


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外高光谱成像的微破损棉种可视化识别
[高攀1  , 张初
, 张初3 , 吕新2, * , 张泽2 , 何勇3, * ]
, 张初|
|


作者简介: 高 攀, 1981年生, 石河子大学信息科学与技术学院副教授 e-mail: gp_inf@shzu.edu.cn
优质棉种是全面推广棉花精量播种技术的基础。 采用近红外高光谱成像技术实现微破损棉种可视化识别, 为棉种精选设备的研制奠定理论基础。 以未破损和微破损两类棉种各540粒作为样本(其中405粒作为建模集, 135粒棉种作为预测集), 分批采集874~1 734 nm范围的样本高光谱图像, 提取光谱数据并去除首尾两端明显噪声保留955~1 659 nm范围内光谱为棉种样本的光谱。 首先使用Kennard-Stone(KS)算法进行样本划分, 并通过平滑算法Savitsky-Golay(SG)对光谱进行预处理。 采用二阶导数光谱(2nd spectra)方法、 连续投影算法(SPA)和主成分载荷(PCA-loading)方法分别选取10, 14和11个特征波长。 基于全部光谱数据和特征波长建立偏最小二乘判别分析(PLS-DA)模型、 K最邻近(KNN)模型和支持向量机(SVM)模型, SPA-PLS-DA模型取得了较好的结果, 建模集和预测集的鉴别率分别为91.50%和90.33%。 基于SPA-PLS-DA模型分别对未破损样本和微破损样本及其混合样本图像进行识别, 取得了较好的识别结果, 微破损棉种的识别率达90%以上。 结果表明, 结合近红外高光谱成像和图像处理技术, 能够实现微破损棉种的可视化识别。
High quality cotton seeds are the basis of precision seeding technique. In this paper, near-infrared hyperspectral imaging technology is used to realize the visible identification of micro-damaged cotton seeds, which lays a theoretical foundation for the development of cotton seeds selection equipment. Near-infrared hyperspectral images of two kinds of 540 cotton seeds, undamaged and micro-damaged, were acquired, of which 405 samples were used as the calibration set, and 135 samples were used as prediction set. After analyzing the original spectral curve of the full wave band, the noise at both ends was removed. Firstly, KS algorithm was used to divide samples, and the spectra was pretreated by smoothing algorithm( Savitsky-Golay), respectively using the second derivative spectra (2nd spectra) method, principal component analysis loading (PCA-loading) method and successive projection algorithm (SPA) method to extract the feature wavelength, then partial least squares discriminant analysis (PLS-DA) model, K nearest neighbor (KNN) model and support vector machine (SVM) model ware used to analyze the characteristic spectrum. By comparing the analysis results, SPA-PLS-DA was selected as the model, the discrimination rate of the calibration set and the prediction set is up to 91.50% and 90.33%, respectively. Finally, the SPA-PLS-DA model is used to identify the mixed images of undamaged and micro-damaged cotton seeds. The identification results were identified by different colors,the corresponding visual identification figure is generated, and good recognition results were obtained. Moreover, the recognition rate of micro-damaged cotton seeds was above 90%. The result indicates that the near-infrared hyperspectral technology and image processing technology can be used to realize the visual identification of the micro-damaged cottonseeds.
