



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
茶叶傅里叶红外光谱的可能模糊K调和均值聚类分析
[武斌1  , 王大智
, 王大智2 , 武小红3, 4, * , 贾红雯1 ]
, 王大智, 贾红雯|
|


作者简介: 武斌, 1978年生, 滁州职业技术学院信息工程系副教授 e-mail: wubind2003@163.com
茶叶的品种不同, 其有机化学成分含量往往不同, 其功效也是不尽相同的, 因此, 研究出一种简单、 高效、 识别率高的茶叶品种鉴别技术方法是十分有必要的。 中红外光谱技术是一种快速检测技术, 在用中红外光谱仪采集得到的茶叶中红外光谱中含有噪声信号。 为了对含噪声茶叶中红外光谱的准确分类以实现茶叶品种分类, 将可能模糊C-均值聚类(PFCM)思想应用到K调和均值(KHM)聚类, 设计出一种可能模糊K调和均值(PFKHM)聚类算法, 计算出PFKHM的模糊隶属度、 典型值和聚类中心。 可能模糊K调和均值聚类能有效解决K调和均值聚类的噪声敏感性问题。 用傅里叶红外光谱分析仪(FTIR-7600型)分别对三种茶叶(优质乐山竹叶青、 劣质乐山竹叶青和峨眉山毛峰)进行扫描以获取它们的傅里叶中红外光谱。 光谱波数区间是4 001.569~401.121 1 cm-1。 先采用主成分分析法(PCA)将光谱数据压缩到20维, 再采用线性判别分析(LDA)将光谱数据压缩到两维并提取鉴别特征信息。 最后分别用K调和均值聚类和可能模糊K调和均值聚类实现茶叶品种分类。 实验结果: 当权重指数 m=2, q=2和 p=2时, KHM具有91.67%的聚类准确率, PFKHM聚类准确率达到94.44%; KHM迭代12次达到收敛, 而PFKHM迭代11次就可以达到收敛。 采用傅里叶红外光谱技术检测茶叶, 用主成分分析和线性判别分析压缩光谱数据, 再用可能模糊K调和均值聚类进行品种分类可快速、 准确地实现茶叶品种的鉴别。
Different variety of tea often has diversified organic chemical components, and their effects are not the same. Therefore, it is very necessary to develop a simple, efficient, high recognition rate method in classifying tea varieties. Mid-infrared spectroscopy is a rapid detection technology, and there is noise signal in the mid-infrared spectra of tea samples collected by spectrometer. With a view to identifying tea varieties through the classification of the mid-infrared spectra of tea samples with noise, possibilistic fuzzy c-means clustering was applied in K-harmonic means clustering (KHM) and a novel clustering, called possibilistic fuzzy K-harmonic means clustering (PFKHM), was proposed. PFKHM can produce both fuzzy membership value and typicality value and solved the noise sensitivity problem of KHM. First of all, we used FTIR-7600 spectrometer to scan three varieties of tea samples (i. e. Emeishan Maofeng, high quality Leshan trimeresurus and low quality Leshan trimeresurus) for their Fourier transform infrared spectroscopy (FTIR) data. The wave number of FTIR data ranged from 4 001.569 to 401.121 1 cm-1. Secondly, we employed principal component analysis (PCA) to compress spectral data into 20-dimensional data which were compressed into two-dimensional data by linear discriminant analysis (LDA). Lastly, we used KHM and PFKHM to classify the tea varieties respectively. The experimental results indicated that when the weight index m=2, q=2 and p=2 the clustering accuracy rates of KHM and PFKHM achieved 91.67% and 94.44%, respectively. KHM was convergent after 12 iterations and PFKHM was convergent after 12 iterations. Tea varieties could be quickly and accurately classified by testing tea with FTIR technology, compressing spectral data with PCA and LDA, and classifying tea varieties with PFKHM.
