
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱参数和逐步判别的苎麻品种识别
[曹晓兰1, 2  , 陈星明
, 陈星明2 , 张帅2 , 崔国贤1, * ]
, 陈星明]
|
|


作者简介: 曹晓兰, 女, 1972年生, 湖南农业大学信息科学技术学院副教授 e-mail: cxl@hunau.net
为了探讨基于高光谱的苎麻品种识别和分类的方法, 在大田栽培条件下, 采集了4个不同基因型苎麻品种共927个叶片高光谱数据。 根据苎麻叶片高光谱反射曲线, 选择了2组特征参数: 基于高光谱波形峰谷反射率和位置参数(V1组)、 基于偏度和峰度参数(V2组)。 运用逐步判别的方法, 通过设置不同F值筛选不同个数的变量, 分别建立基于2组特征参数的多个Fisher线性判别函数, 并从计算量、 正确率和稳定性三方面对所建立的判别函数进行分析比较。结论:(1)所有组合的判别函数总体平均正确率为91.1%, 标准差总体均值为1.2%; (2)综合权衡, 在所有组合中, V2组且14≥变量个数 n≥8判别效果最好——计算量中等, 正确率和稳定性均高于平均值, 其中, 13个变量的Fisher判定函数平均正确率最高有94.2%, 标准差最低为0%; (3)若优先考虑正确率, V1组且22≥变量个数≥15正确率最高, 平均正确率最大有95.5%, 但计算量比较大, 稳定性中等, 标准差最低为0.9%。 研究表明, 利用高光谱参数结合逐步判别方法识别苎麻品种是可行的。
The hyperspectral data on total 927 leaves of different genotypes, which come from 4 ramie varieties, were collected under the field cultivation conditions to explore the identification and classification of ramie varieties with the hyperspectral as the basis. According to the hyperspectral reflection curve of ramie leaves, two groups of feature parameters were extracted, namely, the hyperspectral wave-valley reflectance and position parameters(the group V1) as well as the skewness and kurtosis parameters(the group V2) . Then, by adopting the stepwise discriminant approach to screen different number of variables under different F-value settings, multiple Fisher linear discriminant functions based on these two groups of feature parameters were created respectively, and further, the created discriminant functions were comparatively analyzed from the computational complexity, the accuracy and the stability. So, we can come to the following conclusions: (1) For discriminant functions under all the combinations, the overall average accuracy was 91.1% and the overall standard deviation mean was 1.2%; (2) From the comprehensive trade-off perspective, when the number of variables was between 8 and 14, the discriminant effect of the group V2 was the best among all the combinations, namely, the computational complexity was in the middle level, and both the accuracy and the stability were over their corresponding average values; among them, the discriminant functions with 13 variables had the highest average accuracy and the lowest standard deviation, which were 94.2% and 0% respectively; (3) When the accuracy was considered preferentially and the number of variables changed between 15 and 22, the group V1 had the highest accuracy which was 95.5%, however, the computational complexity under this case was higher, the stability was in the middle level and the lowest standard deviation was 0.9%. Above results showed that it was feasible to utilize the hyperspectral parameters together with the stepwise discriminant approach.
