毛亚纯|
|


作者简介: LE Ba Tuan, 1990年生, 东北大学信息科学与工程学院博士研究生 e-mail: lebatuan@qq.com
煤是工业的主要能源, 煤的品质对工业和环境起决定性作用。 在使用煤的过程中, 如果不能准确确定煤的品种, 有可能对生产效率、 环境污染、 经济损失等会造成重大的影响。 传统的煤分类, 主要依靠人工方法和化学分析方法, 这些方法的缺点是高成本和耗费时间。 如何快速准确确定煤的品质很重要。 因此, 提出深度学习、 极限学习机-ELM算法和可见、 红外光谱联合建立煤矿分类模型。 首先, 从抚顺、 伊敏和河南夹津口煤矿区采取不同煤样品, 并使用美国Spectra Vista公司的SVC HR-1024地物光谱仪测得光谱数据。 然后利用深度学习的卷积神经网络-CNN提取光谱特征, 并采用ELM算法对光谱数据建立分类模型。 最后, 为进一步提高分类精度, 引入粒子群算法。 通过全新定义惯性权重和加速系数的取值范围来改进粒子群算法, 并使用改进粒子群算法优化CNN-ELM网络。 实验结果表明, 和PCA特征提取方法比较, CNN网络能够更好的提取光谱特征, CNN-ELM分类模型有良好的分类效果; 改进ELM分类模型的分类精度高于基础ELM和SVM分类模型。 与传统的化学分析方法和人工方法相比, 此方法在经济、 速度、 准确性方面均具有无可比的优势。
Coal serves as the main energy in industrial field, the quality of which has a decisive effect on industry and environment. In the using process of coal, if the category of the coal fails to be identified correctly, it will result in great harm to production efficiency, environmental pollution and economical loss. The traditional way of classifying coal mainly depends on artificial classification as well as chemical analysis, which however entails high cost and consumes too much time. Therefore, it becomes more and more important to identify the quality of coal quickly and correctly. Hence, this essay comes up with the idea of combining deep learning, ELM arithmetic and visible, infrared spectra to construct coal classification model. Firstly, we collected different coal samples from Fushun, Yimin and Henan Jiajinkou coal mining area, and used the American Spectra Vista SVC HR-1024 spectrometer for the measurement of the spectral data. Then we used the deep learning of convolutional neural network-CNN to extract spectral characteristics, and adopted ELM arithmetic to construct classification model for spectral data. Finally, in order to further improve the classification accuracy, this article made use of particle swarm optimization algorithm by using a range of newly defined inertia weight and acceleration factor values to improve the particle swarm optimization algorithm. Then, we used the improved particle swarm optimization to optimize CNN-ELM networks. Experimental results from comparison between PCA and CNN network reveal CNN network as a better feature extraction method for the spectrum. The results also show that CNN-ELM classification model has a good classification effect. The improved ELM classification model accuracy is higher than that of the basic ELM and SVM classification model. Compared with the traditional chemical methods and artificial methods, this method has the advantage of being unparalleled in economy, speed and accuracy.
