

{kind=link}
{kind=link}
{kind=link}
基于正交信号回归法对中试在线近红外定量模型的模型传递研究
[王安冬1  , 吴志生
, 吴志生1, 2, 3 , 贾一飞1 , 张盈盈1 , 詹雪艳1, * , 马长华1, * ]
, 吴志生, 马长华]
|
|


作者简介: 王安冬, 女, 1993年生, 北京中医药大学药物分析硕士研究生 e-mail: wangad@bucm.edu.cn
模型传递使在特定条件下建立的模型能够应用于新的样品状态、 环境条件或仪器状态。 本研究在中药金银花中试在线水提过程中, 以水提液中的绿原酸含量为研究对象, 建立绿原酸含量的近红外定量模型。 针对由金银花来源不同带来的模型失效问题, 从光谱背景校正的角度出发, 提出以KS算法挑选待传递样本中的代表性样本, 结合正交信号回归(OSR)光谱背景校正方法, 对不同来源样本的近红外光谱进行光谱背景校正, 并深入探讨OSR方法实现近红外定量模型在不同来源中试样本间传递的应用原理。 经模型传递后, 模型对新批次样本预测的RSEP由14.91%下降到7.11%, RPD由2.95上升到5.36, 预测准确度明显提高。 实验证明, 选择代表性样本的KS算法结合OSR光谱背景校正的模型传递方法不仅能减小不同来源原料药之间的偶然误差, 同时消除了中试制剂过程和算法本身的系统误差, 因此能够有效地改善因样本来源差异而造成的模型失效现象。 该研究充分阐释了OSR模型传递方法的应用原理, 以光谱背景校正与挑选代表性样本回归的方法实现了近红外定量模型在不同来源原料药中试样本之间的模型传递, 增强了模型应对原料药批次间变动的能力, 提高了模型的稳健性, 为多来源原料药中试在线制剂过程中有效成分含量的快速实时监测提供了有效方法。
Model established under a certain condition can be applied to the new samples, environmental conditions or instrument status through the model transfer. In the process of pilot-on-line water extraction of Flos Lonicerae Japonicae, the content of chlorogenic acid is measured with High Performance Liquid Chromatography (HPLC) as a reference method, and a NIR quantitative model of chlorogenic acid is established by partial least square regression (PLSR)。 In order to solve the problem of model’s failure to predict accurately the content of chlorogenic acid in the samples of Flos Lonicerae Japonicae from different sources, the KS algorithm is used to select the representative samples from samples to be transferred, orthogonal signal regression (OSR)algorithm is used to correct the NIR spectral background of the samples from different sources. And deeply discussing how the OSR worked in the model transfer from different sources. After the model transferred, the RSEP of transferred model predicting the new batch samples decreases from 14.91% to 7.11%, RPD rises from 2.95 to 5.36, indicating the obvious improvement of prediction accuracy. The results show that the model transfer method which combines the KS algorithm with OSR can diminish the spectral background variation between the samples of different sources effectively, because it not only reduces the accidental errors of the spectral background from the pharmaceutical raw materials from different sources, but also eliminates the system errors in the preparation process of pilot-on-line water extraction and the OSR algorithm. Based on this, it could correct model failure caused by different sample sources. This paper explains the application principle of OSR. Make NIR model to be transferred between the pilot samples which medicinal raw material come from different sources by spectral background and selecting the representative samples regression. Strengthen the model’s adjustment with the batch variations of medicinal raw material and improve the robustness of the NIR quantitative model. It will provide a method for the rapid and on-line detection of the active ingredient content of multi-sources samples during the process of pilot-on line water extraction, and promote the application of NIR quantitative model in the preparation process of TCM.