茶是世界三大饮品之一。 中国古代就有饮茶习惯, 茶文化起源于中国。 茶是一种受人民群众欢迎, 有益身心健康的绿色饮品。 茶叶里含有对人体健康有益的物质, 比如茶叶中的儿茶素具有抗氧化, 抗肿瘤, 降低胆固醇和低密度脂蛋白等作用。 我国茶叶主要有红茶, 绿茶, 白茶等品种, 同一品种的茶也存在着品质等级差异。 如何设计一种快速, 准确的茶叶品种鉴别方法是值得深入研究的课题。
国内外学者近年来在利用光谱技术检测茶叶方面做了大量工作, 取得了一些成果[1, 2]。 例如: 欧阳琴等[3]采用可见光-近红外光谱技术和遗传BP神经网络模型对黑茶的色泽感官品质进行快速和准确的预测。 Li等[4]用太赫兹光谱技术和主成分分析, 遗传支持向量机模型实现对不同产地的绿茶进行分类识别研究, 对测试样本的识别准确率达到96.25%。 Panigrahi等[5]用漫反射光谱技术和偏最小二乘回归评价黑茶的品质。 Zhuang等[6]采用近红外光谱技术和移动窗BP人工神经网络对两种不同产地的山东绿茶进行识别, 准确率可达98.33%。 Shi[7]采用近红外光谱技术, 基因表达算法和投影判别分析进行六类茶叶的多类鉴别, 比传统的基因表达算法, 主成分分析和线性判别分析更加有效。 江辉等用傅里叶变换近红外光谱技术实现对绿茶感官品质的正确评价。 采用联合区间偏最小二乘法优选预测模型的光谱波数区间, 与BP人工神经网络相比较, BP_AdaBoost获得了更准确的预测[8]。
1999年有研究提出K调和均值聚类(KHM), 是一种面向类中心的聚类方法[9]。 K调和均值聚类的目标函数建立在计算全部样本到所有聚类中心的调和平均值之和基础上。 实验表明, 建立于提升函数基础上的KHM, 其对比初始聚类中心的敏感性要比K均值聚类弱。 但是, K调和均值聚类也容易陷入局部极小点。 因此, 许多学者针对此问题展开研究。 Yang等[10]将粒子群优化和K调和均值聚类相结合, 提出一种粒子群优化的K调和均值聚类算法(PSOKHM), PSOKHM能避免局部极小点, 并且解决了粒子群优化收敛速度慢问题。 