

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于卷积神经网络与光谱特征的夏威夷果品质鉴定研究
[杜剑1, 2  , 胡炳樑
, 胡炳樑1, * , 刘永征1 , 卫翠玉1 , 张耿1 , 唐兴佳1 ]
, 胡炳樑, 刘永征|
|


作者简介: 杜 剑, 1991年生, 中国科学院西安光学精密机械研究所博士研究生 e-mail: dujian@opt.cn
夏威夷果含油量高, 在开缝之后容易发生变质, 现有关于夏威夷果品质鉴定的方法多为传统的破坏性检验, 很难满足无损检测的需求。 卷积神经网络(CNN)作为应用最广泛的深度学习网络模型之一, 具有比浅层学习方法更强的特征提取与模型表达能力, 在光谱数据方面的应用拥有很大潜力。 基于夏威夷果在可见-近红外的光谱特征分析, 研究用于提取夏威夷果光谱特征的卷积神经网络模型, 并提出一种高效无损鉴定夏威夷果品质的方法。 首先以三种不同品质的夏威夷果(好籽、 哈籽及霉籽)为研究对象, 分析样本在500~2 100 nm的光谱信息; 在光谱数据预处理中引入白化处理方法, 用以增强数据的相关性差异; 然后在模型训练过程中, 将样本随机分为训练集和预测集, 探讨不同CNN结构、 卷积层数、 卷积核大小及个数、 池化层类型、 全连接层神经元个数以及激活函数对分类结果的影响, 并采用激活函数ReLU和Dropout方法, 预防样本数据过少引起的过拟合现象; 最后通过分析模型分类准确率和计算效率, 确定了一个6层结构的CNN模型: 输入层—卷积层—池化层—全连接层(200神经元)—全连接层(100神经元)—输出层。 实验结果表明: 上述网络模型对校正集和预测集的分类准确率均达到100%。 因此, 改进后的卷积神经网络模型可充分学习夏威夷果的光谱特征并有效分类, 将深度学习理论与光谱分析相结合的方法能够实现对夏威夷果品质的准确鉴定, 同时为夏威夷果等坚果类食品的高效、 无损、 实时在线检测提供了新思路。
Macadamia nut is easy to spoil after being stripped off because of the high level of oil in it. Most of the existing traditional methods are destructive which are difficult to satisfy the demand of non-destructive detection. As one of the widely used deep learning models, convolutional neural network (CNN) has stronger capabilities of feature extraction and model formulation than shallow learning methods and great potential for the application of spectral data. We studied suitable CNN architecture to extract spectral features of Macadamia based on Vis-NIRS analysis, and proposed an efficient non-destructive method to identify the quality of Macadamia. At first, we took three kinds of macadamia nut with different qualities (including better nut, worse nut and moldy nut) as the research object and analyzed the spectral information in the wavelength range of 500~2 100 nm. We introduced the concept of whitening in data preprocessing to strengthen the correlation difference. In the process of model training, we divided the sample into training set and prediction set randomly and then discussed the effects of different structure parameters, such as the number of convolution layer, size of convolution kernel, pooling type, number of neuron in full connection layer and activation function. We applied ReLU and Dropout to prevent over-fitting caused by lack of data. At last, through the analysis of the classification accuracy and computational efficiency, a CNN model of 6-layer structure was established: input layer-convolution layer-pooling layer-full connection layer(including 200 neurons)-full connection layer(including 100 neurons)-output layer. The results show that the final classification accuracy of the calibration set and prediction set reached 100%. This improved CNN model can fully learn the spectral features of macadamia and classify effectively. The combination of the deep learning theory and the spectral analysis method can identify the quality of macadamia accurately, and provide a new idea for the efficient, non-destructive, real-time, online detection of macadamia and other nuts.
