{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
混合式随机森林的土壤钾含量高光谱反演
[王轩慧1, 2  , 郑西来
, 郑西来1, * , 韩仲志2 , 王轩力3 , 王娟4 ]
, 郑西来, 韩仲志|
|


作者简介: 王轩慧, 1978年生, 青岛农业大学理学与信息学院讲师 e-mail: margaretxuan@aliyun.com
从土壤速效钾光谱中挖掘关键特征较为困难, 导致高光谱反演模型预测精度较低。 针对此问题, 提出了一种混合式随机森林特征选择算法。 首先采用封装式特征选择方法进行特征预选, 快速去除冗余并保留相关特征, 然后再利用改进的随机森林特征选择算法对预处理后的特征进行精选, 通过增大关键特征与冗余特征的区分度以及采用迭代特征选择的方式, 使精选后的特征具有更好的鲁棒性与区分性, 较好的解决了土壤速效钾高光谱反演模型精度较低的问题。 为了验证所提出算法的有效性, 选取了青岛市大沽河流域具有代表性的124个土壤样品为实验对象, 利用提出的算法从2 051个原始波段选出含有13个敏感波段的最优光谱子集建立土壤速效钾反演模型, 并与现有特征选择算法所建模型进行对比分析。 结果表明: 该算法构建的回归模型具有较低的预测均方根误差RMSEP(9.661 5), 较高的相关系数 r(0.936 9)和预测分析相对误差RPD(2.14)。 混合式随机森林特征选择算法以较少的特征波长数实现了较好的预测效果, 可为土壤养分实时光谱传感器的设计提供一定的理论依据。
In order to solve the problem of lower prediction performance caused by the difficulty in retrieving the key features from hyperspectral data of soil available potassium, this paper proposes a novel hybrid feature selection algorithm based on Random Forests. Firstly, wrapper-based feature selection methods were applied to rapidly remove the redundancies and preserve the related features. Secondly, an Improved-RF feature selection algorithm was applied to further accurately select the wavelength variables from the pre-selected feature sets. In this step, characteristic wavelength with strong robustness and discriminative could be selected through improving the dipartite degree between the key and redundant features and using an iterative feature selection method. Therefore, the problem of low prediction performance in the soil available potassium inversion model could be better solved by using our hybrid feature selection algorithm. In order to verify the validity of our algorithm, 124 representative soil samples collected from the Dagu River Basin were chosen. Using our algorithm, the optimal feature subset which contained 13 sensitive bands have been selected and used to build soil available potassium content inversion model. This work compared the model performance of full bands, current feature selection algorithms and our algorithm. The comparison results indicated that our algorithm not only selects minimum numbers of wavelength features and reduces the dimension of full bands, but also achieves better prediction performance with lower RMSEP (9.661 5), higher R (0.936 9) and RPD (2.14). As an effective method of soil available potassium inversion model, the algorithm proposed in this paper can provide theoretical basis for the design of real-time soil nutrient sensors.