引 言
近红外光谱技术具有操作简便, 快速无损等优点, 近年来被广泛应用于中药分析领域。 然而, 中药原料变异和制药工艺的复杂性限制了NIR定量模型在中药生产过程中的广泛应用, 此外, 模型维护的高成本也极大地阻碍了中药NIR定量模型的大规模应用。
模型传递是通过一定数量的传递样本, 在不同的样本状态、 环境条件或仪器状态下, 用数学方法在检测信号之间寻求一种变换关系, 来增强光谱数据间的通用性和可比性。 模型传递可使特定条件下建立的模型能够应用于新的样品状态、 环境条件或仪器状态[1]。 目前常用的模型传递方法主要有三类: 基于预测结果校正的模型传递, 基于光谱背景校正的模型传递以及模型更新。 其中, 研究较多的有SBC算法(simulated beecolony, SBC)[3]、 分段直接校正(piecewise direct standardization, PDS)[3]或直接校正法(direct standardization, DS)[4]、 小波变换域标准化(standardization in the wavelet domain, SWD)[5]等。 这些模型传递方法可以成功实现模型在不同仪器间的传递, 但没有考虑待测量的特征, 难以在校正无关干扰信息的同时不损失与待测量有关的光谱信息, 对于组分变异较大的对象(如不同批次中药原药材)预测效果较差, 此外, 这些方法大多为标准化方法, 在实际应用中, 标准样本难以获得和重现, 限制了标准化模型传递方法的应用。 本课题组林兆洲提出一种基于光谱背景校正的OSR模型传递方法[6, 7], 实现了不同批次金银花实验室醇沉过程中绿原酸定量模型的模型传递。 正交信号回归法(orthogonal signal regression, OSR)是一种在直接正交信号校正法(direct orthogonal signal correction, DOSC)[8]的基础上提出的光谱背景校正方法, 是将光谱正交分解后, 以虚拟标准平均光谱的回归为核心来消除样本批次间背景差异的模型传递算法。 OSR模型传递方法既能够有效地消除样本批次间的变异, 也克服了标准样本在生产过程中无法重现的限制。
目前近红外定量模型的模型传递仍局限于实验室制剂模拟过程, 实验室制剂过程规模小, 物料均匀, 制剂过程简单易控, 相同状态下样本的离散程度小, 偶然误差小, 通过校正光谱背景差异就可实现两种状态下近红外定量模型的传递。 然而在中试生产中, 由于生产规模的扩大, 物料的不均匀性和制剂过程的波动, 同一批次中试样本的状态差异增大, 中试样本间光谱的离散程度增大, 表明不确定原因的偶然误差增大。 因此, 以上模型传递方法是否同样适用于中试甚至大生产中的数据还有待验证。
基于以上分析, 研究以金银花中试水提过程中绿原酸的含量为监测对象, 建立金银花中试在线水提过程中绿原酸含量的近红外定量模型, 研究中试样本批次间差异对NIR定量模型预测性能的影响。 利用正交信号回归法(OSR)消除金银花中试水提样本批次间的差异, 探讨OSR方法在模型传递过程中如何减少不同批次间原料药光谱背景的差异, 校正多批次制剂光谱间的系统误差, 实现金银花中试水提过程中绿原酸定量模型在批次间的模型传递。 该方法增强了近红外定量模型应对原料药批次间变动的能力, 进而促进了近红外定量技术在中药生产过程中的应用。
Waters 1525高效液相色谱仪(美国Waters公司), Breeze 2 HPLC色谱工作站, Waters 2998二级管阵列检测器, Waters 2707自动进样器, Waters 038040柱温箱。
XDS PROCESS ANALYZER 近红外光谱仪(Foss公司), 夹套式100 L多功能提取罐(天津市隆业中药设备有限公司)。
