

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
小麦黑胚病识别模型优选和多分类识别分析
[吴婷婷1, 2, 3  , 余克强
, 余克强1, 2, 3 , 张海辉1, 2, 3, * , 冯毅4, * , 张晓1 , 汪辉辉1 ]
, 余克强, 冯毅|
|


作者简介: 吴婷婷, 女, 1982年生, 西北农林科技大学机电学院讲师 e-mail: tt_wu@nwsuaf.edu.cn
为探讨利用可见/近红外光谱进行小麦黑胚病快速无损检测的可行性, 以及基于主流机器学习算法, 寻找面向生产的小麦黑胚病优化识别模型, 利用自行研发的近红外光谱采集平台采集了579~1 099 nm波段23个品种共2760个小麦单籽粒的吸光度光谱数据, 采用标准正态变量变换(SNV)进行预处理之后分别经过SPA(successive projections algorithm), PCA(principal component analysis)等两种数据降维方法, 结合ELM(extreme learning machine), SVM(support vector machine), RF(random forest)和AdaBoost等四种分类方法, 分别构建SPA-SVM, SPA-ELM, SPA-RF, SPA-AdaBoost, PCA-SVM, PCA-ELM, PCA-RF, PCA-AdaBoost八种小麦黑胚病识别模型; 结果表明小麦黑胚籽粒的识别准确率达到93.3%~98.6%, 识别效果优于前人文献中利用近红外波段的识别效果; 其中SPA-SVM模型具有最高的识别率, PCA-AdaBoost模型具有更好的普适性。 将SPA-SVM模型和PCA-AdaBoost模型作为优选模型, 从生产实际出发, 分别对未感病+轻感病、 中感病+重感病籽粒进行了二分类识别, 对未感病, 轻感病+中感病、 重感病籽粒进行了三分类识别, 以及对未感病、 轻感病、 中感病、 重感病籽粒进行了四分类识别, 并深入分析了识别效果和产生原因。 总体来说, 小麦黑胚粒的识别准确率随分类程度的细化而下降, 二分类的识别模型可直接用于生产, 尽管三分类和四分类的感病粒识别效果较差, 但是对未感病粒的检出率则不受分类程度的影响, 识别率在87.2%以上, 符合生产需求。 综合来看, SPA-SVM模型分类效果优于PCA-AdaBoost模型, 可作为首选识别模型, 该研究为小麦籽粒黑胚病的在线批量快速检测提供了技术依据。
In order to explore the feasibility of detecting wheat kernel black tip (BT) disease and investigating an optimized classification model based on mainstream machine learning algorithms, a large amount of 2 760 wheat kernels spectral data of Vis/NIR bands (579~1 099 nm) were collected by self-made spectral acquisition platform. After pretreated with standard normal variate correction (SNV) of 600~1 045 nm bands, 7 kinds of data sets were established. Successive Projections Algorithm (SPA) and Principal Component Analysis (PCA) of spectral data dimensionality reduction methods, and four machine learning algorithms, Support Vector Machine (SVM), Extreme Learning Machine (ELM), Random Forest (RF) and AdaBoost, were adopted to develop eight classification models. Results showed that Vis/NIR spectrums combined with all the machine learning methods could be used to detect BT disease with accuracies ranging from 93.3% to 98.6%, which indicated that Vis/NIR would be the more effectively compared to NIR. As SPA-SVM possessed a high average classification accuracy and PCA-AdaBoost showed better generalization performance than other algorithms, considering practical purposes, these two algorithms were adopted as optimized models in 2-category classification, 3-category classification and 4-category classification for various degrees of BT detection. Results indicated that the classification accuracies declined gradually with the classification number increasing, but the detection accuracy of non-diseased wheat kernel tended to be stable with an accuracy of more than 87.2%. Taken together, SPA-SVM performed better than PAC-AdaBoost in wheat BT disease detection. The models and conclusions of this research are intended to lead to the streamlining of VIS/NIR spectroscopy in automated wheat black tip inspection as well as to provide criteria for high speed sorting.