由于蚁群聚类算法能解决局部极小点问题, Jiang等[11]提出一种基于蚁群聚类的K调和均值聚类算法。 Gü ngö r和Ü nler[12]在模拟退火和K调和均值聚类基础上提出一种新的聚类算法以求得K调和均值聚类的全局最优解。 禁忌搜索是一种全局逐步寻优算法, Gü ngö r和Ü nler[13]利用禁忌搜索算法提出禁忌K调和均值聚类算法, 该算法解决了K调和均值聚类的局部极小点问题。 KHM聚类存在噪声敏感性问题[9], 本文在KHM聚类基础上提出一种可能模糊K调和均值(PFKHM)聚类算法以解决KHM聚类的噪声敏感性问题。
本研究采用FTIR-7600型红外光谱分析仪获取三种茶叶的红外光谱数据, 用主成分分析(PCA)和线性判别分析(LDA)降低红外光谱数据的维数, 然后分别用KHM聚类和PFKHM聚类进行光谱聚类分析。 根据聚类分析结果, 傅里叶红外光谱技术能快速检测茶叶样本, PFKHM聚类算法能准确的鉴别茶叶品种。
从市场上购买三种茶叶(优质乐山竹叶青、 劣质乐山竹叶青和峨眉山毛峰), 每个品种有32个样本, 总样本数是96。 所有的茶叶样本经粉碎机粉碎后过40目筛, 再从每个样本中取0.5 g粉碎物和KBr混合, 然后取1 g混合物作为1个样本进行压膜处理。 傅里叶红外光谱分析仪(FTIR-7600型)预热1 h后, 采集茶叶样本的傅里叶中红外光谱数据, 实验过程中保持温度和湿度相对稳定。 FTIR-7600分析仪扫描次数设置为32次/样本, 波数范围设置为4 001.569~401.121 1 cm-1, 扫描间隔设置为1.928 5 cm-1。 每个茶叶样本采集中红外光谱实验数据三次, 取其平均值作为后续处理样本数据, 数据维数为1 868维。 每个品种茶叶样本的红外光谱的均值如图1所示, 其中“ Emeishan Maofeng” , “ High quality trimeresurus” 和“ Low quality trimeresurus” 分别表示峨眉山毛峰, 优质乐山竹叶青和劣质乐山竹叶青三种茶叶的傅里叶红外光谱的均值。 数据处理及聚类算法的编程采用Matlab7.0软件。