高光谱数据具有分辨率高、 波段连续性强、 信息量大、 支持波形分析技术等优势。 研究作物高光谱特性, 有助于更好地揭示作物的本质属性。 在农业领域的应用取得较大进展, 基于高光谱的作物分类与识别是一个重要的研究方面[1]。 基于高光谱的作物分类与识别模型的建立主要有两个关键步骤: 一是高光谱数据的降维, 即特征参数的选取; 二是分类识别算法的选择。 刘瑶等用主成分分析提取特征参数, 选择极限学习机和随机森林算法对大豆品种进行识别[2]; 臧卓等用主成分分析进行降维, 选择基于径向基核函数和基于线性核函数的支持向量机、 BP神经网络和Fisher分类法四种算法对乔木树种进行分类[3]; 史飞飞等对光谱数据进行一阶求导等6种数学变换之后, 在绿峰、 红谷等区域提取了特征参数, 建立了大豆等5种作物的BP神经网络识别模型[4]; 王岽等选取了光谱位置参数、 植被指数和光谱面积等14个高光谱特征参数, 建立了BP神经网络的农作物识别系统[5]; 程术希等通过载荷系数选取10个品种大白菜种子的特征波长, 比较了Ada-Boost算法、 极限学习机、 随机森林和支持向量机四种分类算法的分类判别效果; 柴颖等分析湿地植被的一阶微分光谱和光谱吸收特征, 利用逐步判别法筛选光谱特征参数参与C4.5决策树分类[6]。
苎麻起源于中国, 是我国古老的纤维作物[7]。 当前, 苎麻种质资源分类研究工作主要基于植物形态、 产量和品质等方面展开, 基于高光谱特性的识别与分类的相关研究几乎没有, 因此, 深入研究苎麻高光谱特性, 并以此为基础, 对不同基因型苎麻品种进行识别分类, 有利于苎麻属植物分类的深入研究和进一步开发利用。 采集了四种不同基因型苎麻品种叶片高光谱数据, 选择其峰谷反射率和位置(V1)、 偏度和峰度(V2)两组特征参数作为变量, 用逐步判别分析的方法, 分别建立基于高光谱的苎麻识别模型, 并从计算量、 正确率和稳定性三方面对模型做了比较, 在基于高光谱的苎麻品种识别与分类方面做了一定探索。
数据采集设备选用美国ASD公司生产的FieldSpec 3便携式地物光谱仪和配套的叶片夹持器。 光谱仪波段范围350~2 500 nm; 光谱分辨率为3 nm@350~1 000 nm, 10 nm@1 000~2 500 nm; 采集频率15次· s-1, 每隔20~30 min左右做一次OPT(optimize instrument setting)优化和白板校正。
数据采集于2016年11月初在长沙县梅花基地苎麻种质资源圃(28° 07'59.217″N, 113° 17'46.113″E)进行, 各品种统一施肥和管理。 采集时, 选择苎麻植株中上部发育成熟的叶片, 避开叶脉, 将叶片夹持器夹紧叶片所测部位进行测定。 采集的苎麻品种和数据个数分别是: 双峰大叶麻A1(196个)、 沅江黄壳早A2(317个)、 湘潭鸡骨白A3(198个)和平塘大刀麻A4(216个)。 所有的数据均做了跳跃点校正之后再做其他处理与分析。
1.2.1 峰谷反射率和位置
受色素成分、 细胞结构和含水量等生理特征影响, 在不同的波段, 植物叶片对光的反射和吸收强度不同, 从而形成植物特有的反射峰和吸收谷。 典型的绿色植物光谱特征为: 在400~700 nm可见光波段, 有明显的绿峰和红谷; 700~780 nm波段, 是一个明显的高反射平台过渡波段, 即红边; 780~1 350 nm与叶片内部结构有关的波段, 在970和1 200 nm附近有两个微弱的吸收特征; 1 350~2 500 nm波段, 在1 450和1 940 nm附近形成2个强吸收谷, 在1 650和2 200 nm附近形成2个反射峰[1]。
对采集的所有数据取均值, 得到苎麻叶片平均高光谱反射波形(图1)。 从图1中可知, 苎麻叶片的高光谱曲线符合绿色植物光谱特征。 根据苎麻叶片高光谱反射曲线特征, 选择包括绿峰、 红谷在内的12个明显峰、 谷, 分别计算各高光谱样本数据波形的峰(或谷)最大(或最小)反射率及其中心波长位置, 作为一组特征参数(V1组)。 各峰谷命名如图1所示。
