





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于有序NPsim矩阵的颜色近邻搜索
[张廷1, 2  , 王功明
, 王功明3, * ]
, 王功明]
|
|


作者简介: 张廷, 1980年生, 中央民族大学信息工程学院实验师 e-mail: tozhangting@126.com
基于光谱表示法颜色近邻搜索的核心是高维向量近邻搜索, 相似性度量和索引树构建是影响其性能的关键, 前者存在等距性问题, 后者存在构建困难、 查询效率低、 不易动态调整等问题, 从而严重影响颜色近邻搜索算法的性能。 使用NPsim函数计算颜色相似性, 结合有序矩阵组织颜色空间数据, 提出一种基于有序NPsim矩阵的颜色近邻搜索算法。 首先, 计算颜色空间中所有颜色之间的NPsim值, 构建反映所有颜色相似性关系的NPsim矩阵; 然后, 按照每种颜色与其他颜色的相似性, 对NPsim矩阵的每行元素降序排列, 从而得到反映每种颜色与其他颜色相似性大小关系的有序NPsim矩阵; 最后, 对于颜色空间中任意给定的颜色, 根据它在有序NPsim矩阵中的行号, 就能够直接找到该颜色的所有近邻。 采用蒙赛尔全光泽色系光谱构建有序NPsim矩阵, 同时建立KD树和SR树, 分别进行 K近邻搜索, 并从精度和速度两方面比较。 在精度方面, 本算法得到的颜色近邻与查询颜色距离最近、 相似性最好, 存在逆序现象的近邻个数最少; 在速度方面, 构建有序NPsim矩阵的时间比构建KD树和SR树的时间要长, 但近邻搜索速度是KD树/SR树的1万倍左右, 而且与K值无关; 此外, 构建有序NPsim矩阵易于并行化, 而构建KD树和SR树不易并行化, 并行化后构建有序NPsim矩阵的速度会超过构建KD树和SR树的速度。 实验结果表明该方法适用于颜色近邻搜索。
The core of color nearest neighbor search based on spectral representation is high dimensional nearest neighbor searching, which is affected by equidistance of similarity measurement and low query efficiency of indexed tree seriously. To solve this problem, a color nearest neighbor search algorithm based on sequential NPsim matrix was proposed. First of all, the NPsim values between every two colors in color space were calculated and stored into the corresponding position of the NPsim matrix. After that, the elements in each raw of NPsim matrix were sorted in descending order to represent the similarity degree from strong to weak. Finally, the Top-K neighbors of given color can be found directly according to its raw number in the sequential NPsim matrix. To validate this algorithm, the nearest neighbor search algorithms based on KD-tree or SR-tree were compared on Munsell spectral data set. Experimental results indicated that the precise was better than that of other algorithms, the construction time of sequential NPsim matrix was longer than that of them, but the searching speed was more than thousands times of others and independent of K value. In addition, the construction of sequential NPsim matrix was easy to be paralleled to speed up, but the parallelization of construction of KD-tree or SR-tree was difficult.
