
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
模糊非相关鉴别C均值聚类的茶叶傅里叶红外光谱分类
[武小红1, 2  , 翟艳丽
, 翟艳丽1 , 武斌3 , 孙俊1, 2 , 戴春霞1, 4 ]
, 翟艳丽|
|


作者简介: 武小红, 1971年生, 江苏大学电气信息工程学院副教授 e-mail: wxh_www@163.com
茶是一种让人喜爱的健康饮品, 不同品种的茶叶其功效和作用是不相同的。 研究出一种可靠、 简单易行、 分类速度快的茶叶品种鉴别方法具有重要的意义。 在模糊非相关判别转换(FUDT)算法和模糊C均值聚类(FCM)算法的基础上提出了一种模糊非相关鉴别C均值聚类(FUDCM)算法。 FUDCM可以在聚类过程中动态提取光谱数据的模糊非相关鉴别信息。 用FTIR-7600型傅里叶红外光谱分析仪分别采集优质乐山竹叶青、 劣质乐山竹叶青和峨眉山毛峰三种茶叶的傅里叶中红外光谱, 波数范围为4 001.569~401.121 1 cm-1。 先用多元散射校正(MSC)进行光谱预处理, 然后用主成分分析法(PCA)将光谱数据降维到20维, 再利用线性判别分析(LDA)提取光谱数据中的鉴别信息。 最后分别运行FCM和FUDCM进行茶叶品种鉴别。 实验结果表明: 当权重指数 m=2时, FCM的聚类准确率为63.64%, FUDCM的聚类准确率为83.33%; FCM经过67次迭代计算实现了收敛, 而FUDCM仅需17次迭代计算就可以实现收敛。 用傅里叶红外光谱技术结合主成分分析、 线性判别分析和FUDCM的方法能快速、 有效地实现茶叶品种的鉴别分析, 且鉴别准确率比FCM更高。
Tea, as a kind of healthy drink, is loved by many people. But its function and effect vary from different varieties. Therefore, it is of great significance to find a fast, easy and simple method for the identification of tea varieties. In order to classify different tea varieties quickly and accurately, fuzzy uncorrelated discriminant c-means clustering algorithm (FUDCM) was proposed based on the fuzzy uncorrelated discriminant transformation (FUDT) algorithm and fuzzy c-means clustering (FCM) algorithm in this paper. FUDCM can extract the fuzzy uncorrelated discriminant information from spectral data dynamically in the process of fuzzy clustering. To start with, Fourier transform infrared spectroscopy (FTIR) data of three kinds of tea samples (i. e. Emeishan Maofeng, high quality Leshan trimeresurus and low quality Leshan trimeresurus) was collected using FTIR-7600 spectrometer in the wave number range of 4 001.569~401.121 1 cm-1,. Secondly, multiple scattering correction (MSC) was applied to preprocess these spectra. Thirdly, principal component analysis (PCA) was employed to reduce the dimensionality of spectral data from 1 868 to 20 and linear discriminant analysis (LDA) was used to extract the identification information of the spectral data. Finally, FCM and FUDCM were performed to identify the tea varieties respectively. The experimental results showed that when the weight index m=2, the clustering accuracy rate of FCM was 63.64% and that of FUDCM was 83.33%. After 67 iterations, FCM achieved convergence while FUDCM did that after only 17 iterations. Tea varieties could be quickly and efficiently identified by combining FTIR technology with PCA, LDA and FUDCM, and the identification accuracy of FUDCM was higher than that of FCM.