试剂: 绿原酸标准品(上海源叶生物科技有限公司); 磷酸(分析纯, 北京化工厂); 乙腈(色谱纯, 赛默飞世尔科技(中国)有限公司); 水为去离子水。
金银花药材(批次Ⅰ 、 批次Ⅱ 购于安国长安中药材有限公司; 批次Ⅲ 、 批次Ⅳ 购于安国云天中药行; 批次Ⅴ 购于安国永益中药材有限公司)。
金银花提取液中绿原酸的含量按照《中国药典》(2015版一部)金银花药材项下规定的方法进行测定。 HPLC分析条件: 采用SB-C18(250 mm× 4.6 mm, 5 μ m)色谱柱, 流动相为乙腈(A)和0.4%磷酸水溶液(B), 等度洗脱, A∶ B(30∶ 70); 测定波长: 327 nm; 柱温: 35 ℃; 流速: 1.0 mL· min-1。 理论塔板数以绿原酸峰面积计算, 应不低于1 000。
提取系统为夹套式100 L多功能提取罐, 金银花药材投料量为6 kg, 一煎加水12倍, 加热回流提取1 h, 并于提取前浸泡30 min; 二煎加水10倍, 加热回流1 h。 相同工艺平行提取5个批次。 采用强制外循环旁路方式, 通过光纤探头在线采集近红外光谱。 两次提取过程中, 浸泡和一煎过程每3 min采样一次; 二煎过程每4 min采样一次。 每次采集光谱前50 s, 通过强制外循环系统更新旁路内药液, 保证所抽取样本与罐内药液保持一致。 光谱采集结束后, 立即弃去取样口内可能残存的药液约5 mL, 然后收集样本约10 mL, 用1.3项下HPLC色谱条件进行含量测定。
NIR光谱采集条件: 在光程2 mm下, 采用透射模式在线采集提取液吸收光谱, 光谱范围800~2 200 nm, 扫描次数32次, 分辨率0.5 nm, 实验采用空气作为参比。 采集的原始近红外谱图见图1。
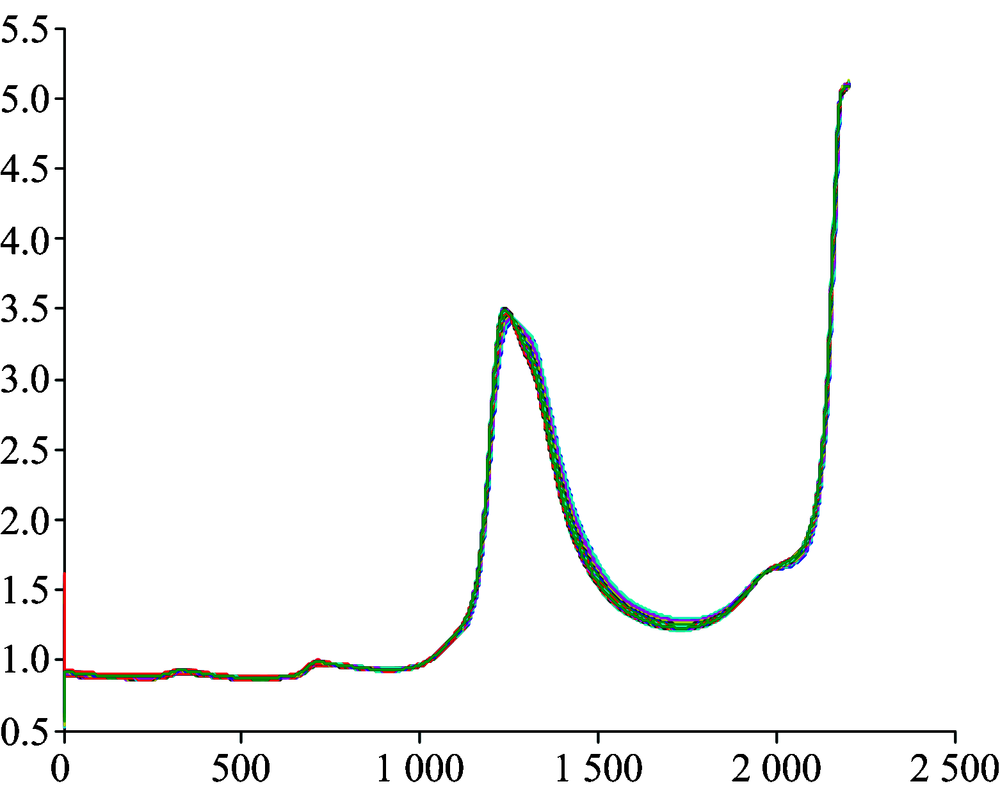 | 图1 金银花中试水提样本的原始近红外光谱图Fig.1 Original near infrared (NIR) spectra of samples |
采用SPXY法[9]将样本集划分为校正集与验证集。 分别采用不同的光谱预处理方法进行预处理, 采用组合间隔偏最小二乘法(synergy interval PLS, SiPLS) 对建模波段进行筛选, 建立PLS模型, 选择最优光谱预处理方法和建模波段。
数据处理均在Unscrambler数据分析软件(version 9.7挪威CAMO软件公司)和MATLAB软件(version7.0, 美国Math Works公司)上完成。
研究采用KS算法挑选待传递样本中的代表性样本, 结合正交信号回归法(orthogonal signal regression, OSR)进行模型传递, 主要用于消除原料药批次之间的变异, 使得原模型能够对新批次原料药中目标成分的含量进行快速准确地预测。 它基于虚拟标准光谱(virtual standardization spectrum, VSS)对新批次样本的光谱数据进行处理以消除制剂过程中原料的变异[7]。 虚拟标准光谱定义为: 经DOSC校正的光谱与其参考值Yi之比。
其中,
OSR的实现过程主要为三个步骤:
首先, 用直接正交信号校正(direct orthogonal signal correction, DOSC)对校正集样本和待转移样本进行光谱预处理, 删除主批次和从批次样本中与目标变量无关的信息。
然后, 采用KS方法从经DOSC预处理后的待传递样本中挑选出少量的代表性样本, 分别计算校正集样本和挑选出的代表性待传递样本的虚拟标准平均光谱。
最后, 采用最小二乘法拟合主批次虚拟标准平均光谱Vpri和从批次虚拟标准平均光谱Vsla之间的关系, 拟合回归系数slope和常量项bias的值。
将经DOSC处理后的批次Ⅴ 中剩余的待转移样本光谱