速效钾含量是土壤养分的重要组成部分[1], 实时、 准确监测速效钾含量对于“ 精准” 农业的发展具有重要意义。 应用传统化学方法[2]测量土壤速效钾含量, 存在成本高, 周期长, 实时性较差的缺点。 相比之下, 可见-近红外光谱具有成本低、 效率高、 无破坏性等优点[3]。 然而, 可见-近红外高光谱数据特征波长变量多, 冗余噪声信息量大, 如果直接用于速效钾含量预测不仅计算成本过大而且预测精度较低。 文献[4]指出, 选取合适的特征选择算法不仅能降低模型的计算复杂度, 而且能提高校验模型的精度和预测能力。 Iznaga等采用间隔偏最小二乘算法筛选出84个速效钾高光谱敏感波段, 成功建立了土壤速效钾可见-近红外校验模型[5]。 章海亮等将连续投影算法与偏最小二乘支持向量机相结合来预测速效钾含量, 预测结果的相关系数r和预测均方根误差RMSE分别达到0.730 5和15.78 mg· kg-1 [6]。 刘雪梅等采用基于Wrapper[7]型的蒙特卡洛-无信息变量消除算法作为特征选择方法, 筛选出150个速效钾敏感波段, 将其与偏最小二乘回归(partial least squares regression, PLSR)结合, 所建模型预测结果的相关系数r和预测均方根误差RMSE分别为0.76和15.4 mg· kg-1 [8]。 Jia等通过比较蒙特卡洛-无信息变量消除和连续投影两种特征选择算法在土壤速效钾高光谱反演中的性能, 发现蒙特卡洛-无信息变量消除算法结合偏最小二乘回归取得最佳预测效果。 该模型筛选出300个敏感波段, 预测结果的决定系数R2和预测均方根误差RMSE分别为0.75和14.2 mg· kg-1 [9]。
上述特征选择算法虽然已经应用于速效钾可见-近红外光谱建模中, 并取得了一定的成果, 但是仍然存在以下两点不足: (1)间隔偏最小二乘算法是一种线性的波长选择方法, 无法获取光谱数据与速效钾含量之间的非线性关系; (2)蒙特卡洛-无信息变量消除和连续投影这两种特征选择算法均采用单一指标评估特征的重要程度, 忽略了所选特征之间的冗余性, 导致选出的特征波段较多, 易出现过拟合现象。
为突出速效钾光谱特征的差异、 改善现有特征选择的局限性并提高模型反演能力, 提出了一种混合式特征选择算法。 该方法通过增大关键特征与冗余特征的区分度以及采用迭代特征选择的思想来提高获取关键特征的准确性。 为了验证该算法的有效性, 以大沽河流域土壤样品为实验对象, 将混合式特征选择算法与现有特征选择算法进行对比, 并评估特征选择算法与回归模型相结合的实用性。
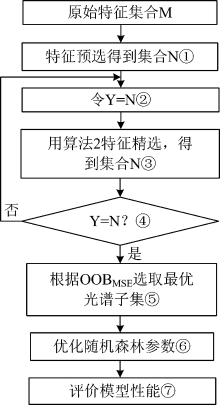
基于随机森林的混合式特征选择算法首先采用Wrapper型特征选择方法进行特征预选, 其次对预处理后的特征子集使用改进的随机森林特征选择算法进行特征精选; 最后通过迭代的方法逐步简化精选后特征子集, 根据均方误差的大小选取最优光谱子集。 该算法的总体流程图如图1所示。