引 言
在给定的颜色空间中, 寻找与给定颜色相似性处于前几名的颜色, 称为颜色近邻搜索, 搜索结果称为给定颜色的近邻。 颜色近邻搜索在颜色修复、 颜色设计、 颜色识别等领域有重要作用[1]。 基于光谱表示法的颜色近邻搜索, 主要是在颜色空间中执行给定颜色光谱向量的近邻搜索。 光谱是不依赖与客观环境和观察者而存在的物体固有物理特性, 可以反映颜色本身的色彩特征与颜色之间建立一一对应关系, 避免“ 同色异谱” 带来的颜色种类不确定性。 光谱由颜色在不同波长处的光谱反射比构成, 可视为长度有限的向量。 基于光谱表示法的颜色近邻搜索, 核心是向量近邻搜索。
常用向量近邻搜索算法有点集Voronoi图法、 空间分块法等, 对低维数据性能良好。 但是, 颜色光谱是高维数据, 具有数据稀疏、 维度灾难等特征[2], 搜索性能不佳。 因此, 高维数据近邻搜索是数据挖掘领域的难题之一, 但也是具有现实意义和理论价值的研究领域。 目前, 针对该问题已进行一定程度研究。 位置敏感的哈希法可以降低高维数据等距性问题[3], 但是采用相同哈希函数族, 没有考虑数据差异, 适用性有限。 针对该缺陷, Zhang等提出自学习哈希方法(self taught Hashing, STH), 但是时空复杂度较高; 此外, 理论研究表明, 哈希方法不易找到所有满足要求的近邻。 iDistance和向量近似方法(vector approximation, VA)适用于高维数据精确近邻搜索, 但数据访问率过高, 查询代价较高。
影响高维数据近邻搜索效果的主要因素是相似性度量和索引树构建, 解决这两方面存在的问题, 才能从本质上改善其性能。 目前, 大多数方法没有综合考虑维度属性相对差值、 噪声分布、 权重等因素, 仅对某些特定类型数据有效。 易莉桦提出的Psim(X, Y)函数综合考虑上述因素[5], 适用于多种类型数据。 但其值域取决于空间维度, 无法比较数据在不同维度下的相似性, 不利于降维分析, 本研究提出NPsim(X, Y)函数解决该问题。 高维数据索引树构建困难、 查询效率低、 不易动态增加和删除; 使用NPsim(X, Y)函数计算相似性, 得到相似矩阵, 并对每行元素排序, 生成有序NPsim矩阵。 该矩阵能表示高维空间每个点与其他点的远近关系。
在给定颜色空间中, 采用光谱表示颜色, 并生成有序NPsim矩阵表示颜色相似性, 能解决高维数据自身特性对颜色近邻搜索的干扰, 提高搜索准确性。 此外, 采用有序NPsim矩阵组织颜色空间数据, 可以直接得到任意颜色的任意近邻, 搜索速度快。 为了验证该算法, 采用蒙赛尔全光泽色系颜色光谱制作模拟数据, 并与基于KD树和基于SR树的颜色近邻搜索算法比较性能。 结果表明, 本算法精度高、 稳定性强, 搜索速度优势明显。
影响颜色近邻搜索的主要因素是相似性度量和索引树构建。 近年来, 科研人员围绕上述两方面展开研究, 取得一定进展, 但存在不足。
在相似性度量方面, 杨风召等提出Hsim(X, Y)函数[4], 是高维数据相似性度量的开端, 性能明显优于欧式距离, 但没考虑相对差值和噪声分布。 黄斯达等提出Gsim(X, Y)函数[5], 考虑维度属性相对差值, 但没考虑其权重差异。 邵昌昇等根据函数e-x单调递减特性, 提出Close(X, Y)函数[6], 能减少绝对差较大维度的影响, 但没考虑维度属性的相对差值, 也不能完全避免噪声维的影响。 王晓阳改进Hsim(X, Y)函数和Close(X, Y)函数[7], 综合属性值大小的影响, 提出Esim(X, Y)函数, 但该函数在不同维的分量与该维的值正相关, 当X与Y在噪声维的数据相似且远大于正常维的数据时, 得到的Esim(X, Y)分量会影响相似性计算的有效性。 