新疆生产建设兵团是全国重要棉花生产基地, 优质棉种已经成为兵团全面推广棉花精量播种技术的基础。 精量播种就是行距、 株距以及播种的深度都有严格要求的“ 一穴一粒” 单粒播种, 精量播种技术和机械化播种装备相结合, 既能够提高播种质量, 又可以节约50%~70%棉种播种量, 降低棉花生产成本。 近年来, 新疆兵团棉种由于成熟度的问题出现红籽, 或者在加工过程中经过轧花机、 剥绒机、 离心滚筒、 提升机、 抛光机等工序时造成棉种的大量破损。 红种和破碎棉种将严重影响棉种的质量, 明显降低棉种的发芽率, 阻碍了精量播种技术的发展。 目前, 在棉种分选方面, 已经有成套机械化设备可以较好地清选出轻杂物, 并利用明显色差有效剔除不能发芽的红色种子和表面破损严重的种子, 但仍无法分选出籽粒饱满的微损伤棉种。 这类种子胚芽极易受损而无法发芽, 且因为表面破损容易因潮湿发霉变坏而不易存放, 影响种子发芽率。
高光谱成像技术在无损检测方面应用研究很多, 且前景广阔, 其特点就是高分辨率和多波段[1]。 将机器视觉技术和光谱成像技术相结合, 可以将光谱数据和图像数据的兴趣目标同时提取, 获取更全面的信息进行分析检测[2]。 吴翔等[3]提出一种基于近红外(874~1 734 nm)高光谱技术实现玉米种子可视化识别的方法; 张初等[4]以四种西瓜种子为研究对象, 结合高光谱成像技术和极限学习机判别分析方法, 实现品种快速鉴别; Kong等[5]采用高光谱成像技术, 利用建模方法对四类杂交水稻种子进行区分。 研究表明, 高光谱成像技术对目标分类是可以实现的, 但对微破损棉种快速可视化识别尚未有相关研究。 对棉种进行精密分选以保证种子发芽率是棉花精量播种技术推广的前提, 因此定位并发现微破损棉种十分重要。
研究的主要目的是结合近红外高光谱成像和图像处理技术, 对未破损和微破损的棉种进行可视化识别, 为进一步开发棉种在线精选装备提供理论方法和依据。
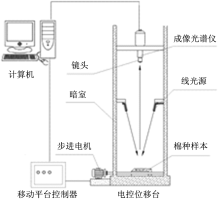
实验所用的高光谱成像系统, 由线光源、 近红外高光谱成像仪、 成像镜头、 电控位移台、 计算机和暗室等部分构成, 其示意图如图1所示。
 | 图1 高光谱成像系统示意图Fig.1 Schematic diagram of the hyperspectral image system |
其中线光源为Fiber LiteIlluminator(DolanJenne公司, 美国); 成像高光谱仪为ImSpector N17E(Spectral imaging 公司, 芬兰), 光谱范围是874~1 734 nm共256个近红外波段, 光谱图像分辨率为672× 512像素, 分辨率为2.8 nm; 成像镜头为OLES23, 电控位移台为IRCP0076(Isuzu Optics公司, 中国台湾)。
样品为新疆石河子市棉种公司加工的陆地棉新71号种。 取未破损和微破损的棉种样本各540粒, 划分为建模集405粒, 预测集135粒。 将未破损和微破损的棉种类别分别赋值为1和2, 如表1所示。
| 表1 样本划分 Table 1 Sample classification |
在高光谱图像信息采集之前, 首先通过调节图像的清晰度、 光源的强度以及图像的失真度进行仪器交叉校正, 其中图像的清晰度与图像的失真情况受物距、 平台移动速度和曝光时间的影响。 为确保采集到清晰、 不失真、 不变形的高光谱图像, 需要进行参数最优化设置。 经多次调整后, N17E高光谱成像仪的参数分别设置如下: 图像分辨率为675× 512像素点, 样品到镜头的距离为18.5 cm, 曝光时间为3 000 μ s, 平台移动速度为1.8 mm· s-1, 总运行距离为400 mm。 将样本摆放在全黑低反射率的背景板上分批进行光谱扫描和采集光谱图像。