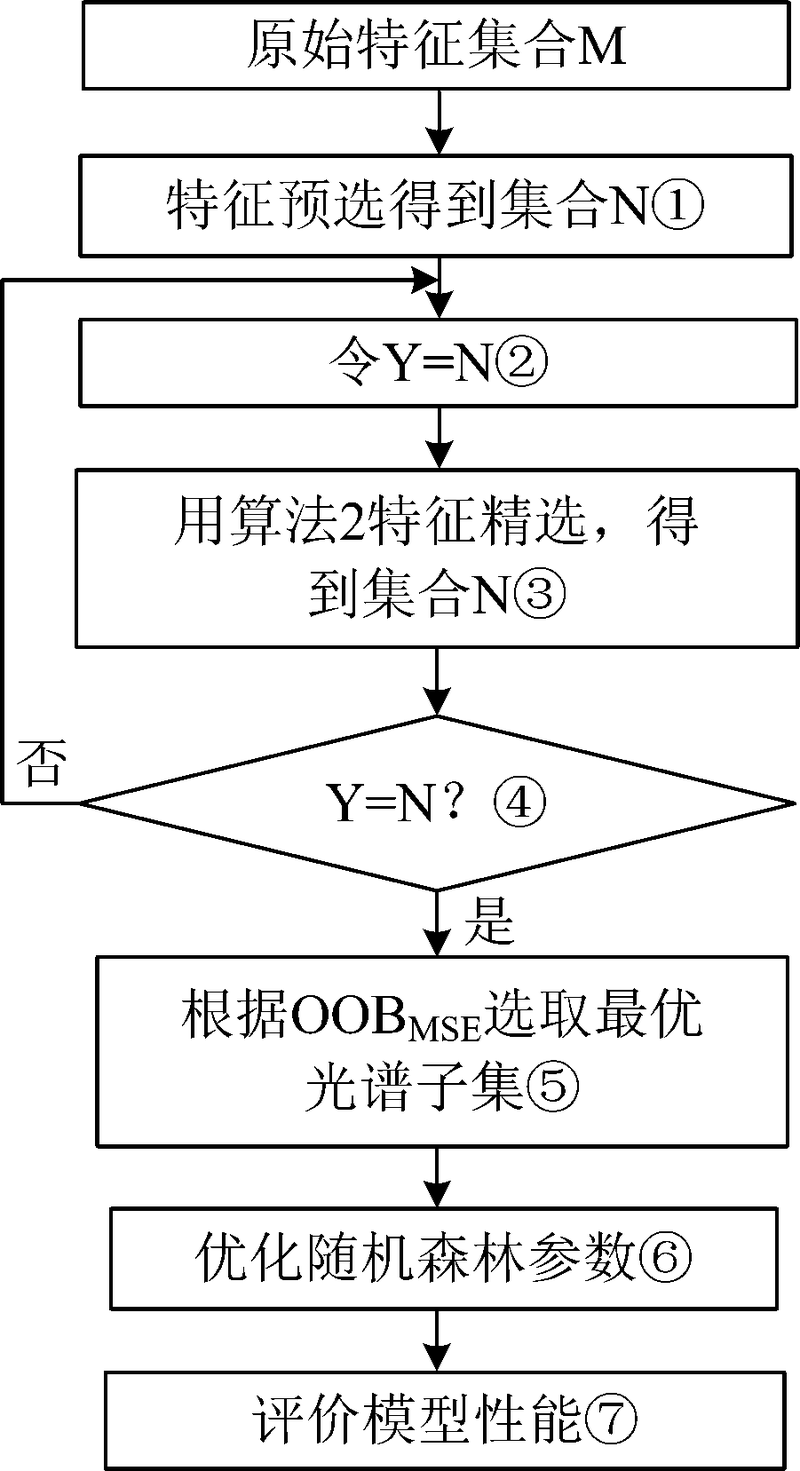 | 图1 基于随机森林的混合式特征选择算法流程图Fig.1 Flow chart of rardom forest-based hybrid feature selection algorithm |
基于随机森林的混合式特征选择算法主要包括四部分: 第一部分(step 1)进行特征波段预选, 剔除冗余特征和大量噪声数据; 第二部分(step 2— step4)进行特征波长精选与迭代; 第三部分(step 5)根据随机森林袋外估计的均方误差大小选出最优光谱子集; 第四部分(step 6— step7)利用随机森林回归对最优特征子集建立反演模型。
算法1: 基于随机森林的混合式特征选择算法。
输入: 预处理后的特征集合M; 特征选择(包括预选与精选)后得到的特征集合N。
输出: 最优光谱特征子集X; 预测模型及其性能指标。
Step 1: 采用基于Wrapper的特征选择方法进行特征预选, 得到预选后的特征集合为N, 其中N⊂M。
Step 2: 令Y=N。 Y为算法2的输入特征集合。
Step 3: 根据算法2进行特征精选, 得到精选后的特征集合N。
Step 4: 重复step 2— step3, 直至N与Y相等。 如果N与Y相等, 表明没有可以剔除的特征值。
Step 5: 首先按照公式(1)计算袋外数据集上的均方误差[10]OOBMSE, 然后再根据均方误差OOBMSE大小选取最优光谱特征子集X。
Step 6: 反复训练随机森林回归模型(random forest regression, RFR)[11], 获取随机森林最优参数组合ntree和mtry。
Step 7: 首先利用最优特征子集构建反演模型, 然后利用测试集进行预测。
说明: 式(1)中,
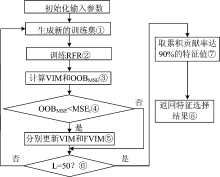
由于变量重要性评价在随机森林的特征选择算法中起着至关重要的作用, 因此我们针对单次随机森林计算变量重要性不准确的问题提出了改进的随机森林算法。 该算法通过增大特征值之间的光谱差异, 达到准确挑选关键特征的目的。 改进后的算法分为两个步骤: 第一步(step 1— step 6)在改变关键特征重要性得分计算方式的基础上, 逐步确定所有特征的最终重要性得分。 第二步(step 7— step 8)依据特征的重要性得分对其从大到小排序, 剔除贡献率不足90%的特征, 获取特征精选后的特征子集。 改进的随机森林特征选择算法的程序流程图如图2所示。