郏宣耀采用二次度量方法计算相似度[8], 综合属性分布相似度、 空间距离等因素, 但没考虑噪声分布及权重, 而且公式复杂, 计算繁琐。 Hinneburg等提出投影最近邻的概念, 通过降维解决问题, 但很难找到合适的质量准则函数。 上述方法没有全面考虑影响相似性度量的若干因素, 仅适用于某些特定类型数据。 易莉桦提出Psim(X, Y)函数, 综合考虑维度属性相对差值、 噪声分布、 权重等因素, 通过分析不同维数据的差异, 剔除噪声维和稀疏维, 适用于独立同分布、 相关同分布、 非独立同分布等多种类型数据。 但是, Psim(X, Y)函数值域是[0, n], 其中n是空间维度, 不同维度的相似性没有可比性, 不利于数据降维。
高维空间索引树有两种: 基于向量空间的索引树、 基于度量空间的索引树。 前者典型代表是R树, 它是B树在高维空间的扩展, 能解决高维空间数据搜索问题; 然而, R树有兄弟结点重叠、 多路查询、 空间利用率低等问题。 因此, 出现R树变形种类, 如R+树、 R* 树、 cR树等。 后者典型代表是VP树, 它是度量空间的二叉搜索树, 适用于大规模数据搜索, 但属于静态树, 无法插入和删除, 且距离计算次数较多, 有时要借助缓存。 MVP树是对VP树的改进, 能减少距离计算次数, 但创建及查询时间复杂度高于VP树。 M树是用B树表示的哈希索引, 在高维空间搜索效率很高, 但只能等值查找, 不支持范围查找。 SA树按照结点和根结点远近关系创建, 是完全静态的索引结构, 无法插入和删除。
在维
(1)有界性: F(X, Y)∈ [0, 1];
(2)对称性: F(X, Y)=F(Y, X)。
通常采用距离函数Dist(X, Y)间接度量Sim(X, Y), 主要方法有: 曼哈顿距离、 欧几里德距离等, 这些方法适用于低维空间。 但是, 随着维度增加, 传统方法的最近距离和最远距离趋于相同, 相似性不再具有区分度。 针对该问题, 研究人员重新定义适用于高维空间的相似性度量方法, 包括: Hsim(X, Y), Gsim(X, Y), Close(X, Y), Esim(X, Y)等。 但是, 它们仅对某些特定类型数据有效, 不适用于所有数据。 易莉桦提出的Psim(X, Y)适用于多种类型数据, 但其值域依赖于空间维度n, 不利于数据降维分析。 本工作将其修改为式(1)形式, 在保持效果不变情况下, 值域约束在[0, 1]。
其中, Xj和Yj是X和Y在第j维的值, δ (Xj, Yj)是判别函数, 当Xj和Yj处于同一区间[nj, mj]时, δ (Xj, Yj)=1, 计算X和Y在第j维相似性; 否则, δ (Xj, Yj)=0, 认为第j维是噪声维或稀疏维, 不予计算; mj和nj是Xj和Yj共同隶属的区间端点; E(X, Y)是X和Y具有相同区间编号的维度个数。 关于不同维度上数据区间划分方法。
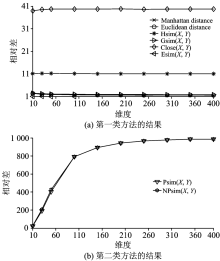
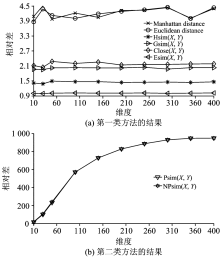
为了验证该方法效果, 采用Matlab生成三种不同分布类型数据: 独立同分布IID、 相关同分布Uniform、 非独立同分布DID。 每种类型按照维度10, 30, 50, 100, 150, 200, 250, 300, 350和400各生成1 000条数据。 按照式(2)计算最远邻和最近邻的相对差[4]。
其中, Dmaxn, Dminn, Davgn分别表示数据在n维空间的最大、 最小、 平均相似度。 分别测试曼哈顿距离、 欧几里德距离Hsim(X, Y), Gsim(X, Y), Close(X, Y), Esim(X, Y), Psim(X, Y)和NPsim(X, Y), 结果如图1— 图3所示。
按照结果特征, 测试方法分两类。 第一类包括曼哈顿距离、 欧几里德距离Hsim(X, Y), Gsim(X, Y), Close(X, Y), Esim(X, Y); 第二类包括Psim(X, Y)和NPsim(X, Y)。 后者比前者的相对差高出两到三个数量级, 所以第二类方法性能远远优于第一类方法。
 | 图1 独立同分布IID数据的相对差Fig.1 Relative difference of independent identical distribution data |