 | 图1 苎麻叶片高光谱反射曲线峰谷选择Fig.1 Selecting peaks and valleys on the ramie leaf hyperspectral reflectance curve |
1.2.2 反射峰偏度峰度
偏度和峰度反映了数据分布对称程度和峰值高低, 可以更全面了解数据分布形态: 如果一组数据的分布是对称的, 则偏度系数为0; 如果一组数据服从标准正态分布, 则峰度系数为0。 对于未分组数据, 偏度和峰度的计算公式如下[8]
式中: n为变量个数, xi为变量x的第i个观测值,
根据苎麻叶片平均高光谱反射波形, 计算上述各个吸收谷的中心位置, 以相邻两个吸收谷为界, 将整个波形划分成n1~n7, 共7个波段(表1)。 分别计算七个波段的偏度和峰度, 作为第二组特征参数(V2组)。
| 表1 波段范围 Table 1 The range of wavebands |
逐步判别分析从模型中没有变量开始, 每一步都对模型进行检测, 把模型外对模型的判别力贡献最大的变量加入到模型中, 同时把已经在模型中但又不符合留在模型中条件的变量从模型中剔除, 直到模型中所有变量都符合留在模型中的判据、 模型外的变量都不符合进入模型的判据时为止[9]。 一个变量能否被选择为变量子集的成员进入模型主要取决于协方差分析的F检验的显著性水平: 当F值大于指定的进入值时, 该变量保留在函数中; 当某变量使计算的F值小于指定的删除值时, 该变量从函数中剔除。 F值设置不同, 进入的变量个数不同, 对最后的判别结果会有很大影响。 因此, 需要选择合适的F值, 以达到用最少变量获得最佳判别的效果。
对每个品种的高光谱数据按2∶ 1比例随机分成建模集(共618个数据)和预测集(共309个数据)。 在建模集, 分别输入V1, V2两组特征参数进行逐步判别分析。 判别方法统一采用Wilks’ Lambda, 设置不同F值筛选不同个数的变量, 建立多个Fisher判别函数模型。 然后用所建立的模型, 对预测集数据分别进行预测, 对比各个Fisher判别函数效果。
从计算量、 正确率和稳定性三方面对建立的模型进行评价: 计算量是指Fisher判断函数的变量个数x, x越大计算量越大, 反之计算量越小; 正确率是以建模集和预测集二者平均正确率是否≥ 总体平均正确率为标准, ≥ 则准确性为“ 高” , < 则为“ 低” ; 稳定性是以每个组合建模集与预测集的平均标准差是否≤ 总体平均标准差为标准, 若≤ 则稳定性为“ 高” , 否则为“ 低” 。
(1)所有组合在建模集和预测集的总体平均正确率为91.1%(表2)。
| 表2 不同特征参数组及变量个数判别正确率(%) Table 2 The percentage of correct discriminant statistics for different feature parameter groups and variable numbers (%) |
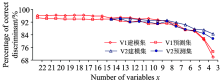
(2)从图2可知, 变量个数x减少时, 无论V1组和V2组的判断正确率均呈现下降趋势。 但并非变量数最多正确率就最高, 如V1组建模集在变量个数为17, 18和20时达到最高正确率96.3%; V2组建模集、 预测集与平均正确率都是在变量个数为13时达到最高正确率94.2%。
 | 图2 两个特征参数组及不同参数个数的判别正确率Fig.2 The percentage of correct discriminant for two feature parameter groups and different variable numbers |