煤是主要的能源, 煤主要来自于煤矿。 2014年, 世界煤矿已经探明可开采储量大约8 900亿吨, 蕴藏丰富的国家包括美国(2 400亿吨)、 俄罗斯(1 500亿吨)、 中国(1 250亿吨)[1]。 中国是生产煤的重要国家, 根据最新数据, 2014年中国煤炭产量达39亿吨。 随着工业的发展, 全球对煤质量要求越来越高。 高品质的煤对生产效率和环境污染起决定性作用。 这样也提高了对煤炭分类的要求。 传统的煤矿分类方法有两种。 一是人工分类方法, 此方法虽然分类速度比较快, 但分类准确率往往偏低。 二是利用化学分析方法分类, 虽然其精度较高, 但该方法存在成本高、 耗时长的缺点。 因此 如何快速准确确定煤的种类是现代选矿技术必须要解决的重要问题。 其对降低分类成本和提高分类效率有着重大的意义。
由于光谱分析技术的成熟, 具有分析速度快、 检测成本低、 效率高等优点。 近些年来光谱分析已被广泛应用于岩矿分类、 品位鉴定和食品检验等领域[2, 3, 4]。 由于煤矿光谱受碳、 硫、 铁、 等的氧化物的影响, 光谱数据中往往包含许多对煤炭分类影响无关的化学信息, 并使得煤的光谱数据呈现数据维数高、 冗余量大等特点, 所以必须对煤的光谱数据做有效的特征提取。 近年来, 深度学习的卷积神经网络[5](CNN)被广泛应用在分类识别模型中。 CNN是一种新的提取特征方法, 其中结构包含多层的隐含神经网络, 隐含层包括两种: “ 卷积层和采样层” 。 CNN的权值共享网络方式使得它更像生物的神经网络结构, 从而降低了模型的复杂度, 减少了权值量, 能更好地提取数据的特征。
极限学习机(ELM)是在2006年Huang[6]提出的一种单隐含层神经网络。 ELM以训练速度快、 泛化性能好、 分类精度高等优点得到了广泛的应用[7, 8]。 因为CNN网络是一个很好的提取特征器但它并不是一个很好的分类器, 而ELM是一个很好的分类器。 所以将两者联合构成一个更完好的分类模型, 然后将这个模型与光谱融合应用于煤炭分类识别。