茶叶中含有茶多酚, 茶多糖和茶氨酸等有益人体健康的物质。 我国民间有饮茶风俗, 茶文化一度风靡全国。 目前, 市场上茶叶品种众多, 人们都希望喝到放心的好茶, 茶叶质量的重要性已渐渐被人们所重视[1]。 但是, 市场上茶叶良莠不齐, 其优劣难以分辨。 另外, 假冒伪劣的茶叶在市场上屡见不鲜。 这些都给茶叶生产者和消费者带来一定的利益损害。 因此, 研究出一种快速有效的鉴别茶叶品种的方法十分重要。
红外光谱技术作为一种无损检测技术, 近年来, 已经在农产品和食品检测等领域得到广泛应用[2]。 例如: 杨新河等利用傅里叶红外光谱法对黑茶进行鉴别研究[3]。 Ayvaz等用便携式中红外系统收集马铃薯汁的中红外光谱, 利用归一化和Savitzky-Golay二阶多项式滤波器进行光谱预处理, 再用偏最小二乘回归(PLSR)建立校正模型预测七种不同颜色马铃薯的花青素, 酚醛物质和糖含量[4]。 张荣香等用以傅里叶红外光谱仪采集茶叶的红外光谱, 应用特征基理论对茶叶光谱提取特征信息, 实现了对重度发酵茶和非重度发酵茶的分类以及普洱熟茶和非普洱熟茶的识别[5]。 Cai等利用傅里叶红外光谱结合偏最小二乘和自组织神经网络对七种茶叶进行分类研究[6]。 李栋玉等用傅里叶变换红外光谱仪获得普洱熟茶在不同陈化时间的中红外光谱, 通过曲线拟合能反映茶多酚等化学成分的变化情况。 Mecozz等利用傅里叶红外光谱, 二维相关分析和双二维相关分析研究了精油对蚕豆的蛋白质二级结构所造成的影响[7]。 Kokalj等利用中红外光谱和多变量数学方法对药草茶的鉴定进行了一系列研究, 得出了高准确率的分类结果[8]。