(3)结合图3和表2可以知道: 变量组X1(22≥ x≥ 15)中, 变量个数的减少对V1组正确率影响不明显, 曲线比较平滑, 平均正确率最高有95.5%; 变量组X2(14≥ x≥ 8)中, V1和V2组平均正确率相差不明显, 两组最高平均正确率均为94.2%, 且均是随着变量个数减少正确率略有减少, 曲线略呈下降趋势; 变量组X3(7≥ x≥ 3)中, V2组平均正确率略高于V1组, 两组的正确率均随着变量个数减少而明显减小, 且V1组下降趋势比V2组显著。
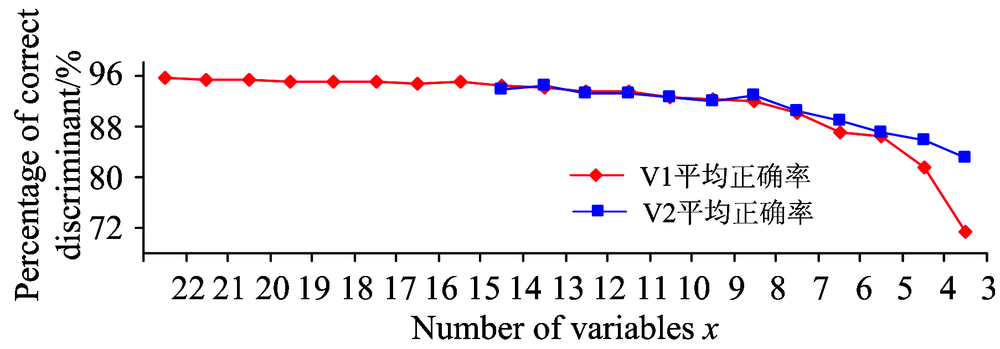 | 图3 平均正确率Fig.3 The average percentage of correct discriminant |
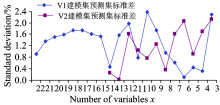
(4)所有组合标准差总体均值W为1.2%。 各组合标准差如图4所示:
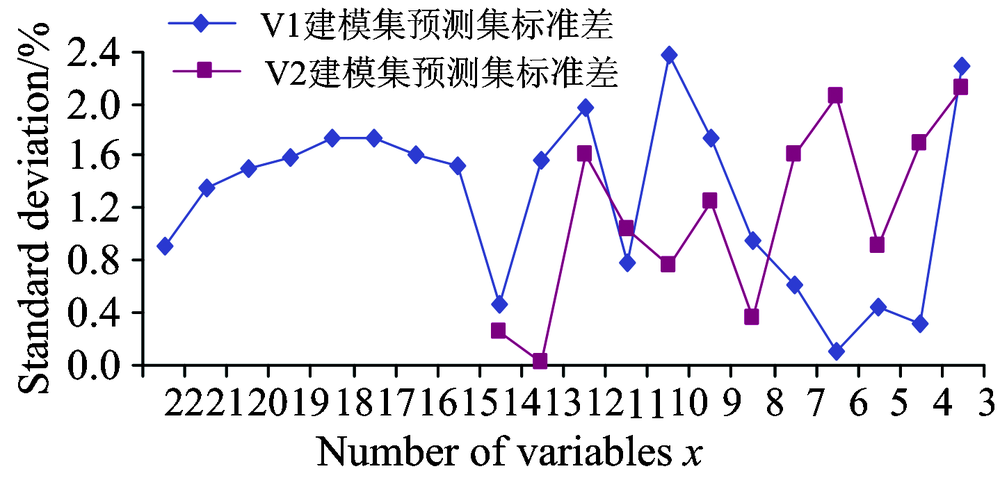 | 图4 建模集与预测集标准差Fig.4 The standard deviations for the modeling set and the prediction set |
① X1组中, V1组平均标准差为1.5%, 只有变量个数为22的组合标准差小于W, 为0.9%, 占该组总组合数的12.5%。
② 在X2组中, V2组标准差整体小于V1组— V1组平均标准差为1.4%, V2组平均标准差为0.8%, 这表明V2组建立的模型稳定性更好。 V2组中变量个数为13的标准差为0%, 小于等于W的组合有6个, 占该组总组合数85.7%; V1组中变量个数为14的标准差最小, 为0.5%, 小于等于W的组合有3个, 占该组总组合数42.9%。
③ 在X3组中, V1组标准差整体小于V2组— V1组平均标准差为0.8%, V2组平均标准差为1.7%, 说明V1组建立的模型稳定性更好。
(5)模型判别效果进行比较。 根据变量个数, 设X1组计算量为“ 高” , X2组计算量为“ 中” , X3组计算量为“ 低” ; 每个组合, 若平均正确率≥ 总体平均正确率91.1%, 则准确性为“ 高” , < 则为“ 低” ; 每个组合, 若平均标准差≤ 总体平均标准差1.2%, 则稳定性为“ 高” , 否则为“ 低” , 比较结果见表3。
| 表3 判断模型综合评价 Table 3 The comprehensive evaluation of the discriminant model |
从表3可知, 采用V2组— — 即偏度峰度作为特征参数, 变量个数组选择X2, 即8~14个变量, 得到的Fisher判断模型计算量中等, 正确性和稳定性都高, 因此综合评价最高。 如果优先考虑正确率, V1组X1变量组正确率最好, 其中以22个变量时最佳, 平均正确率高达95.5%, 标准差为0.9%。
限于篇幅, 仅给出V2组选择13个参数的Fisher判别函数系数(表4), 该函数建模集与预测集正确率均为94.2%; 标准差为0%。
| 表4 基于偏度和峰度的Fisher判别函数系数(13个变量) Table 4 The coefficients for the Fisher discriminant function based on skewness and kurtosis (13 variables) |
旨在探寻用高光谱参数建立苎麻品种识别的判别模型, 结果表明该方法是可行的。 在建立模型时, 根据需求, 注意综合考虑计算量、 正确率和模型的稳定性, 权衡利弊, 尽量用最小计算量获得最佳、 最稳定的判断结果。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|