煤炭样品来自抚顺、 伊敏和河南夹津口煤矿区, 包括无烟煤31个、 肥煤57个、 焦煤60个和褐煤58个, 共有206个样本。 使用美国Spectra Vista公司的SVC HR-1024地物光谱。 该仪器光谱范围: 350~2 500 nm。 内置存储器: 500 scans(扫)。 重量: 3 kg, 通道数: 1 024。 光谱分辨率(FWHM≤ 8.5 nm)1 000~1 850 nm。 最小积分时间: 1 ms。
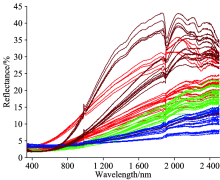
首先对样品清洗处理, 然后磨粉加工。 实验中, 仪器扫描时间为1 s· 次-1, 光谱仪的探头距煤粉样品片表面300 mm, 并垂直于样品片表面。 为减少周围环境对光谱测试的干扰, 实验在一个封闭室内完成, 避免太阳和其他光源的照射, 实验人员不得走动并穿着深色服装。 利用光谱仪(SVC HR-1024)对各样本进行五次光谱测试, 然后将光谱数据结果取平均值作为该样本的光谱数据。 实验中每10分钟进行一次白板测量校准。 部分煤样和实验现场如图1所示; 图2是四种不同煤的光谱比较图, 可以看出煤样吸光度比较高。 这是因为煤本身是黑色, 特别在可见光范围内的大部分能量都被吸收。 光谱混杂在一起, 光谱有效信息少。 所以必须借助深度学习提取特征, 机器学习进行分类, 才能够有效提高分类结果。
 | 图1 部分煤样(a)和实验现场(b)Fig.1 Some coal samples (a) and experimental sites (b) |
 | 图2 部分煤样的光谱Fig.2 The spectra of some coal samples |
卷积神经网络以数据为矩阵形式作为输入, 隐含层包括卷积层和采样层, 最后输出层是一个一维数据[9]。 如果第l层是卷积层, 那么第j个的特征映射为
式(1)中: Mj是输入数据的集合; f为非线性函数如Sigmoid函数、 ReLU函数、 Softplus函数等;
如果第l层是采样层, 那么第j个的特征映射为
式(2)中: DO(· )则是采样函数, 有很多不同的采样函数方案可选如随机采样、 求均值、 最大值等;
如果第l层为输出层, 那么对应第j个特征映射为
式(3)中, v为上一层的输出向量;
对于N任意不同的样本(xi, ti), 其中xi=[xi1, xi2, …, xin]T∈ Rn, ti=[ti1, ti2, …, tim]T∈ Rm, 那么标准的L个隐含层神经元的单隐层前馈神经网络为