用经DOSC光谱预处理后的校正集所建的PLS模型, 对光谱背景校正后的批次Ⅴ 样本光谱
从上述OSR处理过程中可以看出, OSR通过DOSC光谱预处理消除光谱中与目标变量无关的信息, 然后通过拟合主、 从批次的虚拟标准平均光谱的线性关系来将从批次样本光谱变换到主批次样本光谱空间, 因此能消除由原料变异产生的光谱背景的变异, 实现主从批次样本之间的光谱背景校正。
HPLC测得绿原酸标准品中绿原酸峰面积Y(mAu· s)与其含量X(mg· mL-1)间关系为Y=3.19× 107X-7.69× 104(相关系数r=0.999 5), 表明当绿原酸质量浓度在0.002 68~0.107 2 mg· mL-1时, 与峰面积呈良好的线性关系。
对该HPLC绿原酸含量测定方法进行方法学考察。 取绿原酸对照品溶液, 连续进样6次, 绿原酸峰面积的RSD为1.08%, 表明仪器精密度良好; 取金银花供试品溶液, 分别于0, 2, 4, 8, 10, 12 h进样, 计算绿原酸浓度的RSD为1.38%, 表明12h内供试品溶液具有良好的稳定性; 平行操作制备6份供试品溶液, 分别进样, 绿原酸浓度RSD为1.91%, 表明该方法重复性良好; 精密称定6份金银花样品, 分别加入等量绿原酸标准品, 制备供试品溶液, 进样分析, 计算平均加样回收率为102.7%, RSD为1.95%, 表明该方法的准确度良好。 经方法学验证, 本实验所采用的绿原酸HPLC含量测定方法符合定量要求。
将采集到的各个批次金银花水提液样本进行HPLC含量测定, 剔除浸泡和二煎初始过程中绿原酸浓度较低的样本, 并将样本稀释至绿原酸标准曲线浓度范围内。 经稀释和计算, 金银花中试水提液中, 作为校正集的批次Ⅰ — Ⅲ 各个样本的绿原酸浓度为0.516 0~1.921 5 mg· mL-1, 批次Ⅳ — Ⅴ 绿原酸质量浓度为0.533 5~1.667 2 mg· mL-1。 五个批次样本的绿原酸浓度分布见表1。
| 表1 金银花中试水提样本的绿原酸浓度分布 Table 1 Concentration distribution of chlorogenic acid in samples |
采用购自安国长安中药材有限公司的金银花, 制备中试水提样本批次Ⅰ — Ⅱ , 采用购自安国云天中药行的金银花制备中试水提样本批次Ⅲ , 用三批66个金银花中试水提样本作为建模样本, 采用SPXY法选择42个代表性样本作为建模校正集样本, 剩下24个作为内部验证集样本。 以购自安国云天中药行的金银花中试水提样本批次Ⅳ 作为外部验证集。
由于1 940 nm附近存在水溶液O— H较强吸收, 这将严重干扰其他官能团在该区域的信号, 因此, 为提高所建模型的预测精度, 建模时所有样本均剔除1 900~2 200 nm处的波段, 采用800~1 900 nm作为建模光谱。
考虑到研究对象为中药中试水提液体体系, 近红外光谱采集原理主要为光在水提液中的透射, 本实验考察了4种能够有效校正透射光谱误差的光谱预处理方法。 S-G平滑(S-G smoothing, S-G), 一阶导(1st derivative, 1D), 二阶导(2nd derivative, 2D), 和DOSC四种光谱预处理方法下所建PLS模型的预测结果, 见表2。 采用上述各预处理方法对光谱进行预处理后, 采用SiPLS(间隔数设为20, 组合数为3)算法分别对其进行变量筛选, 分别对筛选的谱区和全光谱(800~1 900 nm)的建模效果进行考察。 结果见表2。
| 表2 不同光谱预处理条件下模型预测情况 Table 2 The prediction results of the PLS models using different spectra preprocessing methods |