夏威夷果近年来风靡各地, 其销量在坚果类食品中一直处于前列, 拥有广阔的市场前景与研究价值。 其果仁质地细腻, 香味独特, 口感风味极佳, 是世界上品质最佳的食用干果, 具有很高的经济价值、 营养价值和药用价值, 享有“ 干果之王” 的美誉[1]。 通常为了后期加工以及食用方便, 商家会在果壳上切开一条裂缝, 但由于夏威夷果中富含不饱和脂肪酸, 易于氧化变质, 在温度湿度变化的情况下, 可能会导致夏威夷果品质下降, 口感异常甚至变质。 而夏威夷果的初期变质通常发生在果仁内部, 仅从果实外表很难肉眼判断, 现有的品质鉴定方法大多为有损检测, 无法满足工业化检测需求。 因此研究一种简单高效、 非破坏的夏威夷果品质鉴定方法显得尤为迫切。
光谱技术是近些年来发展较快的分析方法之一, 具有安全快速、 无损高效、 信息丰富等优点, 能够利用所测波段的光谱特性对物质进行定性定量分析, 已在果实内部品质的无损检测方面得到了广泛应用[2, 3, 4, 5, 6], 同时结合光纤探头还可以用于食品的在线检测。 目前将光谱技术用于夏威夷果品质鉴定的相关研究还未见报导, 仍处于初步的摸索阶段。
近年来随着模式识别与机器学习的发展, 深度学习(deep learning)[7]已成为人工智能研究的一大热点。 深度学习模型拥有更多隐层, 包含了更多非线性变换, 通过逐层学习来获得特征的非线性表达, 其模型结构模拟人脑, 可自动学习数据的本质特征, 避免了复杂的特征提取和数据重建过程, 增强了拟合复杂模型的能力。 深度学习模型通常以原始数据作为输入, 然后将当前层输出作为下一层的输入, 逐层堆叠, 最后得到更高级的特征表示, 从而能够刻画更复杂的数据结构。 卷积神经网络(convolution neutral network, CNN)[8, 9]是深度学习中重要的网络结构, 也是第一个真正意义上成功训练多层神经网络的学习算法, 它的权值共享理论(局部感受野)与真实的生物神经结构更加接近, 同时减少了网络参数的个数。
鉴于深度学习强大的特征表达能力, 本文在经典卷积神经网络模型的基础上, 根据夏威夷果光谱数据的特点改进CNN分类模型, 旨在研究一种无损高效的夏威夷果品质鉴定方法, 同时探索CNN模型应用于食品类光谱特征学习的最佳模式。
基于光谱数据的白化处理, 以及CNN建模分析, 构建夏威夷果品质无损鉴定算法。 由于原始光谱数据相邻波段之间通常有高度相关性, 为了消除相关特征对建模效率的影响, 首先需要对数据进行白化处理。 其次, 在数据量庞大的光谱信息中, 针对特定的问题需求, 应进行相应的光谱特征提取, 而CNN模型通过自主学习深层特征, 可以有效解决这一问题。