傅里叶红外光谱通常是高维的复杂数据[9], 计算量大, 需要经过特征提取以降低数据维数和提取有用的特征信息。 常用的特征提取方法有主成分分析(PCA)[10], Fisher线性鉴别分析(LDA)[11], Foley-Sammon线性鉴别分析(FSDA)[12]和非相关线性鉴别转换(UDT)[13]。 用UDT可以计算得到一组最优的非相关鉴别矢量, 数据在它们的投影是非相关的。 模糊非相关判别转换(FUDT)是将模糊K近邻法和UDT相结合, 建立在模糊集理论上的模糊特征提取方法[14]。 我们在模糊C均值聚类(FCM)和FUDT的基础上, 提出模糊非相关鉴别C均值聚类(FUDCM)算法。 FCM在聚类时是不能提取特征的, 而FUDCM可以在聚类过程中提取光谱数据的模糊非相关鉴别信息。 实验结果表明, 在处理茶叶红外光谱的分类方面FUDCM效果要优于FCM。
用傅里叶红外光谱分析仪采集三种茶叶的傅里叶红外光谱, 利用多元散射校正(MSC)对茶叶的红外光谱进行预处理, 然后用主成分分析法对茶叶红外光谱进行维数压缩, 最后分别用FCM和FUDCM进行聚类分析。 由聚类结果可知, 傅里叶红外光谱结合FUDCM可实现快速有效的茶叶品种鉴别。
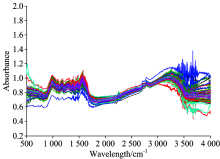
分别采集优、 劣质乐山竹叶青和峨眉山毛峰三种茶叶各32个样本, 样本总数为96。 将这96个样本研碎后用40目筛进行过滤, 然后每个样本均取0.5 g粉碎物与溴化钾按照1∶ 100的比例均匀搅拌混合, 每个样本取1 g混合物压膜。 在室温约为25 ℃左右用FTIR-7600型傅里叶红外光谱分析仪收集茶叶样本的傅里叶中红外光谱。 扫描次数为32次/样本, 扫描的波数范围为4 001.569~401.121 1 cm-1, 扫描间隔为1.928 5 cm-1。 采集每个茶叶样本中红外光谱三次, 其平均值作为光谱原始数据, 该数据的维数是1 868维。 茶叶样本的傅里叶中红外光谱图见图1所示。
 | 图1 茶叶样本的傅里叶红外光谱图Fig.1 FTIR spectra of tea samples |