如表2所示, 经DOSC光谱预处理, 经SG(9, 2)光谱预处理以及无光谱预处理的原光谱在全光谱建立的PLS模型, 其校正集的RMSEC值分别为1.68%, 5.57%和8.99%, RPD值分别为17.53, 5.25和3.83。 三个模型内部验证集的RSEP分别为8.79%, 7.35%和5.20%, 外部验证集的RSEP分别为9.16%, 6.13%和7.29%, 内外部验证集的RSEP值均落在10%误差内, RPD值均在3.0以上, 表明三个模型稳健, 预测性能良好。
利用2.2项下挑选出的三个PLS模型(DOSC光谱预处理后全光谱建模模型、 SG光谱预处理后全光谱建模模型以及不经光谱预处理的原光谱全光谱建模模型)分别对批次Ⅳ 和批次Ⅴ 样本进行预测和比较, 三个模型对批次Ⅳ 和批次Ⅴ 样本的预测情况见表3。
DOSC光谱预处理后全光谱建模模型、 SG光谱预处理后全光谱建模模型以及不经光谱预处理的原光谱全光谱建模模型对批次Ⅳ 样本的预测RSEP分别为9.16%, 6.13%和7.29%, 均在10%以内, RPD值分别为3.21, 5.22和4.39, 均在3.0以下, 符合中药生产过程中目标成分含量快速准确预测的要求。 而三个模型对不同来源金银花原料药样本批次Ⅴ 的预测RSEP分别为14.91%, 20.77%和25.52%, RPD值分别为2.95, 1.90和1.57, 该结果超出了快速定量的标准, 预测准确度差。 该外部预测结果表明, 三个模型可以对批次Ⅳ 样本准确预测, 而对批次Ⅴ 样本的预测出现了模型“ 失效” 的问题。
| 表3 三个模型对批次Ⅳ 和批次Ⅴ 样本的预测结果 Table 3 The prediction results of three PLS models of samples in batch Ⅳ and Ⅴ |
本实验中批次Ⅳ 为来源于安国云天中药行的金银花中试水提样本, 与校正集样本批次Ⅰ — Ⅲ 的为同来源样本, 是同来源原料药重复中试水提制剂过程中产生的样本, 而批次V样本来源于安国永益中药材有限公司, 与前四个批次样本来源均不同, 是不同来源样本, 模型对批次V的预测结果差, 其主要原因是由于金银花原料药存在批次间的原料变异, 使原有的模型无法涵盖新来源原料药出现的变异, 因此需要采用模型传递的数据处理方法对批次Ⅴ 样本的光谱背景进行校正。
此外, 以上分别由三个不同预处理方法所建的模型中, DOSC光谱预处理后全光谱建立的模型对批次Ⅴ 的预测结果略优于其他两个模型, 这是由于DOSC算法在一定程度上消除了光谱背景中与目标变量属性无关的变量, 对于光谱背景中因来源不同而导致的偶然误差起到了一定程度地消除作用。
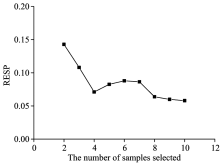
针对NIR定量模型对新来源样本预测“ 失效” 的现象, 需要进行模型传递以保证模型对新来源样本的预测有效性。 本研究采用KS算法结合OSR光谱背景校正的方法对新来源金银花中试水提样本的近红外光谱进行光谱背景校正, 实现2.3项下挑选出三个PLS模型为源模型的模型传递。 以KS算法挑选批次Ⅴ 中代表性样本, 以回归校正后模型对批次Ⅴ 样本的预测RSEP值为指标选择最佳代表性样本个数, 结果见图2。 图2表明, 当挑选的样本个数为4时, RSEP值较低, 且随着样本个数的增加, RSEP值的变化趋于平稳, 故本实验挑选4个样本作为模型传递的代表性样本。
 | 图2 批次Ⅴ 样本的预测RSEP值随代表性样本个数的变化趋势Fig.2 The RSEP of different number of samples selected by KS algorithm from batch Ⅴ |
2.4.1 DOSC, SG, Raw光谱预处理后PLS模型的传递结果比较