白化是将数据的协方差矩阵转变为单位矩阵的过程, 其作用主要是减少了特征之间的相关性, 并使得每个特征都具有相同的方差(协方差阵为1)。 夏威夷果光谱数据包含上千个波段, 进行白化操作可以降低数据复杂度, 增强后期算法收敛性。 白化的主要原理及实现步骤如下:
(1)对零均值化后的数据x构造自相关矩阵
由式(1)可看出Rx是对称矩阵且非负定(所有特征值都大于或等于0), 为了消除相关性, 需要寻找一个矩阵B对x进行线性变换, 即y=Bx, 使得
y的各分量是不相关的, 即E(yi yj )=δ ij, 这就是白化的过程, B称为空间白化矩阵。
(2)由式(1)可知, Rx存在特征值分解, 即Rx=Φ Λ Φ T, 其中Φ 是正交矩阵, Λ 是对角化矩阵, 其对角元素是Rx的特征值。 为了使对角元素单位化, 对B进行变换, 令B=Λ -1/2Φ T, 代入式(2)可得
由此可看出, 通过矩阵B的线性变换后, y的各分量不再相关, 特征方差单位化也就意味着各特征之间相互独立, 达到了消除原始光谱数据信息冗余的目的, 通过简化数据可以有效提高后期分类模型的准确率。
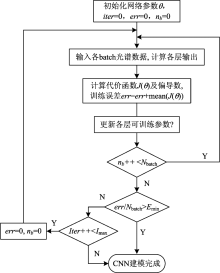
传统的SVM、 神经网络等模型已在光谱数据处理中得到了广泛应用, 而CNN的不同之处体现于更深的网络结构以及权值共享理论, 意味着在拥有更强大的特征提取与表达能力的同时, 还尽可能的降低了网络复杂度。 图1是CNN模型的基础结构, 通常CNN模型至少需要包含一个卷积层和池化层, 通过卷积层和池化层的组合来构建深度学习网络。 局部连接概念与权值共享理论是CNN的标志, 上一层神经元仅稀疏连接于下一层的神经元, 部分神经元也可以共享权值与偏置, 这样可以在提取到更抽象特征的同时, 尽可能的简化训练参数个数和网络结构。 图2为CNN对夏威夷果光谱数据建模流程图, 整个建模过程主要分为模型初始化和迭代训练两个部分:
 | 图1 CNN模型基础结构Fig.1 Fundamental architecture of CNN |
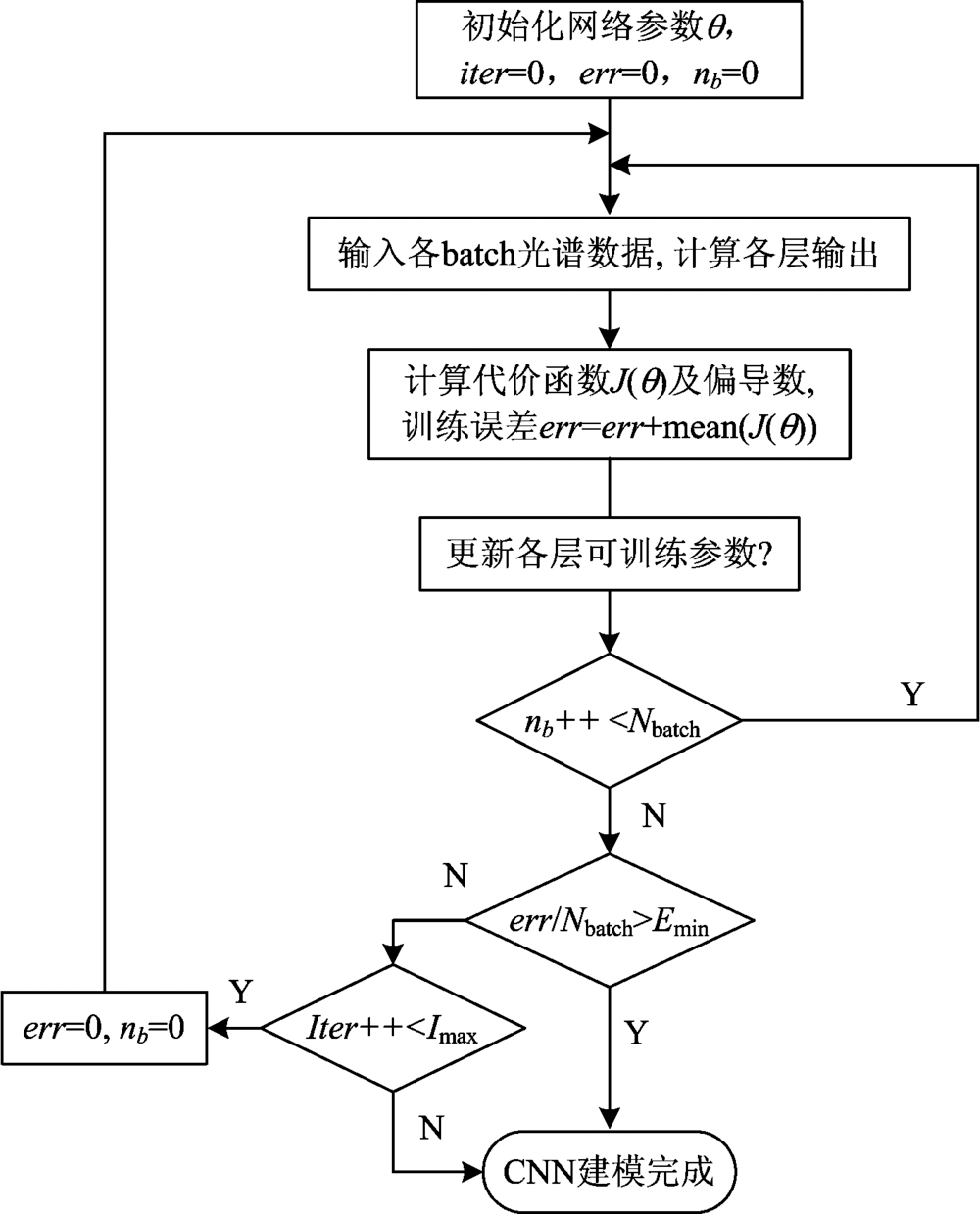 | 图2 夏威夷果光谱数据CNN建模流程图Fig.2 Flow chart of CNN modeling towards spectral data of Macadamia |
(1)初始化:
确定夏威夷果样本波段数n1(输入), 样本类别数np(输出), 迭代次数Imax, 学习率α 。 根据夏威夷果训练样本大小, 确定训练batch个数Nbatch, nb为当前batch数, iter为当前迭代数, err为当前训练误差, Emin为目标误差。 确定各层网络类型及激活函数, 随机初始化网络参数θ 。
(2)迭代训练:
步骤1: 依次将各batch光谱数据作为模型输入, 计算各层输出,

其中, Wi是第i层的权值矩阵, bi是偏置矩阵, xi是第i层输入, y预测了当前迭代中归属每一类的概率值。
步骤2: 计算代价函数J(θ )及其偏导数。
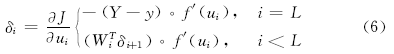
其中, m是训练样本数, Y是目标输出,
步骤3: 用梯度下降法更新参数θ ,
步骤4: 随着迭代次数的增加, 代价函数的返回值越来越小, 意味着当前输出逐渐接近目标输出。 判断训练误差与迭代次数, 当误差足够小时迭代停止, CNN模型训练完成, 否则返回步骤1继续迭代运算。
在实际应用中, 实验样本的光谱数据通常不易获取, 而训练样本的缺乏经常会导致过拟合, 表现为训练数据集的分类结果很好, 而预测集结果较差。 为了改善光谱数据维度较高与训练样本较少之间的不平衡, 本研究在CNN模型中采用rectified linear unit (ReLU)及Dropout方法。 其中, ReLU是一个非线性函数, 用来增强模型的表达能力, 同时可以加速收敛; Dropout将部分隐藏神经元置为零, 随机丢掉部分模型参数, 在不同的训练迭代中建立不同的网络模型, 适用于光谱数据高维输入的特征, 可以提高整个模型的鲁棒性。
本文基于卷积神经网络与夏威夷果光谱特征, 建立夏威夷果品质鉴定模型主要包含以下环节:
(1)利用光谱吸收指数与光谱角填图法对夏威夷果原始光谱进行分析, 并将霉籽从样本集中分出;
(2)对好籽与哈籽构建样本集, 采用白化等方法进行光谱预处理;
(3)以全谱段光谱数据作为输入, 训练CNN模型进行夏威夷果品质的分类鉴定。
实验所采用的材料样本均由三只松鼠公司夏威夷果分部提供, 实验前专家已对样本的品质(霉变程度)进行了鉴定并分类标记。 其中哈籽与霉籽样本较难获取, 因此实验样本集较小, 最终选取278颗夏威夷果组成样品集。 样本均为未加工的夏威夷果半成品, 大小形状基本一致, 沿果壳中轴线有一条长约半周宽约2 mm的裂缝。 根据样本霉变程度将其分为三组:
(1) 好籽组: 共128颗, 果实外壳表面光滑, 无霉菌生长痕迹, 果仁饱满可食用;