式(4)中: ai=[ai1, , ai2, …, ain]T∈ Rn表示输入层神经元和隐含层第i个神经元之间的输入权值; β i为输出权值; bi为偏置; ai· xj表示ai和xj的内积。
则ELM的目标函数可以另一种方式表达为
式(5)中
H是神经网络的隐含层输出的矩阵; T是期望输出。
Huang教授的算法是随机选择输入权值和隐含层偏差值, 训练这个网络结构相当于求解线性系统Hβ =T的最小二乘解
Huang教授已经证明该线性系统最小二乘解的最小值是
式(9)中: H+是的Moore-Penrose广义逆矩阵, 并且Hβ =T的最小二乘解的最小值是唯一的。
粒子群优化算法[10](particle swarm optimization, PSO)是由Kennedy和Eberhart提出的一种全局优化算法, 思想来自鱼群和鸟群觅食行为。 由于PSO算法结构简单、 易实现、 功能强大等, 所以在优化问题上获得了普遍的应用。 粒子群优化算法实现过程如下: 在一个群里, 每一只鸟被看成一个粒子, 它们的速度Vi=(Vi1, Vi2, …, Vid); 和位置Xi=(Xi1, Xi2, …, Xid), 其中i=1, 2, …, m。 在每一代中, 通过式(10)和式(11)不断更新位置, 以找出最优位置, 并记录下来。
式中, pBesti=(pBesti1, pBest2i, …, pBestid)是粒子本身经历的最优位置; gBesti=(gBesti1, gBest2i, …, gBestid)是全体种群经过的最优位置, ; i=1, 2, …, m; k是当前迭代数; ω 是惯性权重; c1和c2是加速系数; r1和r2是在[0, 1]上的均匀分布随机数。
传统的PSO算法结构中, 惯性权重和加速系数是一个固定不变的值。 黄少荣[11]已经证明惯性权重ω 取值范围在(0.4, 0.7); 加速系数c1取值范围在(0.5, 3.0)和c2在(0.5, 3.5)能够更有效地避免早熟收敛, 对网络增加稳定性。 我们提出式(12)— 式(14)来对惯性权重和加速系数赋值以改进粒子群算法网络结构(称作IPSO算法)。
式中ω 是在(0.4, 0.7)之间的随机数, k和kmax是算法当前迭代数和最大迭代数。