步骤一: 初始化过程, 设置类别数c, 权重指数m, m∈ (1, +∞ ); 设置迭代次数r的初始值和最大迭代次数为rmax; 设置迭代最大误差参数ε 。
初始类中心
其中, 初始类中心
步骤二: 计算模糊类间散射矩阵SfB
其中,
步骤三: 计算模糊总体散射矩阵SfT
其中, xk为第k个测试样本。
步骤四: 计算特征向量
其中,
步骤五: 将xk∈ Rq转换到由Ψ 1, Ψ 2, …, Ψ p组成的特征空间中
其中, p和q均为样本的维数, Ψ p为第p个特征向量。
步骤六: 同样将
步骤七: 在Rp空间计算yk的模糊隶属度函数值
其中, yk为Rp空间里第k个样本, u
步骤八: 在Rp空间中计算i类的类中心值v
其中, v
步骤九: 增加迭代数r值, 即r=r+1; 直到‖ v
由于不同茶叶样品的颗粒大小和形状等存在差异性导致所采取的红外光谱受到不同散射影响, 为了消除散射影响常采用多元散射校正(MSC)进行光谱预处理[15]。 对图1的红外光谱进行MSC处理后得到的光谱如图2所示。
 | 图2 MSC预处理后的茶叶红外光谱Fig.2 FTIR spectra pretreated with MSC |
实验结果: p=2, 迭代终止时r=17次, 类中心矩阵为
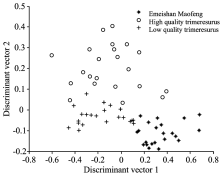
茶叶的傅里叶红外光谱数据是1 868维的数据, 直接用来分类则计算量很大, 故一般先采用PCA将光谱数据进行降维处理。 用PCA将茶叶的红外光谱数据维数降为8维, 再用LDA提取降维后数据中的鉴别信息。 从三种茶叶样本中各取10个样本构成茶叶样本训练集, 则训练集样本数为30个, 其余的样本构成茶叶样本测试集, 则测试集样本总数为66个。 运行LDA计算20维的训练集样本的鉴别向量, 将20维的测试集样本投影到前2个鉴别向量上, 其LDA的得分图如图3所示。 