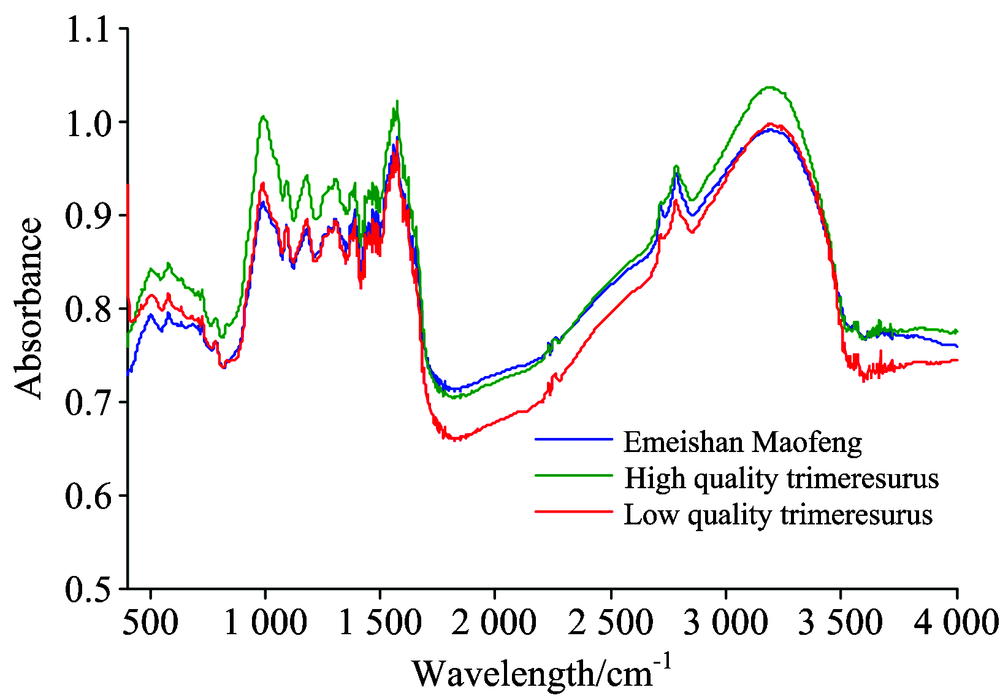 | 图1 茶叶样本的傅里叶红外光谱图Fig.1 FTIR spectra of tea samples |
可能模糊K调和均值聚类算法主要步骤如下:
(1)确定聚类的初始聚类中心C(0);
(2)设置参数值: 确定聚类的数目k, 数据的个数n和权重指数m和q的值, n> k> 1, +∞ > m, q> 1, 设置迭代次数初始值r=1和最大迭代次数为rmax, 设置迭代最大误差参数ε ; 正常数a和b的值;
(3)计算样本数据的协方差;
样本数据的协方差计算公式为
式(1)中, xj为第j个样本数据,
(4)计算可能模糊K调和均值聚类的模糊隶属度值;
可能模糊K调和均值聚类的模糊隶属度值计算式为
式(2)中, uij, PFKHM为可能模糊K调和均值聚类的第i个样本隶属于第j类的模糊隶属度值; dij=‖ xi-cj‖ , cj为第j个聚类中心值。
(5)计算可能模糊K调和均值聚类的典型值;
可能模糊K调和均值聚类的典型值为
式(3)中, tij, PFKHM为可能模糊K调和均值聚类的第i个样本隶属于第j类的的典型值。
(6)计算可能模糊K调和均值聚类的聚类中心值;
可能模糊K调和均值聚类的聚类中心值计算式为

式(4)中, cj, PFKHM是可能模糊K调和均值聚类的第j类聚类中心值, m和q为权重指数, +∞ > m, q> 1; a和b为正常数, a和b确定了模糊隶属度值和典型值的相对重要性。
(7)判断是否满足迭代终止条件;
可能模糊K调和均值聚类的迭代终止条件为
式(5)中C(r)为第r次迭代运算的类中心矩阵值, C(r)由类中心矢量cj, PFKHM组成。
若满足迭代终止条件则迭代终止, 否则重复步骤(4)到步骤(7)继续迭代计算。