CNN主要通过卷积层和采样层来提取对象特征, 并采用梯度下降法来训练找到网络的最小化全局误差。 所以CNN网络能够提取更好的分类特征, 不过它的感知器并不是一个很好的分类器。
ELM是一个单隐含层的前馈神经网络, 其优点在于网络训练速度非常快、 分类精度高、 泛化性能好。 不过极限学习机只有在训练数据有足够好的特征的前提下才能获得高的准确率。
在ELM神经网络中, 权值和偏置量是随机给定的, 导致部分权值和偏差未达到最优状态, 所以每一次输出的结果存在比较大的差异。 而改进粒子群算法是一种全局优化算法, 可以很好地寻找ELM权值和偏差量的最优值。
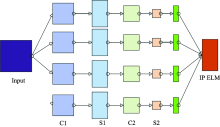
根据这些情况, 将CNN, ELM和IPSO结合起来(CNN-IPELM), 克服它们各自的缺点, 充分利用其优点。 图3显示CNN-IPELM的结合方式。 CNN网络结构选择2层卷积(C1, C2)和2层采样(S1, S2), 最后层则是IPELM分类器。 整个网络相当于将CNN作为特征提取部分, 然后将特征传送给IPELM进行训练、 分类。
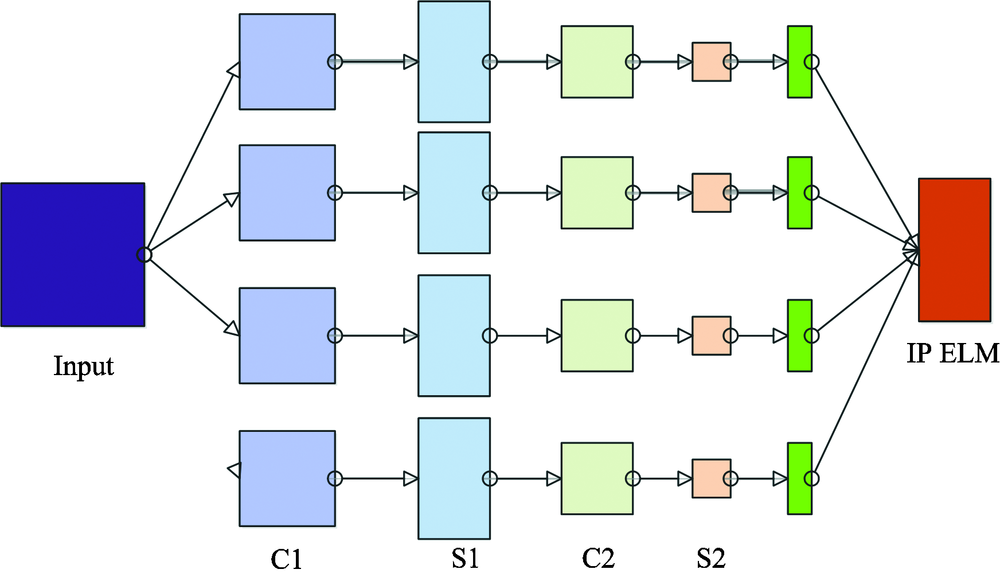 | 图3 CNN, ELM和PSO的组合网络Fig.3 The combined network of CNN, ELM and PSO |
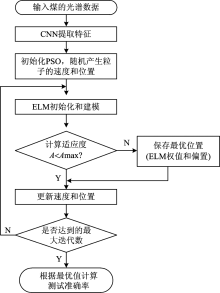
将CNN-IPELM网络应用到煤炭分类, 分类模型流程如图4所示。
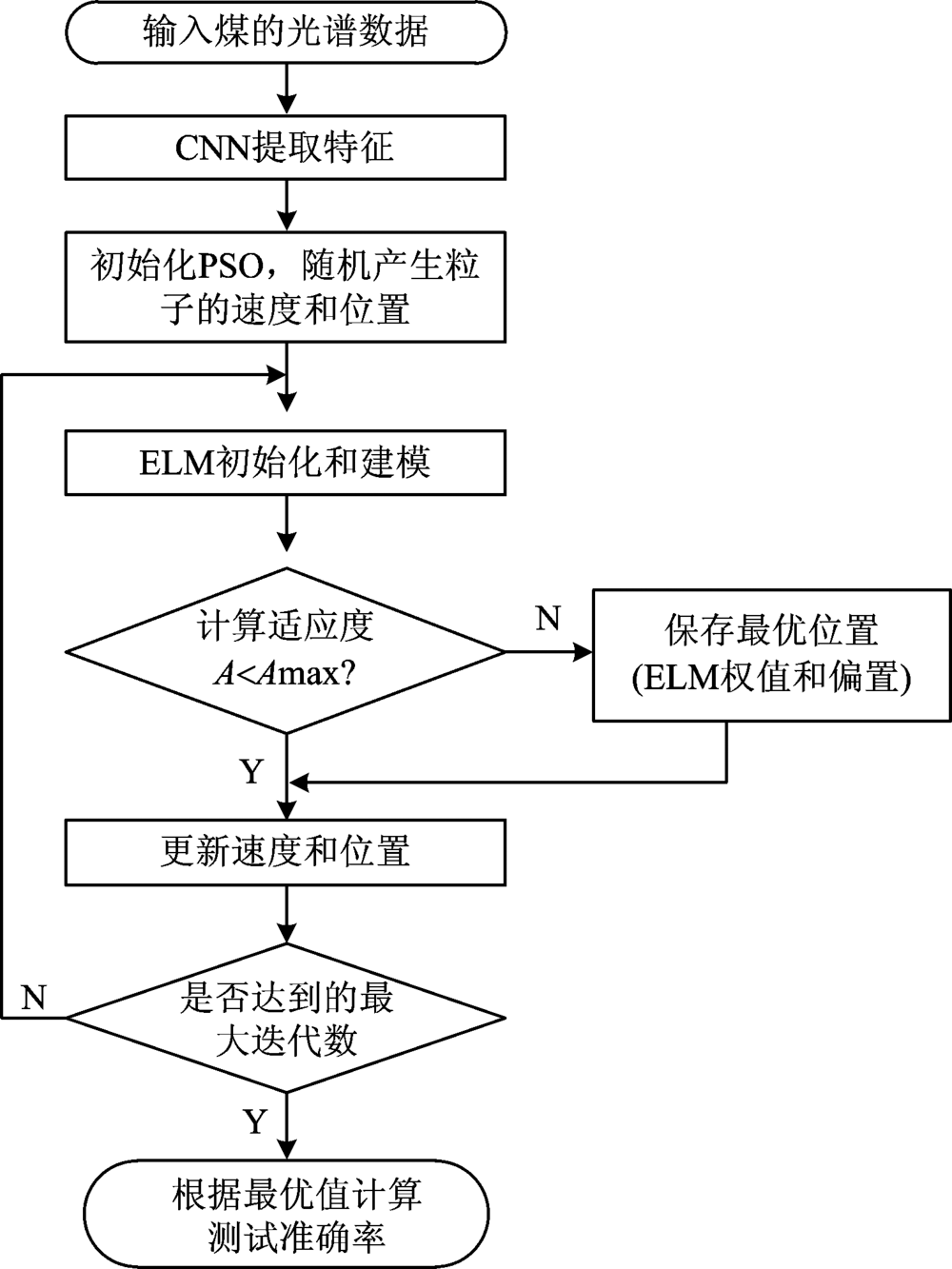 | 图4 基于CNN-IPELM 模型的煤分类流程图Fig.4 The flow chart of coal classification based on CNN-IPELM model |
具体步骤为:
(1) 把光谱数据输入CNN神经网络提取特征。 选择Sigmoid为卷积层的激活函数, 采样层选择均值采样函数。 每个光谱数据有1 024个特征, 经过特征提取后, 输出数据为350个特征。