小麦黑胚病在世界各麦区均有发生, 它由一种或多种真菌病原引起, 主要症状是在籽粒胚部或周围出现深褐色斑点, 带病籽粒不仅影响出苗和幼苗生长力, 更会降低籽粒品质, 甚至具有毒性和致突变作用。 我国小麦国家标准(GB 1351— 2008)将小麦黑胚粒列为不完善粒, 实行限量/制收购。
目前黑胚病粒识别主要靠人工检视, 存在工效低、 准确性差, 不能保证严格分级等缺陷。 随着机器视觉技术、 光谱检测技术在农产品无损检测中的快速发展, 国外研究者逐渐将这些技术引入到小麦黑胚病检测中。 Fox等[1]使用近红外光谱仪来检测大麦籽粒黑胚病, 结果表明与C— O和N— H键相关的1 868~1 888 nm是检测黑胚病的关键波段。 Delwiche等[2]捕获多角度小麦籽粒图像进行黑胚病识别。 Armstrong等[3]证明了近红外光谱检测手段可以用于不同发病程度病粒的识别, 并指出由于黑胚病状外观可直接观测, 采用可见/近红外光谱检测有可能获取更多的特征信息, 从而实现更好的分类效果。
本工作在探寻可见/近红外光谱对小麦籽粒黑胚病的识别效果基础上, 探讨主流机器学习方法对不同发病程度籽粒的识别性能。 基于特征提取和模型优选, 寻找面向生产的小麦黑胚病优化识别模型。
以小麦籽粒为研究对象, 供试样本由美国农业部农业研究处USDA-ARS-SPIERU提供, 于2012年和2013年间收集于美国堪萨斯州和俄克拉荷马州, 品名分别是(1)Armour, (2)Billings1, (3)Brawl CL Plus, (4)Byrd, (5)Denali, (6)Everest1, (7)Gallagher, (8)Iba, (9)LCH08-80, (10)LCS Mint, (11)Post Rock, (12)SY Gold, (13)SY Wolf, (14)T153, (15)T154, (16)T158, (17)Tam 111, (18) Tam304, (19)Billings2, (20)Duster, (21)Everest2, (22)Jagger, (23)Santa Fe等23个小麦种质资源。 根据实际感病程度, 每个品种经由人工检视分为四类[4]: (a)未感病粒(healthy kernel H); (b)轻感病粒(light suscept, LS); (c)中感病粒(moderate suscept, MS); (d)重感病粒(heavy suscept, HS), 四种感病籽粒各30粒, 共计2760个样本, 典型样本见图1。
 | 图1 四种不同感病程度的小麦籽粒样本 (a): 未感病粒H; (b): 轻感病粒LS; (c): 中感病粒MS; (d): 重感病粒HSFig.1 Four different susceptibilities of wheat kernels (a): Healthy kernel; (b): Light suscept; (c): Moderate suscept; (d): Heavy suscept |