(8) 利用模糊隶属度值和典型值最终实现数据集的划分。
K调和均值聚类的隶属度计算如式(6)
式(6)中, uij, KHM为K调和均值聚类的第i个样本隶属于第j类的隶属度值, p为权重指数, +∞ > p> 1。
K调和均值聚类的类中心计算如式(7)
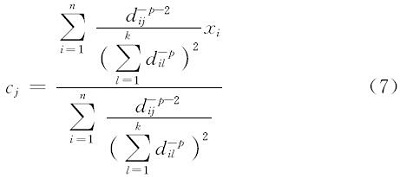
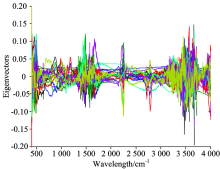
茶叶红外光谱数据是高维(1 868维)数据, 直接用分类器对高维光谱数据进行分类, 一方面计算量很大, 另一方面准确率低。 通常采用主成分分析(PCA)压缩光谱以降低光谱数据的维数, 同时保留大部分的有用信息。 PCA的前20个特征向量如图2所示。
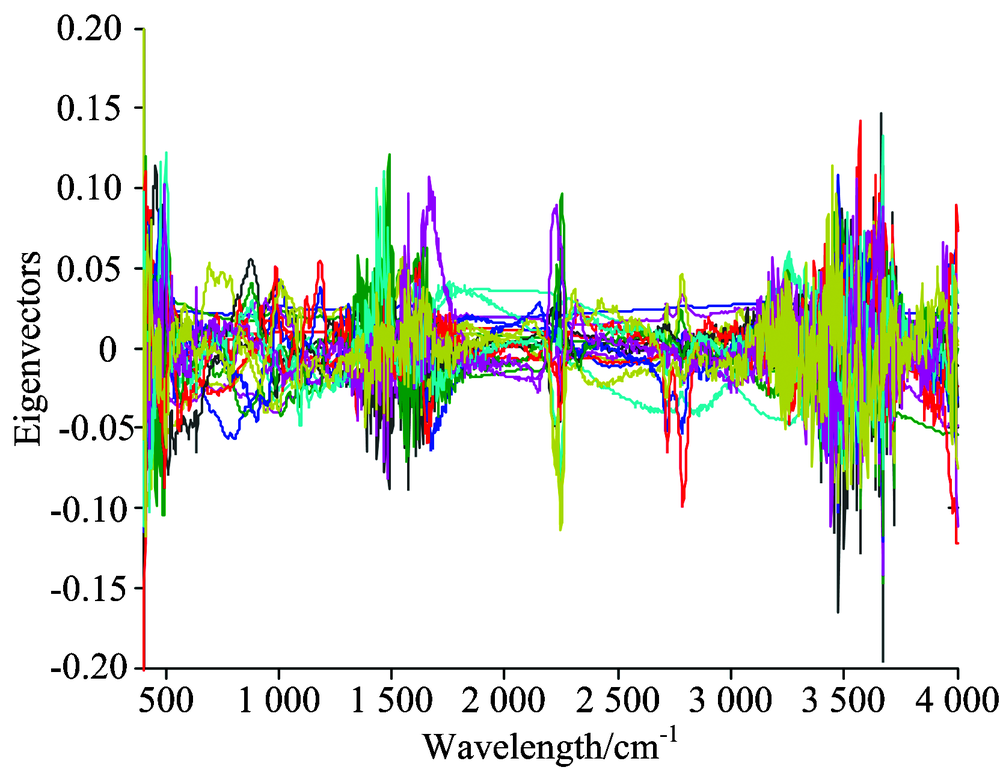 | 图2 PCA的前20个特征向量Fig.2 First 20 eigenvectors of PCA |
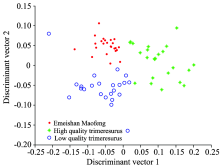
将茶叶光谱投影到这20个特征向量上得到维数降为20维的光谱数据。 每种茶叶样本中选取8个样本组成训练样本, 剩余的样本构成测试样本, 则每类测试样本是24个。 针对训练集样本, 用LDA计算它们的鉴别向量, 计算可得两个鉴别向量和两个特征值(λ 1=102.57, λ 2=55.0)。 然后将测试样本投影到LDA的两个鉴别向量上以实现测试样本的压缩, 测试样本被压缩为两维数据, 其得分图如图3所示。 在图3中, 符号“ · ” , “ * ” 和“ ” 分别代表“ Emeishan Maofeng” , “ High quality trimeresurus” 和“ Low quality trimeresurus” 三种茶叶的测试样本。 从图3可看出, 优质乐山竹叶青茶叶数据比较松散, 而其余两种茶叶数据比较紧凑, 紧凑的数据更易于分类。