 | 图2 相关同分布Uniform数据的相对差Fig.2 Relative difference of relative identical distribution data |
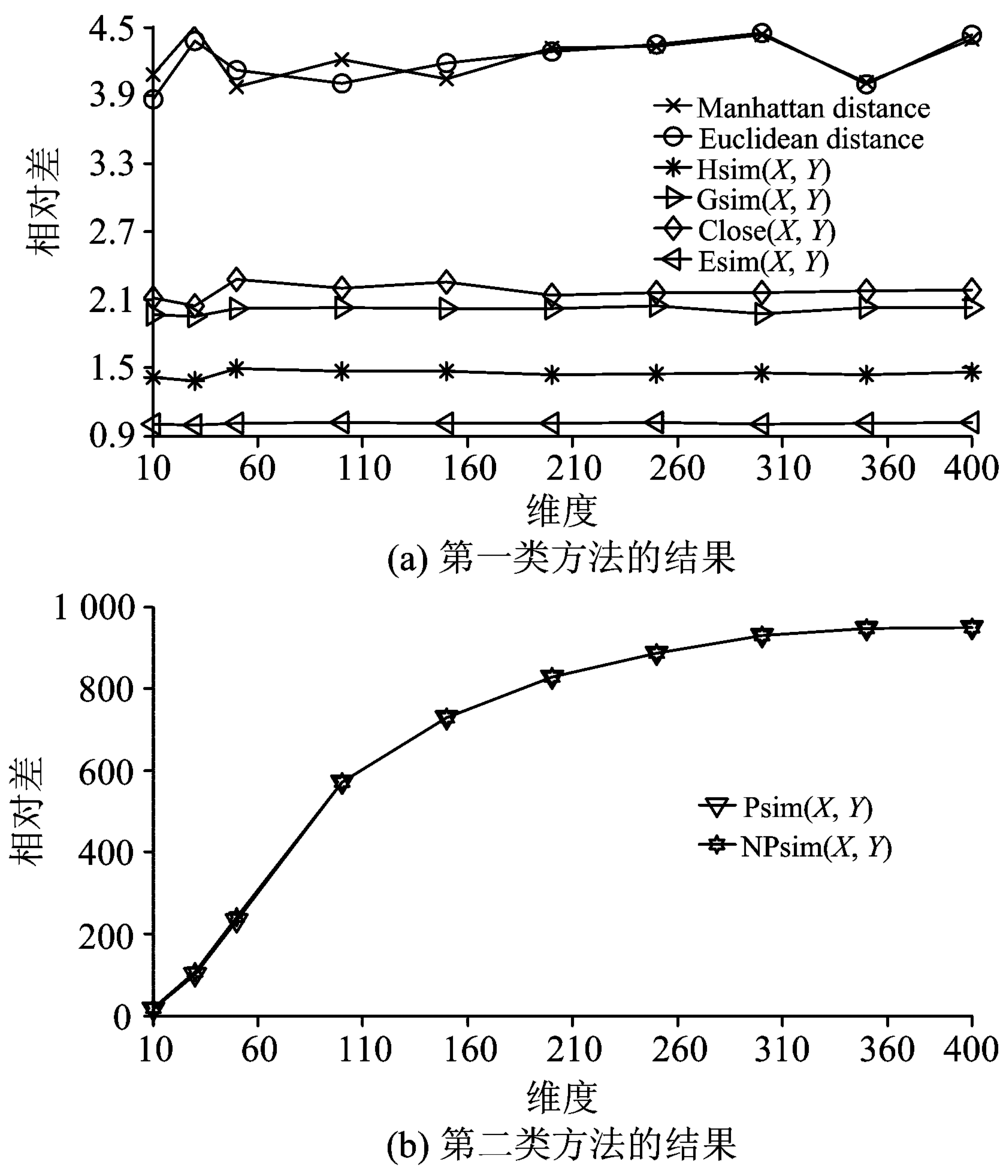 | 图3 非独立同分布DID数据的相对差Fig.3 Relative difference of dependent identical distribution data |
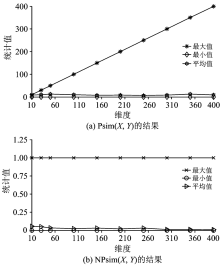
为了比较NPsim(X, Y)和Psim(X, Y)的效果差异, 分别采用NPsim(X, Y)和Psim(X, Y), 计算DID数据的相似性, 其最大值、 最小值和平均值随维度变化如图4所示。 可以看出, Psim(X, Y)的值域随维度增加而增大, 不利于比较数据在不同维度下的相似性, 而NPsim(X, Y)的相似性范围是[0, 1], 不受维度影响。 在不同维度下, Psim(X, Y)相似性超过1的个数如表1所示。 本组实验共计得到1 000× 1 000=100万个相似性, 但Psim(X, Y)方法却有6%~15%的结果超过1, 不同维度数据相似性不再具有可比性。 因此, 使用NPsim(X, Y)方法, 可以满足不同维度下相似性比较的需要。
 | 图4 采用DID数据比较两种方法的效果Fig.4 Effect comparison of two methods with DID data |
| 表1 在不同维度下, Psim(X, Y)方法相似性超过1的个数 Table 1 The number of calculated distance that is more than 1 with Psim(X, Y) method in different dimensionalities |
在给定的颜色空间中, 采用光谱表示颜色, 可以将每个颜色表示为唯一的高维数据。 NPsim的核心是将差异较大的维度视为噪声维, 不参与相似度计算; 人眼分辨颜色时, 对于颜色上与整体差异较大、 没有明显含义的区域, 视为噪声不参与比较。 可以看出, NPsim函数计算相似性的原理和人眼-颜色感知模型原理相似。 因此, 采用NPsim(X, Y)计算方法, 能准确得到颜色空间中任意颜色之间的相似性。 与其他方法相比, 该方法减少高维数据“ 维度灾难” 对颜色相似性计算的影响, 提高计算精度。
在n维空间Rn中, M个点S1, S2, …, SM构成M× N矩阵NPsimMat, 称为NPsim矩阵, 该矩阵元素NPsimMat[p][q]保存点Sp和Sq(1≤ p, q≤ M)之间的NPsim信息, 包括三个属性: 下标p, q, NPsim值。 可以看出, NPsim矩阵能够表示任意点之间的相似性。
对NPsim矩阵每行元素按照NPsim值降序排列, 得到有序NPsim矩阵SortNPsimMat。 该矩阵表示点之间的相似性大小, 对第p行元素来说, 随着列号增加, 点Sp和对应点的相似性逐渐降低。
将颜色空间中的颜色表示为对应光谱, 然后计算出所有颜色之间的有序NPsim矩阵。 该矩阵每行元素的NPsim值逐渐递减, 表示其他颜色与该行所表示颜色的相似性逐渐减弱, 视为以NPsim值为索引的递减数据序列。 由此可知, 整个有序NPsim矩阵构成给定颜色空间所有颜色的索引树, 进一步提高颜色近邻搜索的效率。
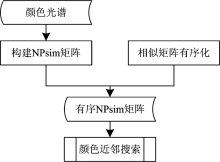
在给定颜色空间中, 构建有序NQsim矩阵表示颜色索引树, 能够直接找到任意颜色的所有近邻, 该方法整体框架如图5所示。
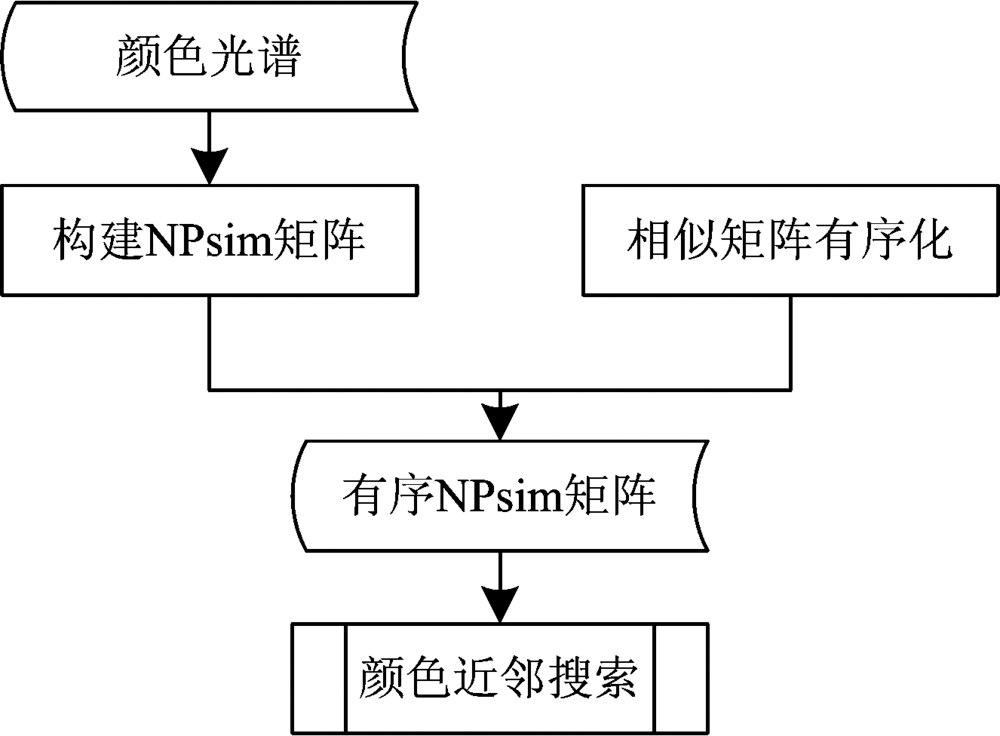 | 图5 算法整体框架Fig.5 Whole algorithm framework |
首先, 计算颜色空间中所有颜色之间的NPsim值, 构建NPsim矩阵; 然后按照相似性, 对NPsim矩阵的每行元素降序排列, 得到有序NPsim矩阵。 根据有序NPsim矩阵, 可以进行颜色近邻搜索。
3.2.1 构建NPsim矩阵
本阶段生成表示所有颜色相似性关系的NPsim矩阵, 设颜色空间中有多种颜色, 每种颜色采用长度为n的光谱表示。 主要步骤如下:
Step 1: 将光谱表示为n维空间Rn中的点Si, i=1, 2, …, M, 逐行保存在M× n矩阵DataSet中;