光谱图像校正是光谱图像处理之前必须要做的的工作, 通过光谱图像的黑白校正消除因镜头和线光源产生的噪音。 采用 ENVI4.6 软件对矫正后的光谱图像进行感兴趣区域(ROI)提取, 以棉种质心为坐标提取棉种矩形ROI, 计算矩形ROI内所有像素点的平均值作为该样本平均光谱并保存在矩阵中以备计算。
由于光谱数据会受到谱线平移、 高频随机噪声和光散射等因素的干扰, 所以在光谱分析之前需要对原始光谱数据进行预处理以去除噪声, 提高模型预测效果。 采用平滑算法(Savitsky-Golay, SG)[6]对光谱数据预处理, 选择多项式次数为2, 平滑窗口大小为7, 对原始光谱进行去噪处理。
基于全部光谱数据建模, 数据量往往较大, 存在着大量的冗余和共线性数据, 不利于光谱有效信息的提取, 影响模型效果。 因此为减少数据计算量, 降低模型复杂度, 需要找到与表皮微破损的棉种相关性更强的特征波段。 故采用了二阶导数光谱法(second derivative spectra, 2nd spectra)[7]、 主成分分析载荷法(principal component analysis loadings, PCA-loading)[8]和连续投影算法(successive projections algorithm, SPA)[9]等三种方法提取特征波长。
2nd spectra法利用导数消除光谱其他背景的干扰, 提高光谱分辨率, 突出光谱中的有用信息。 利用导数光谱中的峰和谷所代表的非背景有用信息, 通过计算峰谷差异, 找到不同样本光谱在峰谷处存在最大差异, 并选择作为特征波长。
PCA-loading法可以反映主成分与原光谱波长之间的相互关联程度, PCA-loading值越大, 表明其所对应的波长越重要。 首先确定不同主成分的贡献率, 然后确定基于累积贡献率的主成分个数, 最后设定阈值, 并以波长载荷图为基础选择出波峰或波谷作为特征波长。
SPA法是前向特征变量选择方法。 利用向量的投影进行分析, 通过不同波长之间投影, 比较其投影向量的大小, 并以投影向量最大的波长作为待选波长, 以校正模型选择最终的特征波长。 设置特征波长数的选择范围为5~30, 输入建模集光谱Xcal和类别赋值Ycal, 根据RMSE最小的原则选取特征波长。
基于全谱数据和三种特征波长提取方法所选择的特征波长分别建立偏最小二乘判别分析(partial least squares-discriminant analysis, PLS-DA)[10]模型、 K最邻近判别法(k-nearest neighbor, KNN)[11]模型和支持向量机(support vector machine, SVM)[12]模型用于微损棉籽的检测。
PLS-DA在 PLS 回归模型基础上, 建立光谱数据X和类别值Y之间的回归模型, 对预测集进行预测。 阈值设置为0.5, 即判断预测值和实际值之间差的绝对值是否小于 0.5, 如是为预测正确, 反之则为预测错误。
KNN算法是为了解决最邻近法误判率较高的问题, 它最大优点是不需要训练集的几类样本是线性可分的, 也不要求单独的训练过程, 而且能够处理多类问题, 因此应用较为方便。 本文中KNN算法的最邻近节点数从3~10进行寻优。
SVM方法的关键在于核函数的选择, 当选定具体的核函数之后, 考虑到已知数据存在一定的误差及推广性问题, 实际中常常引入松弛系数以及惩罚系数两个参变量来加以修正。 本工作SVM模型的参数惩罚系数c寻优范围为2-8~28, 核函数选择RBF, 核函数宽度γ 寻优范围为2-8~28。