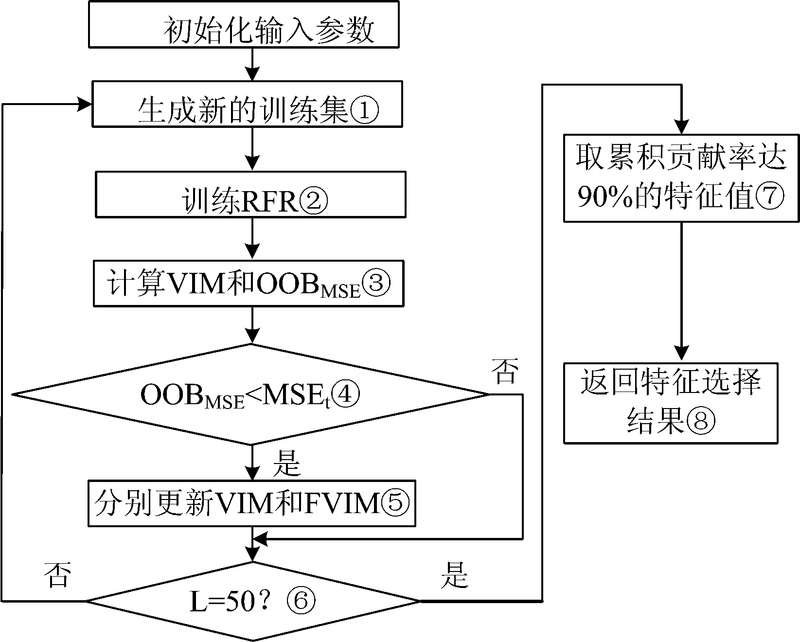 | 图2 改进的随机森林特征选择算法 (Improved-RF)程序流程图Fig.2 Flow chart of the Improved-RF algorithm |
改进的随机森林特征选择算法的具体描述如算法2所示。
算法2: 改进的随机森林特征选择算法(Improved-RF)。
输入: 特征集合Y; 关键特征和冗余特征的区分依据: 均方误差阈值MSEt← 1 500; 最终变量重要性得分:
输出: 精选后的特征集合N。
Step 1: 在原始训练集的基础上, 采用Bagging重采样方式[11]生成一个新的训练样本集。
Step 2: 在新训练样本集上训练随机森林回归模型。
Step3: 根据式(1)和式(2)分别计算袋外数据的均方误差OOBMSE和每个特征值的变量重要性评分(variable importance measure, VIM)[11]。
Step 4: 比较当前训练样本集对应袋外数据估计的均方误差OOBMSE与阈值MSEt。 如果OOBMSE大于阈值MSEt, 直接转入step 6, 否则转入step 5。
Step 5: 首先根据式(3)更新每个变量的重要性评分, 然后根据式(4)更新最终重要性评分(final variable importance measure, FVIM)。
Step 6: 重复step 1— step5, 直到达到最大循环次数。
Step 7: 依据FVIM对所有特征值降序排列, 保留累积贡献率达到90%的特征波段, 剔除剩余波段特征值。
Step 8: 精选后的特征集合N作为候选特征子集输出。
说明: ①式(2)中, OO
②通过多次实验确定均方误差的合理阈值MSEt, 以此作为式(3)中关键特征和冗余特征的区分依据。 式(2)对关键特征和冗余特征同等对待, 导致它们区分度较低。 为此, 我们对式(2)进行改进, 主要目的是加大关键特征和冗余特征的区分度。 对于冗余特征, 依然采用式(2)计算其重要性得分, 使得冗余特征的重要性得分不变。 对于关键特征, 我们在式(2)的基础上乘以一个放大因子, 该因子为袋外估计之均方误差的倒数, 达到提高关键特征重要性得分的目的。
实验数据为124个来自青岛市大沽河流域农田表层的土壤样本, 样品采集后先风干处理, 然后对其进行研磨和过筛(孔径大小18 mm), 将每一份土样分成两份, 一份用于高光谱数据采集, 一份按照国家标准[2]进行土壤速效钾浓度测定。 采用乙酸铵浸提-火焰光度法测量样品中速效钾的含量。
采用便携式高光谱仪ASD Field Spec 3在暗室内测定土壤可见-近红外光谱数据。 处理好的土样被置于直径10 cm、 深2 cm的培样皿中, 装满后将土壤表面刮平。 使用50 W 卤素灯作为光源, 光源距土壤表面35 cm, 天顶角为30° , 采用25° 视场角裸光纤探头, 探头位于土壤表面垂直上方15 cm处, 每测量10组土壤样品进行一次白板校正。 每个土样测量4个方向(转动3次, 每次90° ), 每个方向保存10 条光谱曲线, 算术平均后得到土样实际的反射光谱数据。