Step 2: 对DataSet每列元素按照升序排列, 得到矩阵SortDataSet;
Step 3: 将SortDataSet每列元素划分为G=$\lceil$θ · n$\rceil$个区间, 每个区间点的个数T=$\lceil$M/G$\rceil$; 同时, 按照升序将每个区间端点保存在矩阵FirCutBound中;
Step 4: 参照矩阵FirtCutBound, 将矩阵DataSet元素值转换为所在维度区间编号, 得到区间编号矩阵FirNumSet;
Step 5: 建立M× M矩阵SameDimNum, 其元素SameDimNum[p][q]保存点Sp和Sq在所有维中区间编号相同维的个数;
Step 6: 将矩阵SortDataSet每列元素划分为G'=G-1个区间, 每个区间点的个数T'=|M/G'|, 同时, 按照升序将每个区间端点保存在矩阵SecCutBond中;
Step 7: 仿照Step 4, 得到区间编号矩阵SecNumSet;
Step 8: 仿照Step 5, 修改矩阵SameDimNum, 如果点Sp和Sq某一维在Step 4区间编号不同, 但在Step 7区间编号相同, 那么SameDimNum[p][q]增加1;
Step 9: 根据式(1), 以及Step 3— Step 9的数据, 构建NPsim矩阵NPsimMat, 该矩阵规模M× M。
3.2.2 相似矩阵有序化
本阶段生成表示每种颜色与其他颜色相似性大小关系的有序NPsim矩阵, 主要步骤如下:
Step 1: 建立M× M矩阵SortNPsimMat, 初始值与NPsimMat相同;
Step 2: 对SortNPsimMat的每行元素, 按照NPsim值降序排列。
3.2.3 近邻搜索
在SortNPsimMat中对第i种颜色进行K近邻搜索方法如下:
遍历该矩阵的第i行, 找出最前面K个NPsim矩阵元素, 在这些元素所对应颜色中, 异于第i种颜色的颜色, 就是第i种颜色的K近邻。
由附录1可知, 构建有序NPsim矩阵时间复杂度O(M2n), KD树近邻搜索算法和SR树近邻搜索算法构建索引树时间复杂度均是O(Mlog2M· n)[9], 所以本算法在构建阶段性能亟待改进。 但是, 在K近邻搜索时, 本算法时间复杂度为O(1), 能直接确定给定颜色的K个近邻, 且搜索时间与K值无关; 而其他两种方法需要遍历索引树, 时间复杂度O(Klog2M), 搜索时间随K值增加而增加, 所以本算法在搜索阶段性能优秀。
由附录2可知, 通过修改数据结构, 能够将第三类和第四类中间矩阵构建阶段的时间复杂度降低一个幂次; 通过预先存储、 代码外提等策略, 可以降低有序NPsim矩阵的生成时间。 此外, 第一类中间矩阵的逐列元素排序和第四类中间矩阵的逐列元素比较具有独立性, 所以这两类矩阵易于并行构建, 但索引树不易并行构建。 因此, 通过并行构建, 能够将本算法时间复杂度降低为O(Mn), 超过传统算法的速度。
本算法包括构建和搜索两个过程, 所以待比较的近邻搜索算法也要包含这两个过程。 基于KD树的颜色近邻搜索算法是构建KD树, 然后进行搜索, 基于SR树的颜色近邻搜索算法也类似。 因此, 以蒙赛尔光谱数据为例, 测试三种算法。
蒙赛尔全光泽色系包含1 600种颜色, 所有颜色按照色调(H)、 亮度(V)、 饱和度(C)三个维度排列在蒙赛尔色立体中, 表示为HV/C。 其中, 色调包括10种基本色调: 红(R)、 黄红(YR)、 …、 紫(P)、 红紫(RP), 每种基本色调又划分为10等分, 在基本色调字母前面添加数字1~10; 亮度共分11级: 0, 1, …, 10, 其中0最暗, 10最亮; 纯度共分14种: 1, 2, …, 14, 其中1表示纯度为0, 14表示纯度为100%。
从光谱颜色研究中心(http: //www.uef.fi/fi/spectral/home)下载蒙赛尔全光泽色系所有颜色的光谱反射比数据。 测量设备是Perkin-Elmer Lambda 18 UV/VIS光谱仪, 测量范围是380~780 nm, 测量步长是1 nm。 因此, 这套数据包含1 600条数据, 每条数据是对应颜色在401种不同波长下的光谱反射比, 构成长度为401的高维数据。