实验采集的近红外光谱共256个波段, 波长在874~1 734 nm范围内, 由于环境和仪器的影响, 获取的光谱前后端有较为明显的噪声, 因此去除原始光谱的前后端噪声明显的部分, 选择955~1 659 nm波长范围进行分析。 样本955~1 659 nm范围的原始光谱如图2所示。
 | 图2 切除两端噪声后的全部光谱(a)和平均光谱(b)Fig.2 The spectra after removing both two ends (a) and average spectra (b) |
从原始光谱看出, 未破损棉种和微破损棉种的光谱没有明显差异。 在1 150~1 300和1 450~1 600 nm处存在差异, 但仍无法将未破损与微破损棉种直接区分开来。
利用主成分分析(PCA)法对棉种光谱信息进行分析, 得到前三个主成分PC1, PC2和PC3的的贡献率分别为93.94%, 4.13%和1.03%, 累计贡献率达99.10%, 可以解释绝大部分变量。 PC1和PC2的得分图以及PC1, PC2和PC3的得分图如图3所示。
 | 图3 PC1和PC2主成分得分图(a)和 PC1, PC2和PC3主成分得分图(b)Fig.3 Scores scatter plots of PC1 and PC2(a) and PC1, PC2 and PC3(b) |
由图3可知, 未破损棉种和微破损棉种的得分图重叠在一起的情况较多, 因此仅仅通过PCA, 很难直接将其区分开来。 需要将光谱数据进行进一步的处理和分析, 以识别微破损棉种。
首先使用Kennard-Stone(KS)算法[12]对训练集样本进行划分, 把未破损棉种和微破损棉种的样本分别当作训练集候选样本, 通过迭代将具有最大和最小欧氏距离的候选样本选入训练, 以保证训练集样本能够按照空间距离均匀分布, 然后对训练集进行SG平滑处理, 并将建模集样本的光谱数据X和类别赋值Y作为输入, 分别采用2nd spectra方法、 PCA-loading方法和SPA方法选取特征波长。 三种方法特征波长选择过程如图4和表2所示。
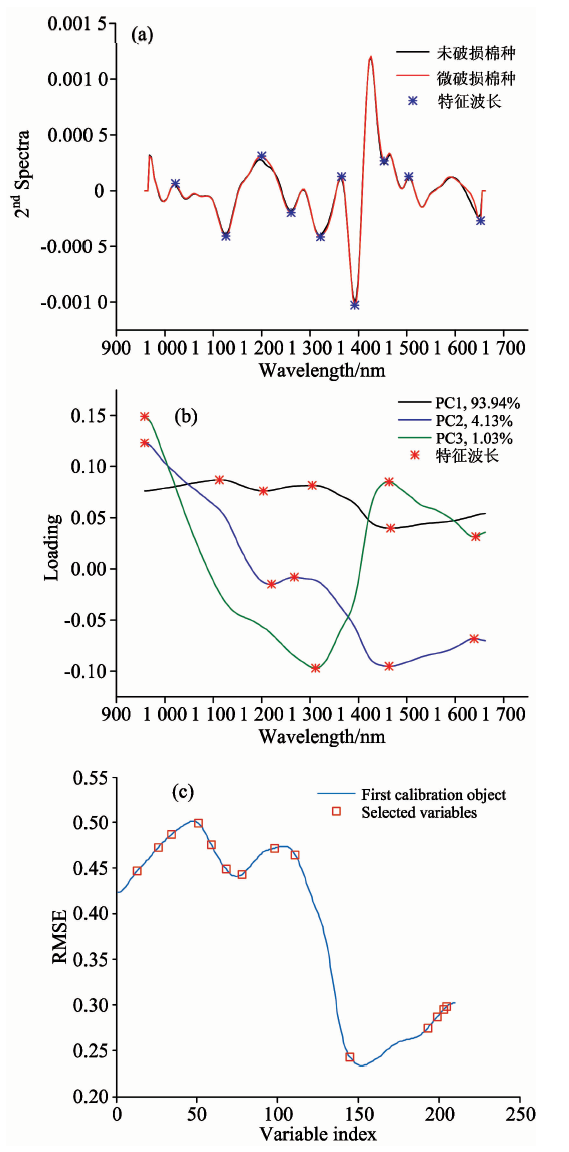 | 图4 基于2nd spectra(a), PCA loadings(b) 和SPA(c)选择特征波长的过程Fig.4 The optimal wavelengths selected by 2nd spectra, PCA loadings and SPA |
| 表2 对建模集提取的特征波长 Table 2 Optimal wavelengths of calibration set |
基于选择的特征波长, 分别建立PLS-DA, KNN和SVM判别分析模型。 这些模型基于不同的原理, 从不同的角度对光谱数据进行分析, 比较分析结果, 从中选择出合适的模型, 有助于实现微破损棉种的可视化识别。 不同模型的分析结果如表3所示。
| 表3 不同模型的判别分析结果 Table 3 The results of the different models |
综合比较PLS-DA模型、 KNN模型和SVM模型的分析效果可知, 基于全谱数据和基于所选择的特征波长建立的分析模型, 建模集和预测集判别准确率均达到70%以上, SPA-PLS-DA模型的判别效果最佳, 建模集和预测集的判别准确率分别为91.50%和90.33%。