(2) 初始化IPSO粒子群和ELM神经网络。 IPSO选择迭代数=50, 粒子群数量=40; 选择Sigmoid函数作为ELM神经网络的激活函数, 隐含层节点数为20。
(3) 使用ELM算法对光谱特征数据训练、 验证以得到IPSO适应度值, 对适应度值进行判断。 然后保存最优直和IPSO的速度和位置。
(4) 当网络达到最大迭代数时就退出寻优, 计算测试分类度, 验证方法的有效性。
分别建立CNN结合传统ELM(CNN-ELM)模型, CNN结合传统粒子群PSO-ELM(CNN-PELM)模型和CNN-IPELM模型。 共有206个光谱数据, 其中选取120个作为训练数据、 86个作为测试数据。 模型训练中, 把无烟煤类对应数字1、 肥煤类对应数字2、 焦煤类对应数字3、 褐煤类对应数字4。 对煤炭其分类结果如图5, 图6, 图7和表1所示。
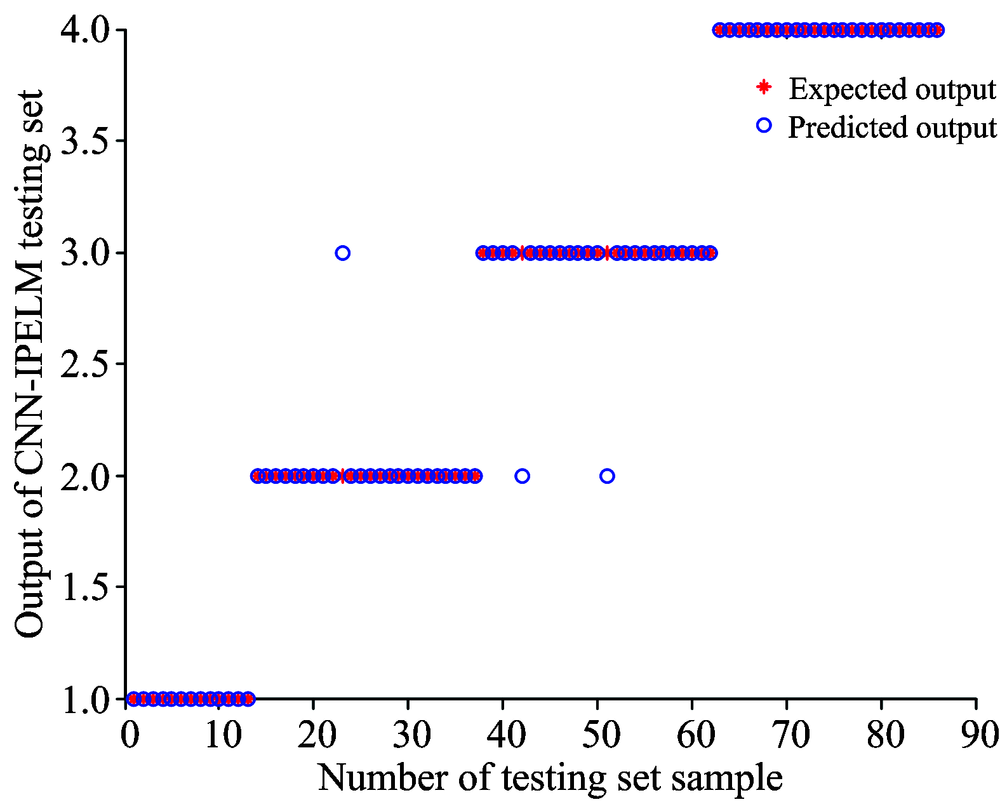 | 图5 CNN-ELM测试集输出结果与实际期望的散点分布图Fig.5 Predicted and expected output scatter profiles of CNN-ELM model testing set |
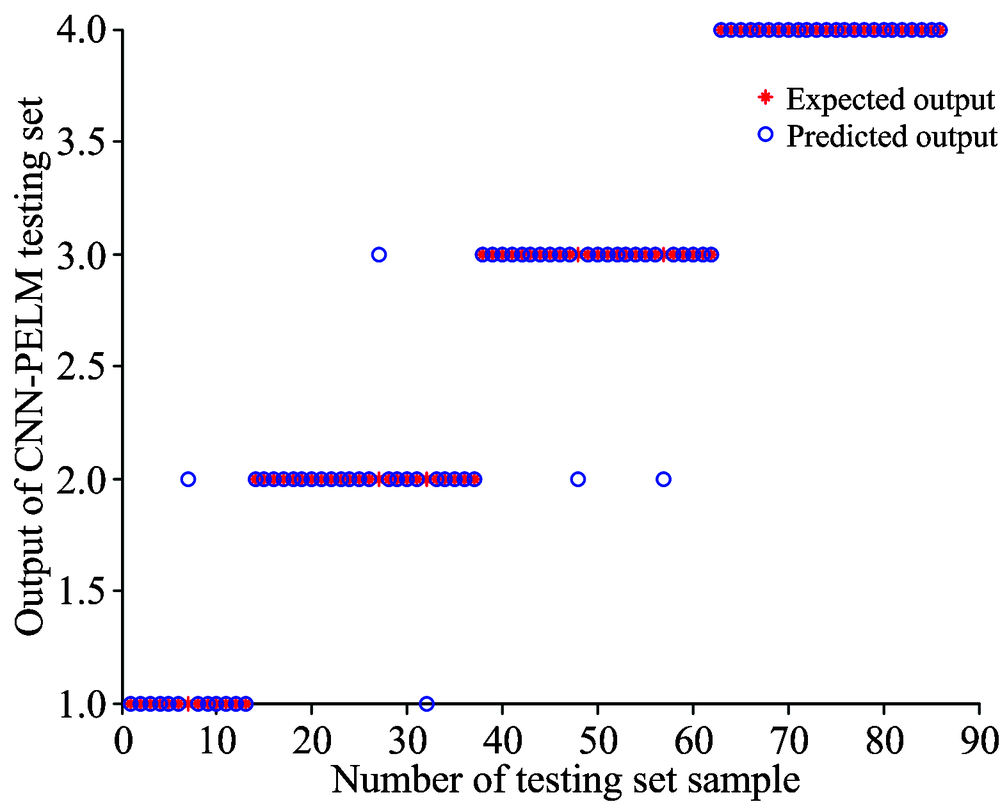 | 图6 CNN-PELM测试集输出结果与实际期望的散点分布图Fig.6 Predicted and expected output scatter profiles of CNN-PELM model testing set |
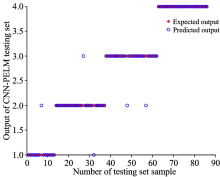
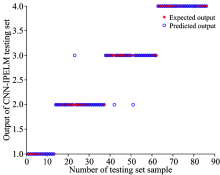
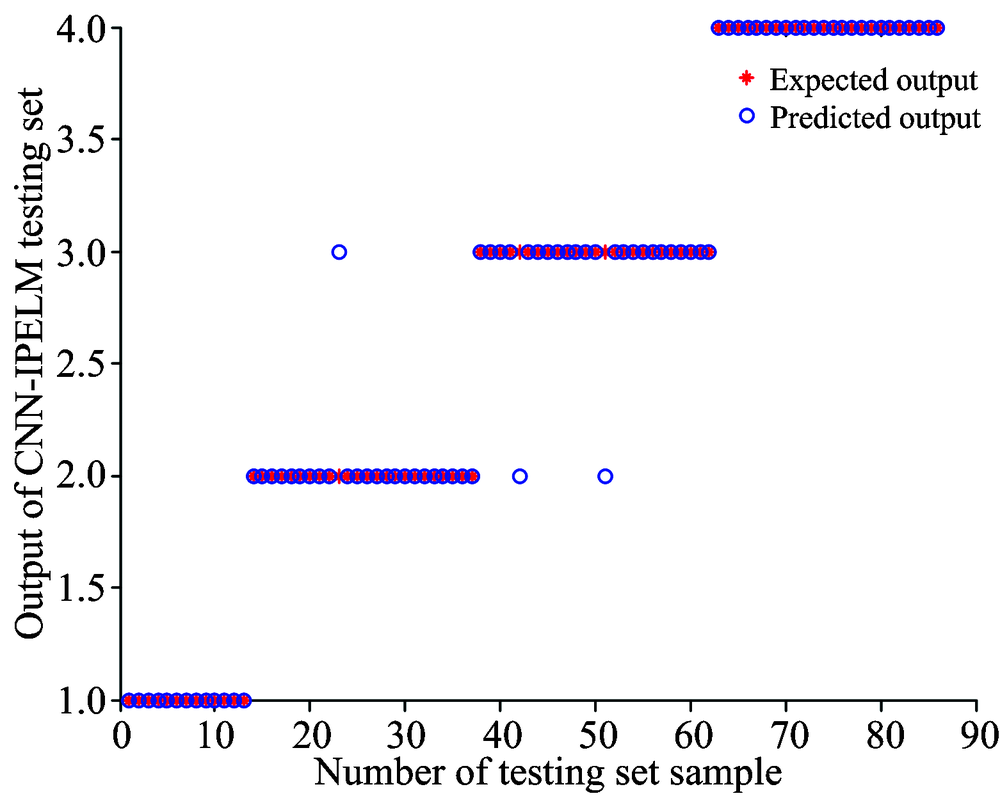 | 图7 CNN-IPELM测试集输出结果与实际期望的散点分布图Fig.7 Predicted and expected output scatter profiles of CNN-IPELM model testing set |
| 表1 不同CNN-ELM模型的测试精度 Table 1 Test accuracy of different CNN-ELM models |