首先, 使用蒙赛尔色系光谱建立有序NPsim矩阵; 同时建立KD树和SR树, 统计构建有序NPsim矩阵、 KD树和SR树的时间。 然后, 在蒙赛尔色立体上选择颜色, 进行K近邻搜索。 因为蒙赛尔色立体具有色彩连续性。 所以, 对蒙赛尔色立体颜色进行近邻搜索时, 查询颜色和近邻在色立体上的位置必定接近或连续。
因此, 从实际距离和视觉效果两方面比较精度。 一方面, 比较不同算法的查询颜色与K近邻距离的均值。 按照蒙赛尔色系颜色表示方式, 分别用HV/C和HKVK/CK表示查询颜色和K近邻, 则二者之间的距离如式(3)
式(3)即查询颜色和K近邻之间的曼哈顿距离, 亮度和饱和度已经量化, 可以直接计算|VK-V|和|CK-C|; 但色调没量化, 不能直接计算|HK-H|。 色调量化方法: 保持亮度和饱和度不变, 从1R开始, 环绕蒙赛尔色立体一周, 到10RP结束, 将中间100个点设置为1, 2, …, 100。 色调量化后可以直接计算|HK-H|。
另一方面, 选择一个颜色代表所有待查询颜色, 比较该颜色在三种算法下的K近邻颜色差异。
在速度分析方面, 因为KD树和SR树进行K近邻搜索的时间与K有关, 所以让K从1逐渐增加, 计算平均搜索时间; 同时, 也计算本方法在不同K值下的平均搜索时间。
根据4.2节的方法, 从蒙赛尔色立体中选择1 000个查询颜色, 采用本方法、 基于KD树和SR树的方法进行K近邻搜索, 并在速度和精度两方面比较。 实验环境: 处理器AMD Athlon(tm) II X2 250 Processor 3.01 GHz、 内存韩国现代2G、 操作系统Windows XP SP3、 开发环境VS 2013, 无并行加速措施。
4.3.1 精度分析
采用三种方法, 在不同K值下, 所有查询颜色与其K近邻距离的均值和方差如图6和图7所示, 可以看出, 与基于KD树/SR树的颜色近邻搜索算法相比, 本方法得到的颜色近邻在整体上与查询颜色距离更近, 距离波动性更低。 说明本算法精度高、 稳定性强。
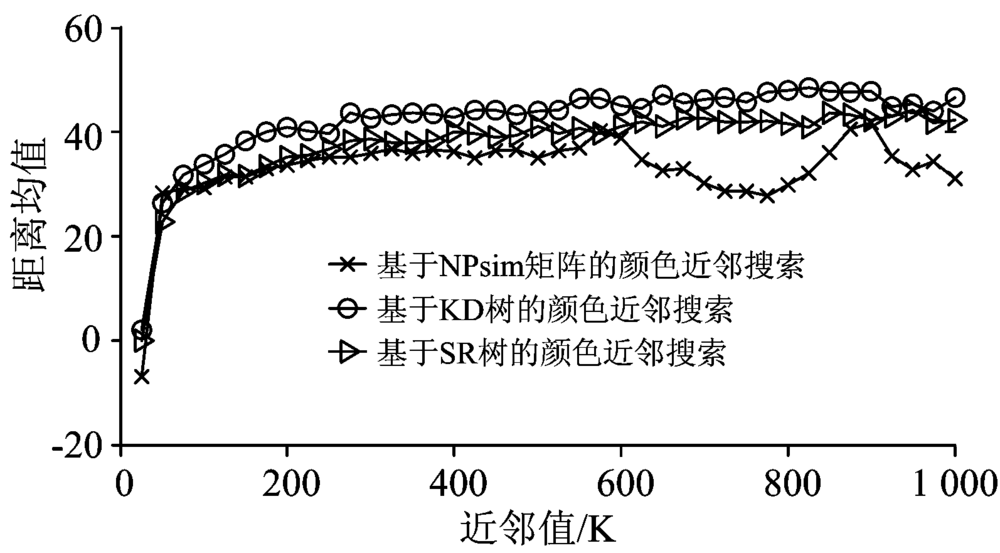 | 图6 所有查询颜色的K近邻距离均值Fig.6 Mean KNN distance of all queried colors |
 | 图7 所有查询颜色的K近邻距离方差Fig.7 KNN distance variance of all queried colors |
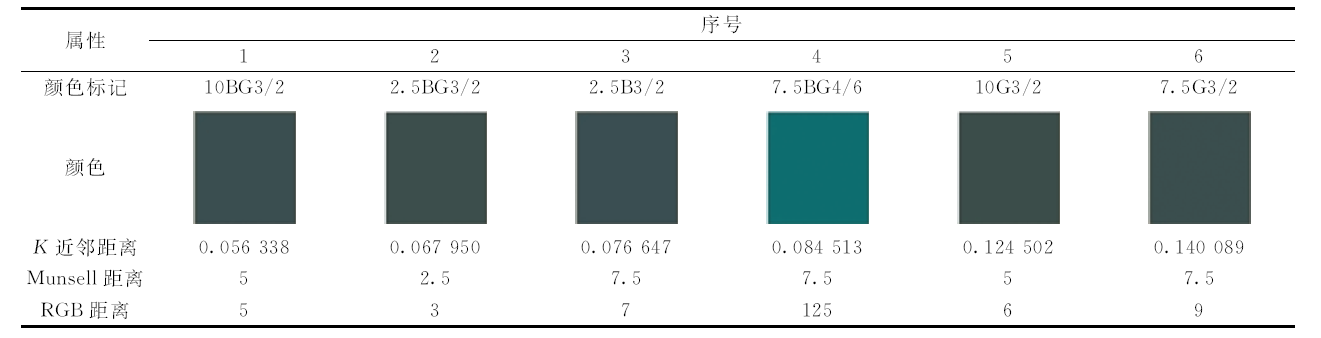
选择的查询颜色为5BG3/2, 色彩如图8所示, 令K=6, 三种算法的K近邻如表2— 表4所示。 表2的K近邻距离是NPsim函数相似性, 其值越来越小; 表3和表4的K近邻距离是欧式距离, 其值越来越大。 为了更直观度量色彩差异, 还计算查询颜色和其K近邻在RGB颜色空间的距离(RGB分量差绝对值之和)。 从色彩角度可知, 基于NPsim矩阵的颜色近邻搜索算法, 所得近邻与查询颜色最相似; 基于KD树/SR树的颜色近邻搜索算法, 所得某些近邻, 其颜色与查询颜色存在差异。 从蒙赛尔距离角度可知, 本算法所得近邻距离小于其他两种方法, 而且存在逆序现象(近邻距离在近邻序列中的相对次序与其序号的相对次序不同, 即近邻序列中某近邻前驱、 近邻本身、 近邻后继与查询颜色的距离不满足递增关系)的近邻个数也较少, 表2逆序近邻有2个(10BG3/2和5BG3/1), 表3逆序近邻有4个(10BG3/2, 2.5BG3/2, 5B3/4和5G3/4), 表4逆序近邻有4个(10BG3/2, 2.5BG3/2, 7.5BG4/6和10G3/2)。
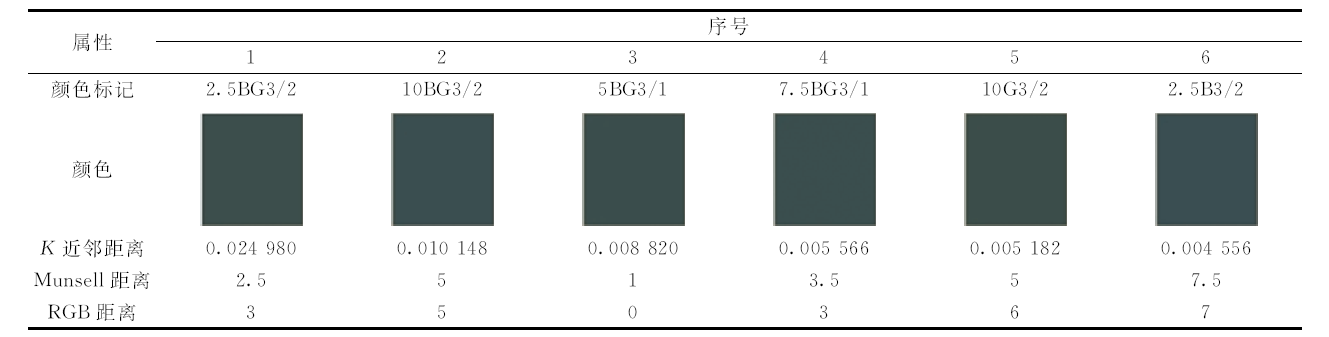 | 图8 5BG3/2的颜色Fig.8 Color of 5BG3/2 |
| 表2 基于有序NPsim矩阵的颜色近邻搜索算法结果 Table 2 Color neighbor searching result based on sequential NPsim matrix |
| 表3 基于KD树的颜色近邻搜索算法结果 Table 3 Color neighbor searching result based on KD tree |
| 表4 基于SR树的颜色近邻搜索算法结果 Table 4 Color neighbor searching result based on SR tree |