在图3中, 星号“ * ” 表示“ 峨眉山毛峰” , 圆圈“ ○” 和加号“ +” 分别表示“ 优、 劣质乐山竹叶青” 。 由图3可知, 三种茶叶测试样本的数据重叠非常少。 数据重叠少有利于提高聚类准确率。
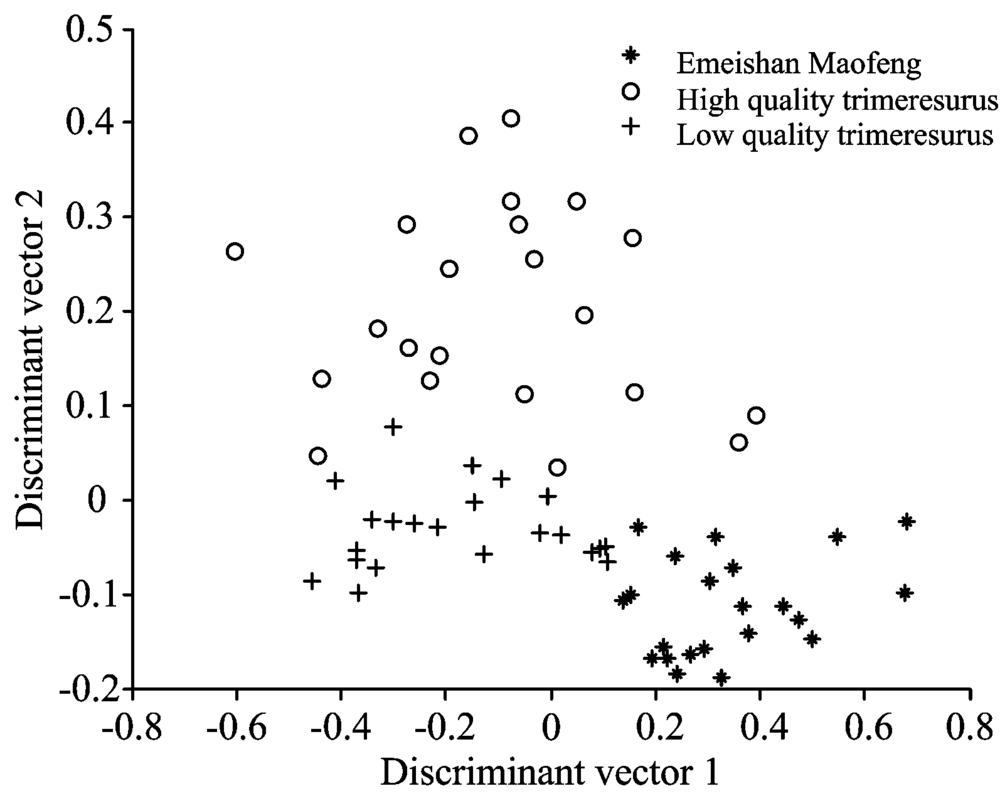 | 图3 LDA的得分图Fig.3 Scores plot of linear discriminant analysis |
FCM和FUDCM的初始类中心均为LDA变换后得到的训练样本的均值
FCM和FUDCM的初始参数值设置: 品种数c=3, 测试样本数n=96, 权重指数m=2, 最大迭代次数rmax=100, 迭代最大误差参数为ε =0.000 01, FCM和FUDCM的初始类中心见本文3.3中所述。
3.4.1 聚类准确率
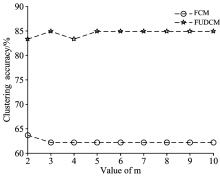
运行FCM和FUDCM算法对茶叶红外光谱测试集样本进行聚类分析。 当FCM和FUDCM的权重指数m取不同值时其聚类准确率如图4所示。 所以, 当FCM的权重指数m=2~10时, FUDCM的准确率均高于FCM的准确率。
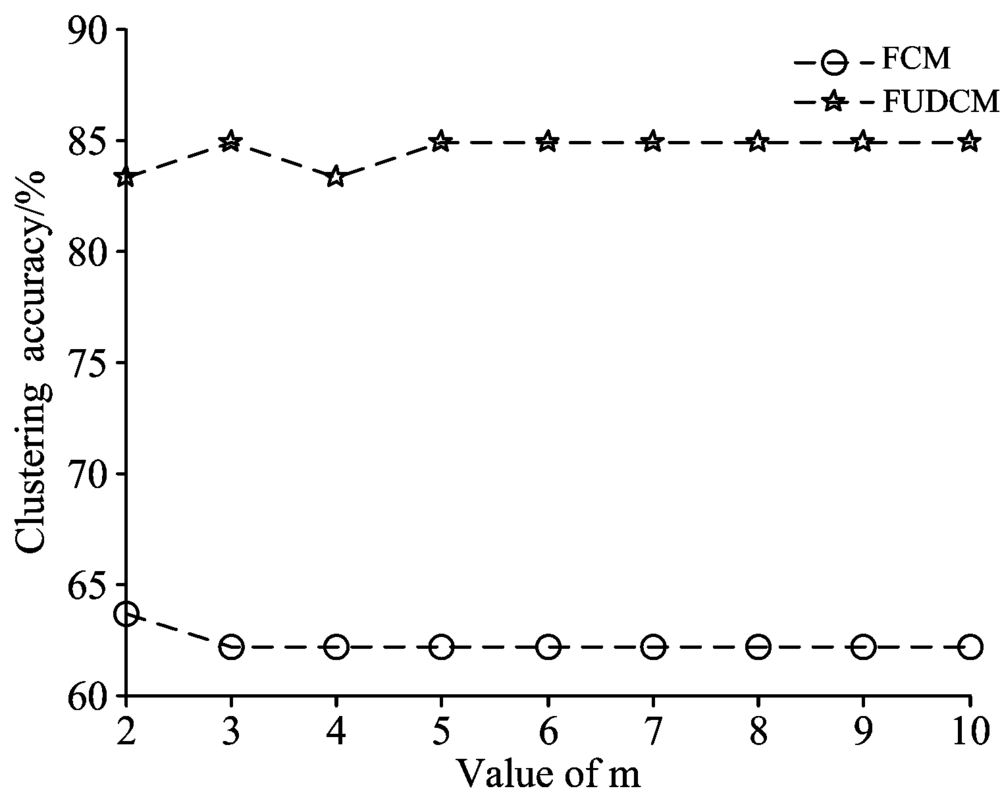 | 图4 FCM和FUDCM的聚类准确率Fig.4 The clustering accuracy of FCM and FUDCM |
3.4.2 聚类收敛状况分析
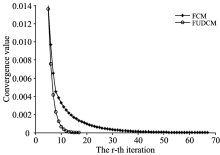
FCM和FUDCM的收敛状况如图5所示。 迭代次数越多则收敛速度越慢, 反之则越快。 由图5可知, FCM经过67次迭代后达到了收敛, 而FUDCM经过17次迭代就达到收敛。 所以, FUDCM的收敛速度比FCM快。