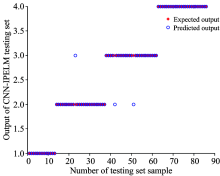
图5是CNN-ELM模型的分类结果的分布图, 可以看到错误点主要集中在第2类和第3类, 也就是肥煤和焦煤。 这是因为这两种煤都属于烟煤, 在可见、 近红外光谱数据比较接近, 所以会出现极少数部分错误的识别。 第4类没有错误点, 也就是褐煤识别精度是100%, 这是因为褐煤和其他三种煤的光谱数据差别比较大。 根据表1的结果, CNN-ELM模型的测试集分类精度达到91.87%。
图6和图7分别为CNN-PELM模型和CNN-IPELM模型的分类结果的分布图, 可以看到两个模型减少了第1类、 第2类和第3类的错误识别。 CNN-PELM模型分类错误个数是5个, CNN-IPELM模型分类错误个数是3个。 第4类的分类结果没有错误。 根据表1所示, CNN-PELM模型测试集的分类精度是94.19%, CNN-IPELM模型测试集的分类精度是96.51%, 说明了改进粒子群算法能够有效的优化ELM分类器。
通过以上的实验分析可以得出结论。 提出的三种模型对煤炭分类都有良好的分类结果, 分类精度都达到90%以上。 CNN-IPELM分类精度达到96.51%, 证明了改进粒子群可以提高ELM的分类精度。 也说明提出的模型能够很好地区分煤的种类, 并具有分类速度快、 精度高的优点。
主成分分析(PCA)[12]是一种典型的传统数据特征提取和压缩算法。 主成分分析结合极限学习机(PCA-ELM)近几年来被广泛应用在分类和回归问题上[13, 14]。 支持向量机(SVM)是Vapnik[15] 提出的一种机器学习分类方法, 其方法以统计学理论为基础, 针对有限样本的一种通用学习方法, 能有效解决小样本、 高维数、 非线性等问题, 近年来被应用于许多领域。 将PCA-ELM方法、 CNN-ELM方法, PCA-SVM方法、 CNN-SVM方法进行比较。 这里, PCA算法以贡献度为99.97%的前10个主成分来代替原来的数据。 其分类结果如表2所示。
| 表2 不同方法的分类精度 Table 2 The classification accuracy of different methods |