在表2中, 颜色近邻的视觉差异很小, 但光谱存在一定差异, 属于“ 同色异谱” 现象。 采用传统色差公式, 如蒙赛尔距离、 RGB距离等, 计算结果的差异不大, 区分度不好。 但是, 采用NPsim函数计算距离, 结果具有明显的区分度。 由此可知, NPsim函数在高维度颜色差异评价时优势明显。
4.3.2 速度分析
在构建阶段, 三种方法耗时如表5所示。 可以看出, 构建有序NPsim矩阵的时间比构建KD树和SR树的时间要长。
在搜索阶段, 这些方法在不同值下近邻搜索的平均响应时间如图9所示。 可以看出, 本算法响应时间数量级在10-6左右, 而其他两种方法响应时间数量级在10-2左右, 本算法速度是其他两种方法的1万倍左右; 此外, 本方法响应时间与值无关, 而其他两种方法响应时间随K值增加而增加, 所以本方法速度优势明显。
| 表5 构建阶段三种方法消耗的时间 Table 5 Running time in the establishment stage of three methods |
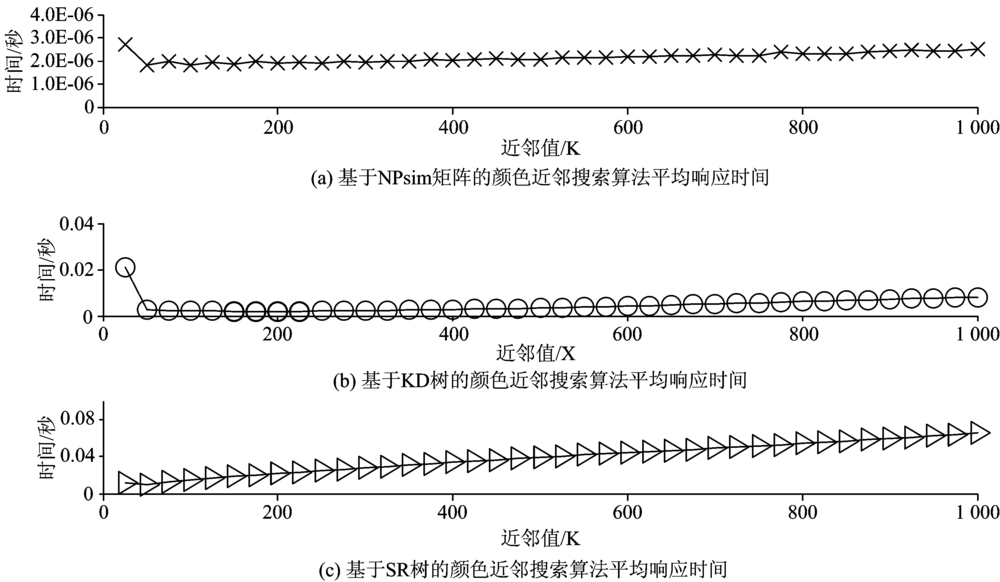 | 图9 三种方法在不同K值下近邻搜索的平均响应时间Fig.9 Average searching time of three KNN methods in different K |
本算法构建有序NPsim矩阵的时间复杂度O(M2n), 而构建KD树和SR树的时间复杂度O(Mlog2M· n); 所以本算法在构建阶段耗时大。 但是, 构造出有序NPsim矩阵后, 本算法可以直接访问矩阵得到颜色近邻, 时间复杂度O(1), 而其他两种方法都需要在KD树或SR树中进行检索, 时间复杂度O(Klog2M), 所以本算法在搜索阶段速度优势明显。
颜色近邻搜索在颜色科学中具有重要的作用, 其核心是高维向量近邻搜索, 传统方法在相似性度量和索引树构建上存在问题, 影响颜色近邻搜索的效果。 本文采用NPsim函数计算高维向量相似性, 结合有序NPsim矩阵组织颜色空间数据, 在一定程度改善了颜色近邻搜索算法的性能。 为了验证该算法, 采用蒙赛尔光谱数据进行颜色近邻搜索实验, 并与基于KD树和SR树的颜色近邻搜索算法进行比较。 结果表明, 该算法在精度和速度上优势明显。
本算法构建有序NPsim矩阵的时间复杂度O(M2n), 而构建KD树和SR树的时间复杂度O(Mlog2M· n), 从而导致本算法在构建速度上逊色于传统方法。 但是, 有序NPsim矩阵易于并行构建; 而树形结构不易并行构建。 所以, 在本算法的构建阶段实施并行化, 有望将其时间复杂度降为O(Mn), 超过传统方法的速度。
本算法包括构建和搜索阶段。 构建阶段包含两个步骤:
(1) 构建NPsim矩阵
需要生成四类中间矩阵。 第一类是SortDataSet, 对每列元素升序排列而生成, 时间复杂度O(MlogM· n)。 第二类是FirCutBound和SecCutBound, 遍历矩阵所有元素而生成, 时间复杂度O(Mn)。 第三类是FirNumSet和SecNumSet, 通过定位每个元素在列上的位置而生成, 时间复杂度O(M2n)。 第四类是SameDimNum, 对任意两行元素逐列比较而生成, 时间复杂度O(M2n)。 最后, 对任意两行元素逐列计算NPsim分量并累加, 生成NPsimMat, 时间复杂度O(M2n)。 所以该步骤时间复杂度O(M2n)。
在空间复杂度方面, SortDataSet, FirNumSet和SecNumSet是O(Mn), FirCutBound和SecCutBound是O(Gn)=O($\lceil$θ n$\rceil$n)=O(n2), SameDimNum和NPSimMat是O(M2)。 所以该步骤空间复杂度O(Mn+n2+M2)。
(2) 相似矩阵有序化
对NPsimMat每行元素按照NPsim值降序排列, 时间复杂度O(MMlogM)=O(M2logM)。 SortNPsimMat规模是M× M, 空间复杂度O(M2)。
因此, 构建阶段时间复杂度O(M2n), 空间复杂度与M, n大小有关, 当M≥ n时, 空间复杂度为O(M2), 反之为O(n2)。