以SG光谱预处理模型、 原光谱模型和DOSC光谱预处理后的PLS模型为源模型, 分别按1.6项下模型传递方法进行平行处理, 得到对批次Ⅴ 中19个样本光谱与校正集样本光谱回归的线性方程: Vpri=bias+slope· Vsla, 其中, slope代表光谱变形(伸缩或拉伸)的程度, slope为1即光谱没有发生变形, 越接近1表示光谱变形程度越小; bias代表光谱平移的程度, bias为0即光谱没有发生平移。 三个PLS模型在各自的光谱预处理条件下经同等程度光谱背景回归校正的结果见表4。
| 表4 三个PLS模型对批次Ⅴ 样本光谱进行光谱回归校正前后的结果比较 Table 4 Comparison of the three PLS models before and after the spectral background correction of samples spectra in batch Ⅴ |
经过模型传递, 批次Ⅴ 样本光谱变形平移后, 不经过光谱预处理的PLS模型和经SG光谱预处理的PLS模型对批次Ⅴ 样本的预测RSEP分别由25.52%增大到891.9%, 由20.77%增大到79.49%, 预测准确度大幅度下降。 而经DOSC光谱预处理后全光谱建立的模型经回归后对批次Ⅴ 样本的预测RSEP由14.91%减小到7.11%, RPD值由2.95增大到5.36, 预测准确度有较大提高。
无光谱预处理的原光谱在全光谱建立的模型和经SG光谱预处理全光谱建立的模型经回归校正后不仅没有改善模型“ 失效” 的现象, 反而模型的预测性能受损更加严重。 因为校正集样本和批次Ⅴ 样本之间存在因原料来源不同而导致的背景差异, 属于天然产物无固定原因产生的偶然误差, 直接将批次Ⅴ 样本的虚拟标准平均光谱线性拟合到校正集样本的虚拟标准平均光谱空间, 以系统误差的校正方式来校正偶然误差, 会产生相当大的误差, 因此模型回归校正后对批次Ⅴ 样本的预测准确度显著增大。 SG光谱预处理的作用是减少光谱中的噪声, 而对光谱空间改变的作用不大, 因此SG光谱预处理后将批次Ⅴ 样本的虚拟标准平均光谱拟合到校正集样本的虚拟标准平均光谱空间, 也会产生较大的误差。 而DOSC预处理方法用正交的方法消除了校正集和批次Ⅴ 样本光谱中与目标变量无关的信息, 很大程度上消除了因原料不同而导致的光谱背景差异, 并在此基础上利用校正集和待转移样本的虚拟标准平均光谱线性关系来校正两样本集之间的系统误差, 因此校正模型对批次Ⅴ 样本的预测准确度得到改善。 由此说明不同来源样本光谱间存在一定的背景差异, 而光谱不经预处理或经SG方法预处理无法减小这些背景差异, 故拟合两虚拟标准平均光谱之间关系时存在较大误差, 导致线性回归后的模型预测性能受损严重。 而DOSC光谱预处理方法能够将光谱矩阵用目标成分浓度矩阵为指导进行校正, 从而在很大程度上滤除了光谱中与绿原酸浓度属性无关的背景信息, 只保留了与目标成分相关的光谱信息, 提高了校正模型的预测性能。
2.4.2 OSR模型传递方法的作用
采用DOSC算法对校正集样本(批次Ⅰ — Ⅲ )和不同来源新批次样本(批次Ⅴ )进行光谱预处理后, 表3中批次Ⅴ 样本预测的RSEP值由25.52%或20.77%下降到14.91%, 预测准确度得到一定的提高, 表明经DOSC光谱预处理后, 消除或减少了主从批次样本中与被测属性无关的信息, 因此在一定程度上减小了原料不同产生的背景差异(偶然误差), 有利于模型预测性能的提高。 但是, DOSC预处理后的模型对批次Ⅴ 样本的预测值均高于参考值, 见图3(a), 表明DOSC虽然能够将光谱中与绿原酸含量无关的信息滤除, 减小不同来源样本间的偶然误差, 但其算法在将光谱以目标成分浓度矩阵为指导进行正交分解时, 存在一定的系统误差, 可能会把光谱中与被分析属性相关的一部分信息同时删除掉, 造成在DOSC光谱预处理后预测值与参考值之间产生一定的系统误差, 从而使模型的预测性能受损。 