(2) 哈籽组: 共106颗, 果实外壳色泽较暗, 果仁有轻微变色, 不可食用;
(3) 霉籽组: 共44颗, 有明显霉菌生长在外壳表面, 果仁也覆盖了部分霉菌, 误食后对人体有害。
实验仪器选用美国ASD公司的FieldSpec@3型便携式光谱仪(350~2 500 nm), 共2 151个波段。 光谱仪的视场角为25° , 数据采集过程中保证光纤探头与样本垂直, 使样本裂缝开口正对于探头, 距离约2~3 cm, 确保采集到的是果仁光谱数据。 光源为两个100W白炽灯泡, 置于仪器两侧, 入射角度为45° 。 实验前先将仪器预热10 min, 为排除照明条件改变所带来的误差, 需每隔15 min重新优化一次, 每隔30分钟采集一次白板参比, 对每个样本扫描10次取平均值作为后续实验的采样光谱。 光谱数据采集完毕后, 将夏威夷果沿裂缝处剥开, 再次确认样本品质。
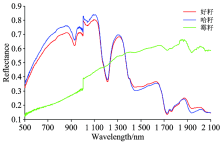
在进行光谱分析前, 首先剔除受噪声干扰较大的350~500和2 100~2 500 nm两个波段数据, 选取500~2 100 nm波段的光谱数据作为研究对象, 图3为夏威夷果的可见-近红外平均光谱曲线。
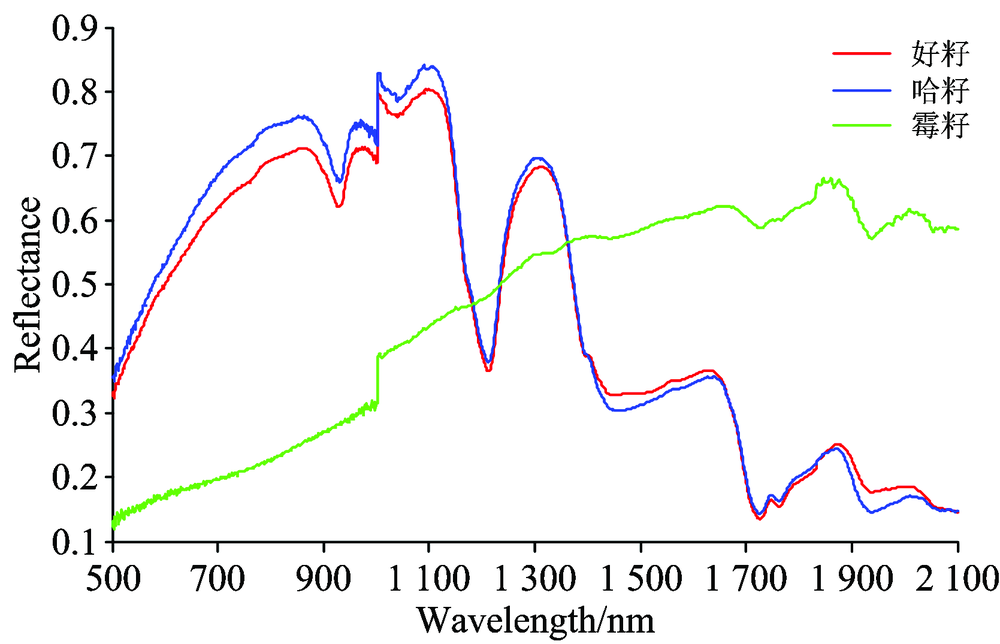 | 图3 夏威夷果平均光谱Fig.3 Average spectra of Macadamia nuts |
2.3.1 光谱吸收指数
从图中可以看出, 好籽组与哈籽组的趋势大致相同且无明显的变化规律, 这两组样本在930, 1 210, 1 730 nm附近出现了明显的吸收谷特征, 而霉籽组的光谱特征与这两组区别较大, 其原因主要是因为霉籽表面覆盖了一层霉菌, 遮住了大部分果仁, 实验所测数据更多反映了表面霉菌的光谱反射特征。 因此先将好籽与哈籽归为一组, 霉籽为另一组, 通过计算样本在以上三个波长的光谱吸收指数, 可以先将霉籽从样本集中分出。 光谱吸收指数(spectral absorption index, SAI)定量化描述了特定波段的光谱吸收特征, 其表示如下
其中, d为对称性参数, ρ m, ρ 1, ρ 2分别为吸收谷点与其两个肩部对应的光谱反射率。 表1统计了各类样本光谱吸收指数的最大值与最小值, 发现好籽、 哈籽组(SAI-1)的光谱吸收指数均大于霉籽组(SAI-2), 设定恰当的阈值t即可区分出霉籽。
| 表1 样本光谱吸收指数统计 Table 1 The statistics of spectral absorption index of samples |