从特征波长选择方法角度分析, 基于SPA选取的特征波长建模分析的准确率最好, 建模集和预测集的准确率均达到80%以上, 基于2nd Spectra选取的特征波长建模分析的准确率最差, 建模集和预测集的准确率最高仅77%; 从建模方法的角度分析, PLS-DA模型效果最好, 除2nd Spectra选取的特征波长外, 建模集和预测集的准确度均超过82%, KNN建模的效果最差, 建模集和预测集的准确率除SPA外, 都没有超过80%。 试验结果表明, 基于SPA选取的特征波长, 使用PLS-DA进行建模, 得到建模集和预测集的准确率较高, 可以用在微破损棉种可视化识别中并有效的实现微破损棉种的识别。
使用全部光谱数据分析, PLS-DA模型效果较好, 建模集和预测集的判别准确率分别为91.11%和88.00%, 效果优于2nd Spectra和PCA-Loading方法选择出的特征波长; KNN模型全谱数据分析效果较差, 判别准确率低于特征波长; SVM模型全谱数据分析效果优于2nd Spectra和PCA-Loading方法选择出的特征波长, 但低于SPA方法选择出的特征波长。 整体来看, 基于全谱数据分析的判别效果低于基于特征波长的判别分析效果, 且数据量相对较大, 模型计算的时间和空间效率较低。
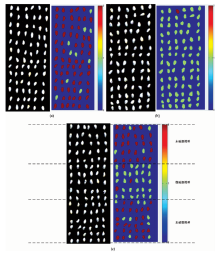
分别采集未破损棉种样本高光谱图像、 微破损棉种样本高光谱图像以及混合未破损和微破损高光谱图像。 首先提取样本高光谱图像中每颗棉种的平均光谱, 并输入所建立的SPA-PLS-DA模型, 识别结果用不同的颜色进行标定。 以深蓝色为背景, 深红色为未破损棉种, 浅绿色为微破损棉种, 生成对应的可视化识别图。
对三份棉种样本进行可视化识别, 识别的结果如图5所示。
 | 图5 无破损棉种(a)、 微破损棉种(b)和混合棉种(c)三类棉种样本的可视化识别图Fig.5 Visual identification maps of undamaged cotton seeds (a), slight-damaged cotton seeds (b) and the mixture undamaged and slight-damaged of cotton seeds (c) |
图5(a), (b)和(c)中左图为样本在波长为1 220.39 nm处的高光谱灰度图像, 右图为对应的识别图。 图5(a)中为未破损样本, 总共78颗棉种, 正确识别68颗, 识别率为87.18%; 图5(b)中为微破损样本, 总共84颗棉种, 正确识别83颗, 识别率为98.81%; 图5(c)中为未破损和微破损棉种的混合样本, 其中前5行和后6行为未破损棉种, 共66颗, 中间5行为微破损棉种, 共30颗, 未破损棉种正确识别53颗, 识别率为80.30%, 微破损棉种正确识别27颗, 识别率为90%。
由三组可视化识别结果可知, 单独对未破损和微破损棉种样本进行可视化识别比对混合样本的识别率较高, 排除图像分割算法和图像预处理算法效果影响, 所取得的识别率可以很好的发现并能够准确定位未破损棉种。
以棉种为研究对象, 采用近红外高光谱成像技术, 实现了微破损棉种的可视化识别。 分别采用2nd spectra, PCA-loading和SPA三种方法提取特征波长, 建立PLS-DA, KNN, SVM三种模型, 并利用这三种模型对三种方法提取的特征光谱和全谱进行分析, 结果表明, 基于SPA方法提取的特征波长的PLS-DA模型优于其他, 建模集和预测集的总体鉴别率可达91.50%和90.33%, 最终确定SPA-PLS-DA作为选定模型, 结合图像处理技术, 实现可视化识别微破损棉种并取得了较高的识别率。 为进一步开发棉种在线精选装备提供了理论方法和依据。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|