添加数据点时, 首先计算它和其他数据点的NPsim值, 时间复杂度O(Mn); 然后逐行计算待添加元素的位置, 时间复杂度O(Mlogn); 随后移动每行位置之后的元素, 时间复杂度O(M2); 最后对新增加的一行元素降序排列, 时间复杂度O(MlogM); 通常情况下, M> logn, 整体时间复杂度-O(Mn+M2)。 删除数据点时, 首先逐行计算待删除元素的位置, 时间复杂度O(Mlogn); 然后移动每行位置之后的元素, 时间复杂度O(M2); 最后删除与该元素有关的行, 时间复杂度O(M); 整体时间复杂度O(M2)。 修改数据点时, 首先计算它与其他数据点的NPsim值, 时间复杂度O(Mn); 然后对它所在的行降序排列, 时间复杂度O(MlogM); 最后逐行重新定位被修改元素的位置, 并移动其他元素, 时间复杂度O(M2+MlogM)=O(M2); 整体时间复杂度O(Mn+M2)。
在搜索阶段, K近邻搜索需要访问第i行前K个元素, 时间复杂度是O(1)。
附录2 构建有序NPsim矩阵算法的优化
构建NPsimMat主要包括两个步骤: 计算中间矩阵、 生成NPsimMat。
中间矩阵包括四类, 时间复杂度最高的是第三类和第四类, 均为O(M2n)。 采用下述方法可以降低构建该阶段的时间复杂度。
将DataSet的元素改为结构体, 每个结构体包含两个元素: Value, OrigOrder。 对元素DataSet[i][j]来说, Value是点Si在第j维的值, OrigOrder是Value在第j维的序号, 初始为i。 排序时对DataSet的每列元素按照Value值升序排列, 得到矩阵SortDataSet, 元素SortDataSet[i][j]的OrigOrder表示排序前元素在第j维的序号。
在遍历SortDataSet生成FirCutBound时, 可以同时生成FirNumSet。 其方法是: 按照升序遍历SortDataSet的每列元素, 设置指示器PosBound表示SortDataSet[i][j]在第j维的区间编号, 在遍历每列元素时, PosBound随着i的增加不断增大; 访问SortDataSet[i][j]时, 根据OrigOrder可以确定其在DataSet中的行号, 由此可知, FirNumSet[OrigOrder][j]=PosBound; 逐个访问SortDataSet中的元素, 就可以生成FirNumSet。 构建SecNumSet也相似, 因此, 构建FirNumSet和SecNumSet的时间复杂度O(Mn)。
借助SortDataSet可以快速生成SameDimNum, 原理: 如果元素Sa和Sb在第j维区间编号相同, 那么它们必处于SortDataSet第j列元素的同一区间。 由此得出快速算法: 将SameDimNum所有元素初始化为0; 把SortDataSet每列元素分成若干区间, 每个区间点的个数为T; 设第j维某区间任意两点的OrigOrder为a和b, 则说明元素Sa和Sb在第j维的区间编号相同, 使SameDimNum[a][b]增加1; 逐个访问SortDataSet中的元素, 就可以生成首次等深划分后的SameDimNum。 二次等深划分会继续增加SameDimNum的某些元素值, 主要方法如下: 把SortDataSet每列元素分成若干区间, 每个区间中点的个数为T'; 设第j维某区间任意两点的OrigOrder值为a和b, 若元素Sa和Sb在首次等深划分中不在第j维的同一区间, 那么SameDimNum[a][b]增加1; 逐个访问SortDataSet中的元素, 就可以完成二次等深划分后对SameDimNum的调整。 在生成首次等深划分后的SameDimNum过程中, 访问SortDataSet元素次数为M$\lceil$
可以看出, 采用该方法可以将构建第三类、 第四类中间矩阵的时间复杂度由3次方降低为2次方, 可以提高构建NPsimMat的速度。
经过上述优化后, 构建NPsimMat的运算瓶颈转移到根据中间矩阵生成NPsimMat, 该阶段要逐列计算NPsim分量并累加, 其基本操作个数是M2n, 不易减少, 所以很难直接降低其时间复杂度。 但是, 由式(1)可以看出, 在累加中存在大量重复计算, 如1/(mi-ni), 1/n等, 可以预先存储计算结果, 使用时直接调用; 此外, 累加中存在若干循环不变量, 可以采用代码外提来优化。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|