2.3.2 光谱角填图
为了进一步分析样本的光谱特征, 以好籽的平均光谱为参考光谱, 计算各样本的光谱角, 分析三类样本之间的光谱相似性。 光谱角填图(spectral angle mapping, SAM)将光谱看作维数与波段数相等的空间向量, 通过计算两个光谱之间的角度确定两者相似度, 其计算公式如下
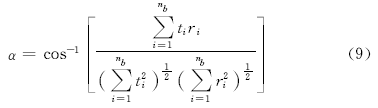
其中, t与r分别代表参考光谱与测试光谱。 表2统计了各样本光谱角的最大值与最小值, 可以看出霉籽样本的光谱角较大, 与其余两组差异很大, 而好籽与哈籽的光谱角相似, 对这两组很难通过直观方法直接进行区分, 需要结合更有效的光谱特征提取与分类方法, 实现对好籽与哈籽的分类鉴别。
| 表2 样本光谱角统计 Table 2 The statistics of spectral angle of samples |
基于前述对三类样本数据的SAI和SAM分析结果可知, 直接利用光谱吸收指数或光谱角进行阈值判断, 可以将霉籽与其余两类区分开, 但由于好籽与哈籽的光谱特征非常相似, 直接判断较为困难。 因此, 传统的光谱分析方法很难将两者准确区分, 需进一步进行处理分析。
首先对好籽与哈籽构建样本集(见表3)并进行白化处理, 消除光谱维度之间的相关性, 增强数据相关性差异; 然后进行光谱去噪处理, 采用多元散射校正(MSC)结合Savitzky-Golay一阶求导的方法, 用以消除高频噪声以及基线偏移的影响; 最后将数据输入CNN模型进行训练, 并对训练过程和结果进行讨论与分析。
| 表3 样本的训练集和预测集统计 Table 3 The statistics of training and prediction set of Macadamia samples |
光谱曲线特征其实与语音识别[10, 11]中的各类音频输入相似, 本文借鉴语音识别中的建模经验, 依据夏威夷果光谱数据特点建立具有针对性的分类模型(见图4)。 所用代码均基于Python语言的keras库编写完成, keras是近年来兴起的深度学习训练框架, 通过keras可以更高效的定义、 优化以及评估深度网络模型。
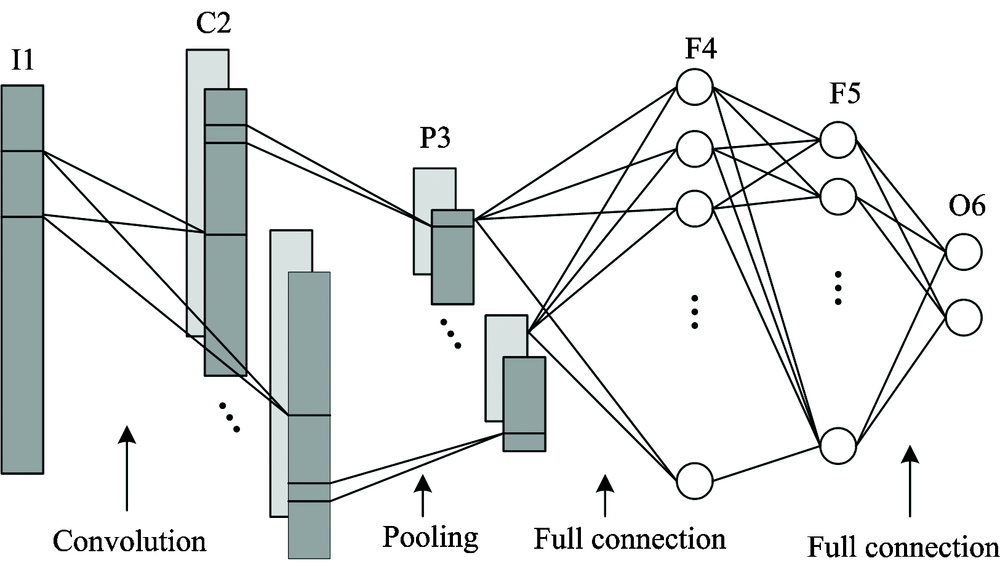 | 图4 CNN分类模型结构图Fig.4 The architecture of the proposed CNN classifier |