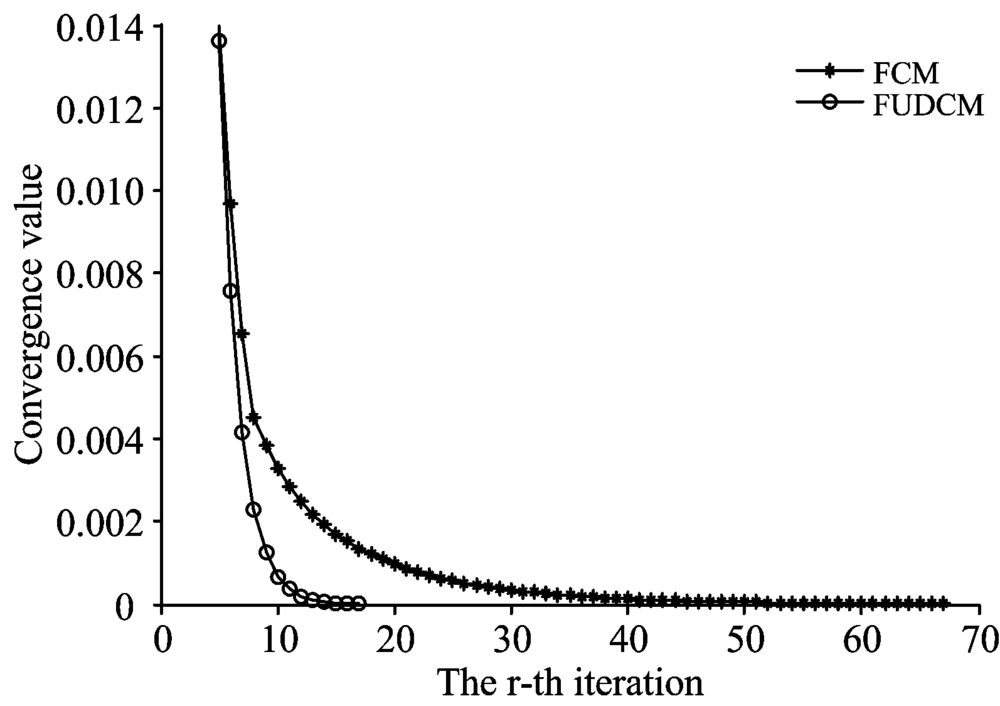 | 图5 FCM和FUDCM的收敛状况Fig.5 Convergence of FCM and FUDCM |
3.4.3 茶叶种类判别方法
本节所指的训练样本和测试样本是指经过LDA计算后得到的数据样本。 训练样本是已知的三个品种茶叶(即优质乐山竹叶青、 劣质竹叶青和峨眉山毛峰), 计算每种茶叶的训练样本的平均值为: 峨眉山毛峰平均值为
判断测试样本的茶叶的三个类别分别属于哪个品种茶叶的方法是: 分别计算测试样本的某个聚类中心和训练样本三类茶叶的平均值的欧式距离, 某个聚类中心离哪种训练茶叶品种的欧式距离最小则判定该聚类中心所属茶叶品种和这种训练茶叶品种是相同品种。 具体计算和分析如下:
判断以v
很明显v
对于第k个测试样本xk, 判断其属于哪一类的方法是: 如果其模糊隶属度u
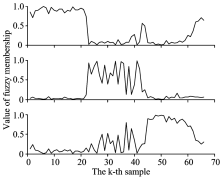
FUDCM迭代终止后的模糊隶属度值如图6所示。 第1个样本的模糊隶属度为u
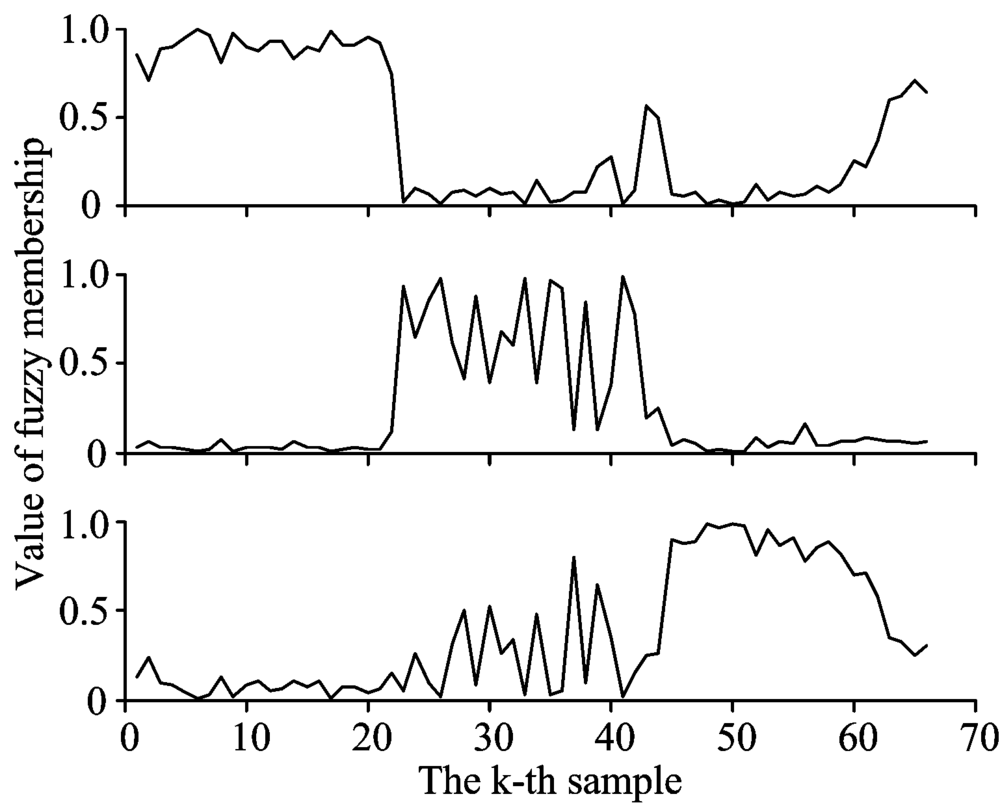 | 图6 模糊隶属度值Fig.6 Value of fuzzy membership |
将模糊C均值聚类(FCM)和模糊非相关判别转换(FUDT)结合起来, 提出了一种模糊非相关鉴别C均值聚类(FUDCM)。 FUDCM实现了在FCM聚类过程中动态提取光谱数据的模糊非相关鉴别信息, 获得比FCM更高的聚类准确率, 收敛速度比FCM更快。 实验结果表明: 利用傅里叶红外光谱, 结合PCA和LDA的FUDCM方法可以快速、 有效地将茶叶品种鉴别出来, 其鉴别准确率明显高于FCM。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|