实验所用自制光源采用全包围结构, 工作电压5 V, 28 W, 入口处设有高灵敏度光纤红外对射传感器, 用以检测籽粒经过, 内置直径为12 mm的玻璃滑道, 如图2所示。 光谱信息采集单元为CDI PDA512型号光谱仪(Control Development Inc., USA), 波长范围579~1 099 nm, 分辨率1 nm。 基于C++语言开发光谱采集程序, 在籽粒经过玻璃滑道过程中获取吸光度光谱, 计算公式如式(1)
式(1)中, A为籽粒吸光度, R为漫发射率, Xraw为籽粒的反射光强值, Xref为光源工作时的反射光强值, Xdark为自然光下的反射光强值。
 | 图2 可见/近红外光谱检测光源Fig.2 VIS/NIRS spectroscopy light source |
1.3.1 光谱数据预处理
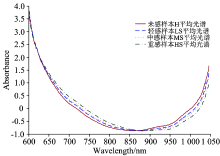
不同品种小麦籽粒大小不一, 外表面并非规则椭圆体, 内部物质也非均匀一致。 为消除光散射、 基线漂移等影响[5], 截取600~1 045 nm波段范围内的光谱信息, 并采用标准正态变量变换处理方法(standard normal variate, SNV)处理。 图3给出SNV处理后的四种感病程度籽粒的平均吸光度光谱, 可以看出其光谱曲线变化基本一致, 彼此接近, 说明分类模型的选择至关重要。
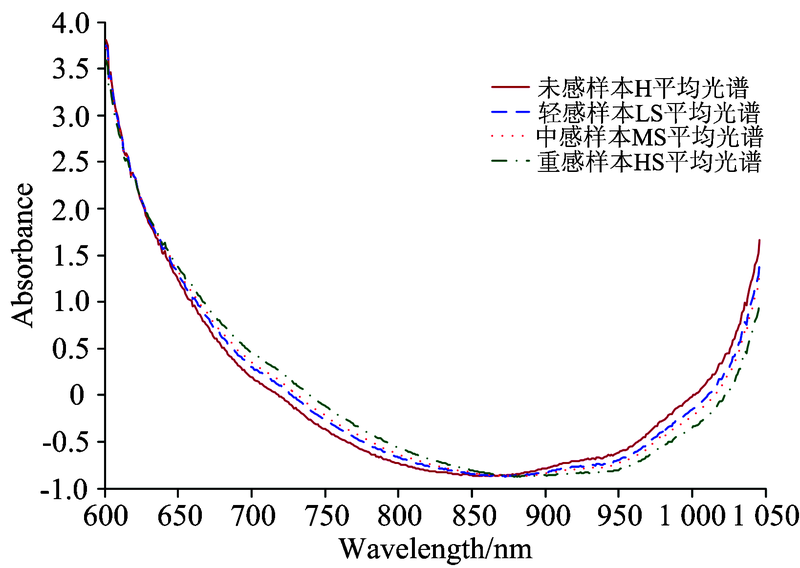 | 图3 归一化之后的样本吸光度平均谱线Fig.3 Average spectral absorbance with SNV pretreated |
1.3.2 数据处理流程
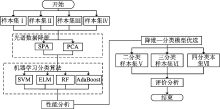
考虑到小麦不同品种的生物多样性对黑胚病检测的影响, 设计的实验流程如图4, 样本集构成如表1。 各训练集和预测集的划分方法采用SPXY(sample set partitioning based on joint x-y distance)方法[6], 其划分比例为2∶ 1。
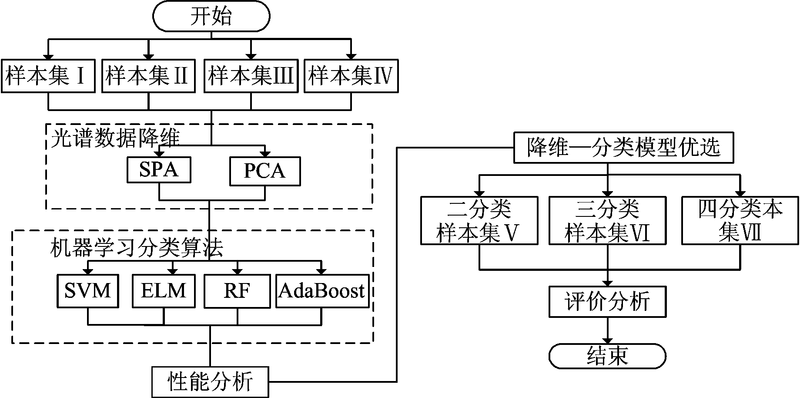 | 图4 实验数据处理流程图Fig.4 Block diagram of experimental data process |
| 表1 样本集划分说明 Table 1 List of wheat samples used as calibration and validation sets |
1.3.3 数据降维和分类方法