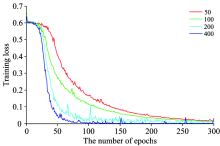
将预处理后的全谱段光谱数据作为模型输入, 其后连接卷积层、 池化层、 全连接层, 最后输出分类结果。 首先确定全连层个数, 当只有一个全连层时, 分别测试了包含50, 100, 200, 400个神经元的情况, 训练误差随迭代次数增加的变换趋势如图5所示。
 | 图5 不同神经元个数对应的训练误差比较Fig.5 Training errors with different numbers of neuron |
可以发现, 神经元较少时, 模型收敛速度较慢, 300次迭代后仍未收敛到最佳。 随着神经元个数的增加, 模型更为复杂, 收敛速度明显加快, 但同时训练时间也明显增加, 训练误差曲线波动较大。 因此无论神经元个数多少, 一个全连层的结构不能保证模型的稳定性和可靠性。 需要在输出层前再添加一个全连层, 两层的神经元个数分别确定为200和100, 这时收敛速度最快且最稳定。 在对其余网络层结构的选择时可以发现, 过大的池化长度、 过小的卷积核个数以及尺寸会导致收敛时间明显延迟, 训练误差曲线波动较大, 需要结合训练效率来考虑各层结构。
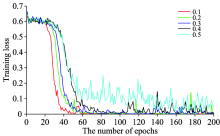
模型训练中采用了非线性函数ReLU以及训练策略Dropout, Dropout参数的选择对整个训练结果的影响较大。 分别测试了0.1~0.5共五种参数(见图6), 发现如果参数设置较大, 则收敛速度下降, 同时有过拟合的风险且影响整个模型的鲁棒性, 分类效果并不理想, 因此将Dropout设为0.1。
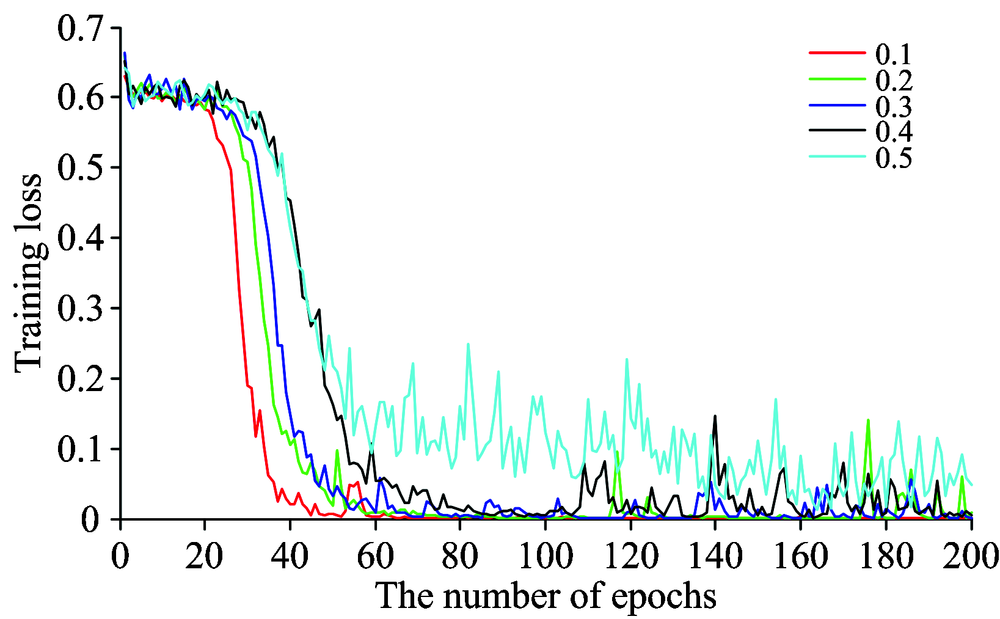 | 图6 不同Dropout值对应的训练误差比较Fig. 6 Training errors with different Dropout |
红色曲线即Dropout为0.1时的训练误差曲线, 其整体收敛较快, 迭代80次之后训练基本达到最优, 对校正集的分类准确率达到100%, 整体训练时长441 s, 最后对预测集54个样本进行验证, 预测准确率为100%, 分类时长0.03 s。 依此确定了实验最优CNN分类模型, 其具体结构如表4所示。
| 表4 夏威夷果CNN分类鉴定模型结构参数 Table 4 The specific parameters of the CNN classification model of Macadamia |