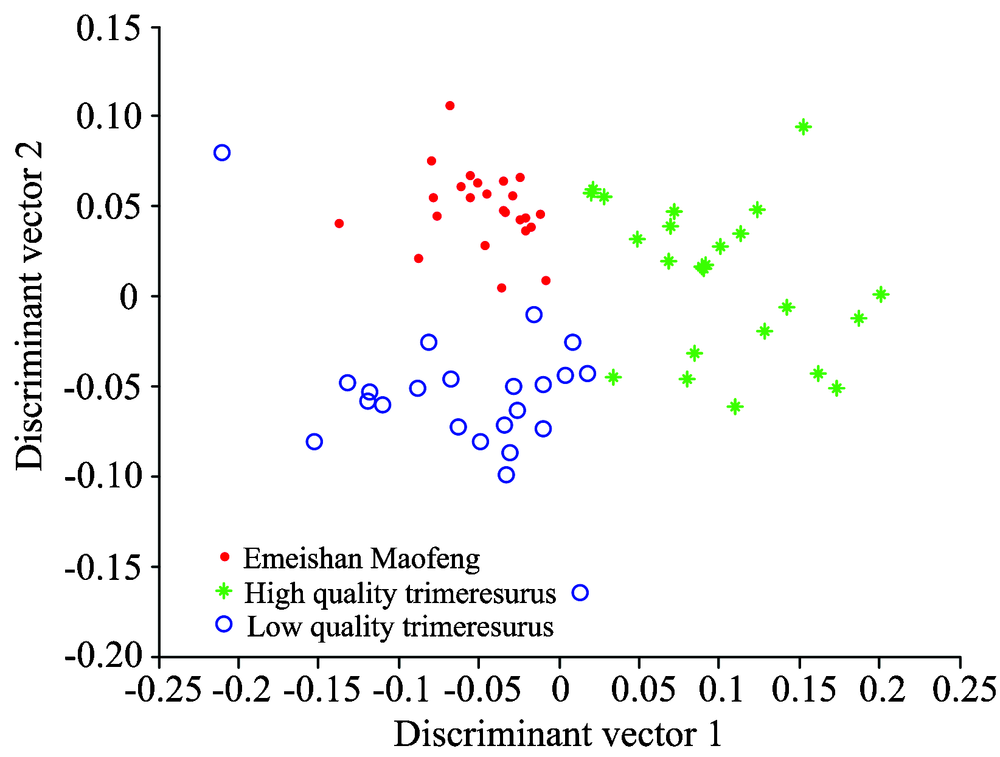 | 图3 LDA的得分图Fig.3 Scores plot of linear discriminant analysis |
计算4.1节的两维训练样本的每类均值并以此构成K调和均值聚类和可能模糊K调和均值聚类的初始聚类中心C(0)
式(8)中,
运行KHM和PFKHM之前需要设置它们的初始化参数: 聚类的类别数目k=3, 待聚类的数据个数n=72和权重指数m=2, q=2和p=2, 设置迭代次数初始值r=1和最大迭代次数为rmax=100, 设置迭代最大误差参数ε =0.000 01; 正常数a=1和b=3。 KHM和PFKHM的初始聚类中心设置见4.2节所述。
4.3.1 聚类准确率
当权重指数m=2, q=2和p=2时, KHM和PFKHM的聚类准确率分别为91.67%和94.44%。 当改变权重指数m值, m=2~10时PFKHM的聚类准确率变化如图4所示, 由于KHM没有权重指数m, 则KHM的聚类准确率为91.67%, 保持不变。 由图4可知, 当权重指数m变化时, PFKHM的聚类准确率要高于KHM的准确率。
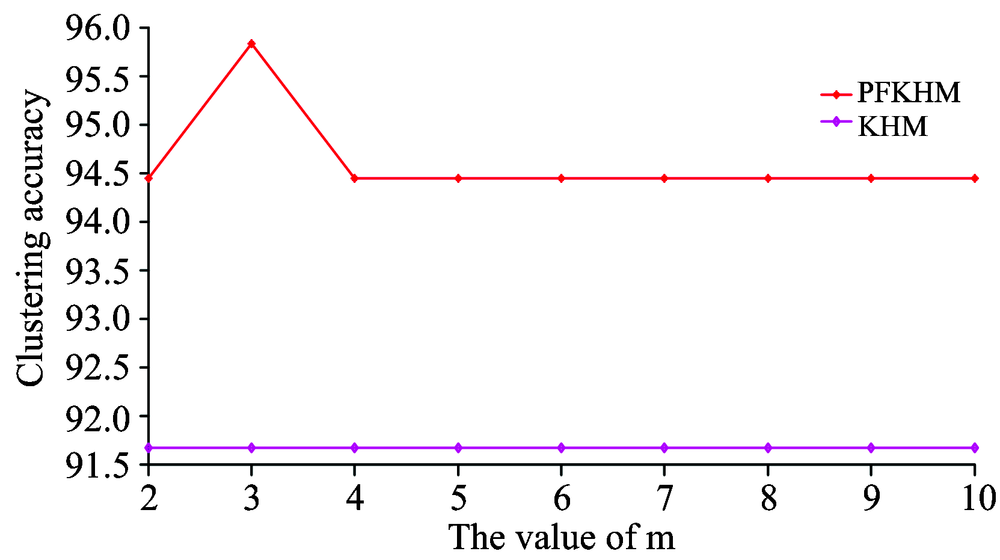 | 图4 KHM和PFKHM的聚类准确率Fig.4 The clustering accuracy of KHM and PFKHM |
4.3.2 聚类收敛和聚类时间分析
设置KHM和PFKHM的聚类初始化参数和4.3节相同。 运行KHM和PFKHM, 得到的收敛情况如图5所示。 KHM经过12次迭代后可以达到收敛, 而PFKHM经过11次迭代收敛。 所以, PFKHM的迭代次数少于KHM。 KHM的聚类时间为0.047 s, PFKHM的聚类时间为0.172 s。 则PFKHM完成聚类所花费的时间比KHM多。
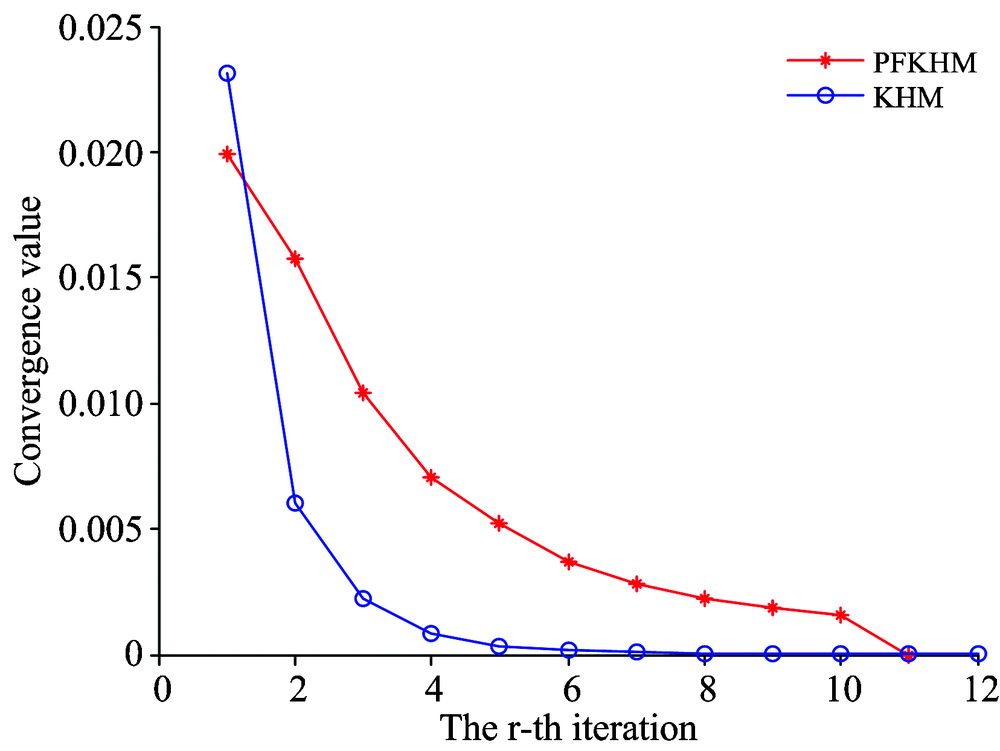 | 图5 KHM和PFKHM的收敛状况Fig.5 Convergence of KHM and PFKHM |