为减少光谱数据中冗余信息, 选取连续投影算法(successive projections algorithm, SPA)和主成分分析(principal component analysis, PCA)分别对预处理后的数据进行降维[7]。 选取四种典型的机器学习分类方法, 包括支持向量机(support vector machine, SVM)、 极限学习机(extreme learning machine, ELM)、 随机森林(random forest, RF)和AdaBoost算法[8], 结合前述两种光谱数据降维方法, 分别构建SPA-SVM, SPA-ELM, SPA-RF, SPA-AdaBoost, PCA-SVM, PCA-ELM, PCA-RF, PCA-AdaBoost八种模型。
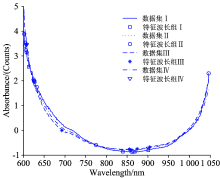
图5为样本集Ⅰ , Ⅱ , Ⅲ 和Ⅳ 的特征波长提取结果, 四个样本集的特征波长具有较好的重合性, 可以预见可见/近红外波段能够用于籽粒黑胚分类。 在近红外波段选取出的特征波长集中在C— H, N— H, O— H键的三倍频或四倍频左右[9], 从光谱上体现出小麦黑胚籽粒的外观与内部品质均发生了变化。
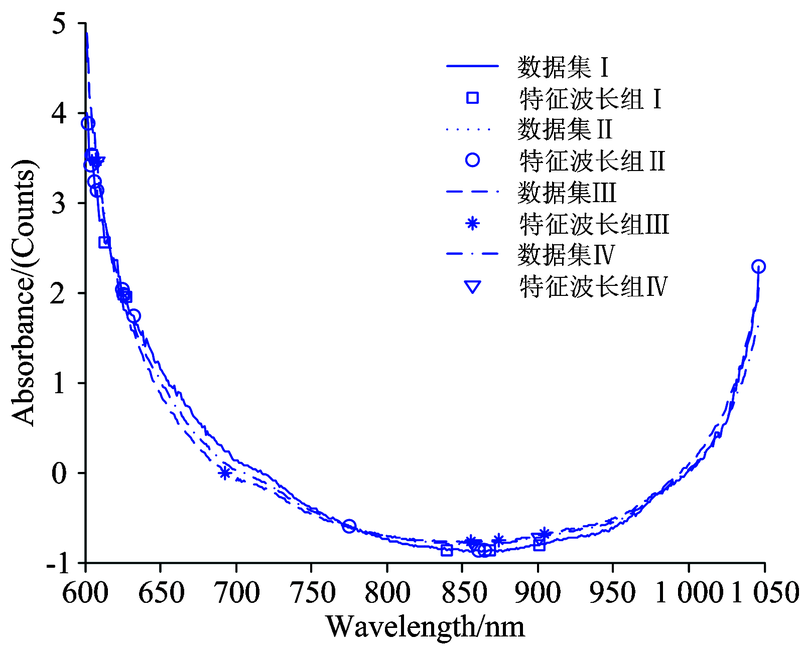 | 图5 四个样本集的SPA特征波长选择分布图Fig.5 Distribution of variable wavelength selected by SPA |
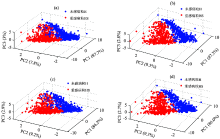
图6为样本集Ⅰ , Ⅱ , Ⅲ 和Ⅳ 基于PCA处理后的前三个主成分的得分聚类图, 可以看出, 前三个主成分的累计贡献率均达到了95%以上, H和HS有明显的分布差异, 说明了可见/近红外波段能够用于黑胚病分类。
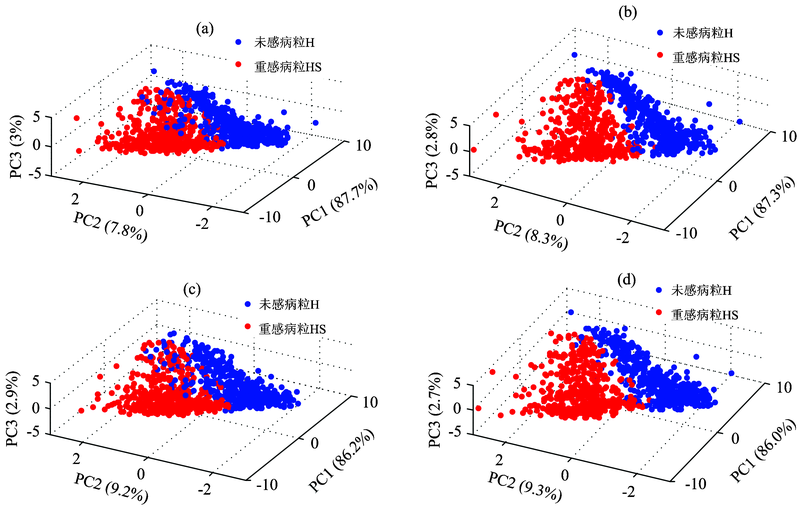 | 图6 样本集Ⅰ , Ⅱ , Ⅲ 和Ⅳ 前3个主成分的PCA得分图Fig.6 Samples 3D distribution based on PCA sample set Ⅰ (a), sample set Ⅱ (b), sample set Ⅲ (c) and sample set Ⅳ (d) |
2.2.1 可行性分析与模型优选
八种分类模型识别结果如表2所示, 识别效果在93.3%~98.6%之间, 说明可见/近红外波段较好地包含了黑胚病的光谱特征, 与文献[3] 的近红外波段识别效果相比, 在可见/近红外波段上的识别效果更高, 是小麦黑胚病无损检测的更有效手段。
| 表2 不同分类模型的分类结果 Table 2 Classification results with eight different models |
八种分类模型中, SPA-SVM具有最高的分类均值, 说明该模型对黑胚病的鉴别率平均表现性能最好, 但对样本集的差异较为敏感; PCA-AdaBoost分类模型尽管在总体识别率上表现一般, 但方差最小, 表现出对小麦品种差异具有更好的普适性。 因而, 优选这两种模型进一步分析多分类检测。
2.2.2 多分类识别结果分析与模型优选
考虑到生产中可能将发病程度较轻的籽粒认定成完善粒, 将数据集V分为两类, 其中H和LS作为健康类别, MS和HS作为黑胚类别, 分别对训练集使用优选模型后, 识别效果如表3。 与表2比, 尽管分类效果下降, 但黑胚病粒识别率仍在生产上可接受范围内, 且SPA-SVM模型识别率较高。