整个网络共包含6层, 包括输入层I1, 卷积层C2, 池化层P3, 全连接层F4, 全连接层F5以及输出层O6。 其中, 输入层大小为波段数n1=1 600; 卷积层C2包含7个大小为k1=10的卷积核, 本层共有7× n2个节点(n2=n1-k1+1), C2与I1之间共有7× (k1+1)个可训练参数; 池化层P3核大小k2=2, 共有7× n3个节点(n3=n2/k2), 没有可训练参数; 全连层F4有n4=200个节点, 与P3之间有(7× n3+1)× n4个可训练参数; 全连层F5有n5=100个节点, 与F4之间有(n4+1)× n5个可训练参数; 输出层O6有n6个节点, n6为分类数2, 与F4之间有(n5+1)× n6个可训练参数; 因此本文提出的CNN模型共有7× (k1+1)+(20× n3+1)× n4 +(n4+1)× n5 +(n5+1)× n6个可训练参数。
在此CNN模型中, C2与P3层可看作是对原始光谱数据的特征提取过程, F4与F5层是对深层特征的分类过程, 可以理解为从每个原始光谱中提取到了7个特征, 每个特征有n3维。 实验结果表明, 本文提出的CNN模型对复杂光谱特征的提取是有效的, 最终对校正集和预测集的分类准确率达到100%, 实现了对夏威夷果品质的准确鉴定。
运用可见-近红外光谱技术结合CNN模型对三类夏威夷果样本进行了品质鉴别, 采集三类不同品质的夏威夷果反射光谱作为研究样本, 进行实验验证。 首先进行白化处理及光谱预处理, 去除相关性, 之后通过逐层训练学习到更深层的光谱特征, 最终确定了一个6层结构的CNN模型: 输入层— 卷积层(7个卷积核)— 池化层(下采样2)— 全连接层(200)— 全连接层(100)— 输出层。 在训练过程中应用了ReLU及Dropout等方法, 能够有效预防过拟合, 避免训练中陷入局部最小值, 同时提升网络收敛速度。 结果显示, 使用该模型对夏威夷果样本中的好籽、 哈籽及霉籽进行鉴别, 准确率达到100%。 近红外光谱分析技术结合CNN建模的方法可实现对夏威夷果品质的高效无损鉴别, 此模型可扩展应用于其他坚果类食品的光谱特征研究。 CNN作为一种新兴的技术方法展现了其强大的深度特征提取能力, 其在光谱数据中的应用仍有巨大潜力。 在后续的研究中, 会在增加样本品种和数量的基础上, 尝试更高效的卷积神经网络。 并且根据夏威夷果的结构特点, 不断改善光源照明和样本探测方式, 为夏威夷果高效低成本的规模化检测提供可靠的技术支持。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|