4.3.3 PFKHM的模糊隶属度值
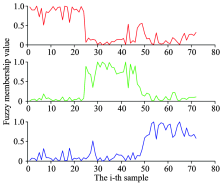
设置KHM和PFKHM的聚类初始化参数和4.3节相同。 分别运行KHM和PFKHM的聚类算法达到收敛后, 可得到KHM的隶属度值和PFKHM的模糊隶属度值和典型值。 对于第i个测试样本xi, 如果KHM的隶属度值uij, KHM> 0.5则判定xi属于第j类; 同样, 如果PFKHM的模糊隶属度值uij, PFKHM> 0.5, 则判定xi属于第j类。 PFKHM的典型值tij, PFKHM与模糊隶属度不同, 第i个测试样本xi有3个典型值, 若tik, PFKHM(k=1, 2, 3)为3个典型值中的最大值,
则判定xi属于第k类。 PFKHM的聚类迭代终止后, 在用其模糊隶属度值和典型值划分茶叶测试样本数据时取得相同的聚类准确率94.44%。 PFKHM的模糊隶属度值和典型值分别如图6和图7所示。
 | 图6 PFKHM模糊隶属度值Fig.6 Fuzzy membership value of PFKHM |
 | 图7 PFKHM典型值Fig.7 Typicality value of PFKHM |
在K调和均值聚类(KHM)基础上引入可能模糊C均值聚类(PFCM)思想[14, 15], 提出了一种可能模糊K调和均值聚类(PFKHM)。 可能模糊K调和均值聚类算法解决了K调和均值聚类的噪声敏感性问题。 可能模糊K调和均值聚类可同时得到模糊隶属度和典型值, 其聚类准确率比K调和均值聚类更高, 收敛速度比K调和均值聚类更快。 结果表明: 采用傅里叶红外光谱技术检测茶叶, 用主成分分析和线性判别分析压缩光谱数据, 再用可能模糊K调和均值聚类进行品种分类可快速、 准确地实现茶叶品种的鉴别。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|