继续进行回归校正后, 见图3(b), 样本预测值和参考值近乎重合或更为接近地大致分布在对角线两侧, 改善了图3(a)中的预测结果。 以上结果表明, 在DOSC预处理基础上对虚拟标准平均光谱进行线性校正, 进一步消除了重复水提过程中样本间存在的系统误差, 同时也在一定程度上校正了由DOSC算法引起的过拟合现象。
 | 图3 批次Ⅴ 样本的预测值与参考值的相关关系图 (a): 经DOSC预处理后预测值与参考值的相关关系; (b): 经OSR模型传递后预测值与参考值相关关系图Fig.3 Correlation plot between NIR predict values and reference values in batch Ⅴ Correlation plot between NIR predict values and reference values after DOSC Pretreatment (a); Correlation plot between NIR predict values and reference values after OSR transfer (b) |
因此, OSR方法一方面通过DOSC算法对光谱进行预处理, 减小不同批次样本间存在的偶然误差, 另一方面, 通过对新批次中代表性样本与校正集样本虚拟标准平均光谱的回归, 进一步校正了重复制剂样本间和DOSC算法中存在的系统误差。 OSR能够减小不同来源样本间的背景偶然误差和系统误差, 从而提高模型预测准确度, 得到好的模型传递结果。 由此表明, OSR光谱背景校正后能在一定程度上减小不同来源原料药的变异(偶然误差), 消除多批次重复制剂过程中的系统误差, 增强模型应对制剂过程中原料药批次间变异的能力, 可用于新批次金银花中试水提过程中绿原酸含量的快速检测。
现阶段, 中药近红外定量模型传递的研究多局限于实验室制剂过程, 而中试生产中, 由于生产规模的扩大, 中试样本间不确定因素的偶然误差增大, 实验室规模的模型传递方法是否同样适用于中药的中试在线生产过程仍有待验证。 本研究采用近红外分析技术对金银花中试水提过程进行在线监测, 以绿原酸为指标性成分, 建立金银花中试在线水提过程中绿原酸含量的近红外定量模型, 探讨在中试在线水提过程中, 来源于不同厂家的金银花样本的批次间差异对该模型的影响, 利用OSR方法进行模型传递, 同时研究了OSR模型传递方法在中药中试在线生产中的应用原理。 模型传递后模型对新来源样本的预测误差由14.91%下降到7.11%, 预测性能得到明显提高。 在OSR模型传递方法中, 首先采用DOSC光谱预处理方法滤除掉光谱中与目标变量无关的信息, 减少了不同批次间由不确定因素引起的偶然误差, 但DOSC可能会造成过拟合现象, 导致一定程度系统误差的出现; 进一步拟合虚拟标准平均光谱的回归关系能消除重复制剂过程中的系统误差, 同时也能够改善因DOSC过拟合导致的算法上的系统误差。 因此, 本研究提出的选择代表性样本的算法结合正交信号回归光谱背景校正的模型传递方法能够校正不同来源原料药中试样本批次之间的差异, 增强了金银花中试在线水提过程中绿原酸近红外定量模型应对原料药批次间变动的能力, 为中药中试在线水提过程中有效成分含量的在线监测提供更稳健的预测模型, 同时也为中药中试乃至大规模生产过程中有效成分的实时监测和质量控制提供参考方法, 为进一步促进近红外定量模型在中药生产过程中的应用奠定实验基础。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|