| 表3 不同分类模型的二分类结果 Table 3 2-category classification results |
为发挥最大经济效益, 小麦收购时会分拣出未感病粒, 弃用重感病粒, 轻感和中感病粒则用于二次加工或喂养牲畜等, 将样本集Ⅵ 划分为这三类之后的识别效果如表4。 值得注意的是, 三分类中H的识别率优于二分类中H+LS的识别率, 且均未误判成HS, 效果较理想。 LS+MS的识别率尚可接受, HS的识别率效果差, 可能的原因是LS虽然具有黑胚特征, 但是对籽粒品质本身影响并不大, 而MS的籽粒品质产生了明显变化, 更接近于HS, 因而在可见/近红外波段上, LS+MS与HS之间相互误判概率较大。 如将表4中的LS+MS和HS均认为是不健康粒的话, SPA-SVM模型则更优。
| 表4 不同分类模型的三分类结果 Table 4 3-category classification results |
进一步细分, 样本集Ⅶ 的四分类结果如表5, 未感病粒被判错的概率很低, 且不可能被判成中感或重感, 而轻感、 中感、 重感程度被判轻或判重的概率很高, 两种分类算法识别效果均不理想, 说明将病害类别划分过细时, 品种间的差异、 不同病原菌对发病症状的影响等因素不可忽略, 需要更深入研究。
| 表5 不同分类模型的四分类结果 Table 5 4-category classification results |
采用自行设计的可见/近红外光谱检测平台, 采集不同感病程度小麦籽粒的吸光度光谱曲线, 进行了数据降维和特征波长提取, 结合机器学习方法建立了八种黑胚病分类模型, 进行了对比分析, 结果表明, 可见/近红外波段是无损快速识别小麦黑胚病的更有效手段, 模型识别率在93.3%~98.6%, SPA-SVM模型具有最高的平均识别率, PCA-AdaBoost具有更好的泛化性能。
将这两种模型作为优选模型, 对比分析了实际生产中的无感病、 轻感病、 中感病和重感病等四种不同发病程度小麦, 分别进行了二分类、 三分类和四分类的识别研究。 结果表明, 随着分类程度的细化, 对小麦不同感病程度的识别率在降低, 四分类时对感病粒的判别已不适合生产, 三分类时对重感病粒的识别效果不佳, 二分类的识别效果在生产可接受范围内, 值得注意的是, 对无染病粒的鉴别效果不受分类程度的影响, 维持在一个较好的识别水平。 综合比较, SPA-SVM模型的识别效果优于PCA-AdaBoost模型, 可作为首选模型。
验证了可见/近红外波段对小麦黑胚病的识别效果, 优选的特征波长和机器学习方法以及相关结论, 为今后研制光电自动化高速检测仪器和开发在线识别模型, 实现无损、 自动化、 批量化小麦黑胚病籽粒分选提供了技术支持和参考依据。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|