根据表2的结果可以看出, 对于采用CNN提取特征的模型, 分类准确率都在90%以上。 CNN-IPELM模型分类精度达到96.51%, 高于CNN-ELM, CNN-PELM和CNN-SVM模型。 对于使用PCA提取特征的模型, 分类精度最高的模型是PCA-IPELM为93.02%, 最低分类精度的模型是PCA-ELM为87.20%。 说明经过CNN网络提取特征后的数据使模型能够更好地识别出煤的品种, 这些模型的分类精度总体高于对应PCA提取特征的模型。 结果也证明了粒子群算法能够有效的优化ELM网络, 改进后的ELM模型分类准确率高于传统ELM模型和SVM模型。
表3是对206个煤样本采用人工经验方法、 化学方法和CNN-ELM网络模型分类的投资费用和所消耗时间的对照表。 可以看出传统的人工经验方法虽然费用低但分类精度不高。 化学方法除了需要购买实验药品之外, 一些化学实验仪器投入成本在100万以上。 此方法虽然精度高但成本很高, 时间长。 相对而言, 本方法包括光谱仪和计算机的投入成本在35万以内, 比传统人工方法和化学方法投入更少、 分类精度高、 耗时更短。
| 表3 不同识别方法对照 Table 3 The comparison of different identification methods |
提出了一种可见、 近红外光谱结合深度学习CNN-ELM网络的煤炭分类模型。 首先对206个不同品种的煤样采集光谱数据。 采用深度学习CNN网络结合ELM算法建立煤炭分类模型。 为进一步提高分类精度, 提出改进粒子群算法以优化CNN-ELM网络模型。 结果表明CNN-IPELM网络能够很好的识别煤炭种类。 与PCA提取特征方法比较, CNN网络可以更好地提取光谱数据的特征。 到目前为止, CNN网络被广泛应用在图像处理和语音识别系统上, 而很少应用到其他领域的研究。 本研究发现, CNN网络能够很好的提取光谱数据的特征。 CNN与ELM网络结合, 互补两者之间的缺点, 构成一个更好的分类器。 与传统的煤炭分类相比, 可见、 近红外光谱结合CNN-ELM模型可以在经济、 速度、 准确性具有无可比的优势和重要的实际应用价值。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|