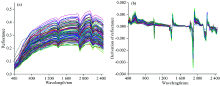
图3(a)为124份土壤样品原始可见-近红外光谱曲线图, 反射率曲线特征在形态上与其他研究中土壤样本的反射率曲线基本相似[12]。 对原始可见-近红外光谱剔除噪声较大的边缘波段350~399和2 451~2 500 nm, 再运用一阶导数变换和Savitzky-Golay(SG)卷积进行光谱平滑预处理。 图3(b)为经上述预处理后得到的光谱曲线图。
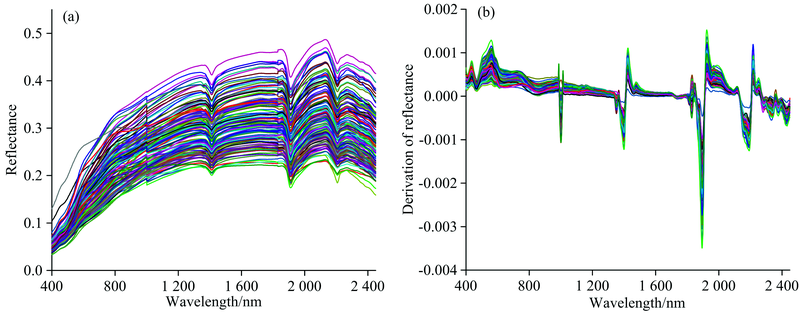 | 图3 原始土壤光谱曲线及其预处理后的光谱曲线 (a): 原始光谱反射率曲线; (b): 先一阶导数后SG卷积平滑的反射率曲线Fig.3 Raw spectral curves and spectral curves after pretreatment (a): Raw spectral reflectance curves; (b): After pretreatment with first derivative and SG convolution smoothing |
从图3(a)中可以看出, 不同土壤样品的光谱轮廓比较相近, 可见光波段(400~780 nm)光谱反射率小于近红外波段(780~2 450 nm), 在波长1 400, 1 900以及2 200 nm附近出现明显的水分吸收峰。 从图3(b)中可以看出, 预处理后的土壤样品光谱分布更为集中, 而且原始光谱吸收峰得到了明显加强。
原始光谱经预处理后, 运用主成分-马氏距离(principal component analysis-mahalanobis distance, PCA-MD)剔除异常样品, 得到120个样本作为实验样本。
为了综合考虑样本的光谱空间和浓度空间, 采用Rank-KS(RKS)[13]算法从120个实验样本中挑选出具有代表性的100个样本组成校验集, 剩余20个样本作为预测集。 速效钾含量在校验集和预测集的统计结果如表1所示。
| 表1 建模集与预测集土壤样品的速效钾含量统计结果 Table 1 Statistics results of available potassium (K) in the calibration and prediction sets |
由表1可以看出, 校验集和预测集的速效钾范围分别为20.993~172.986和56.993~130.948 mg· kg-1。 预测集速效钾浓度范围均在校验集内部, 同时验证了RKS样本选择方法的有效性。
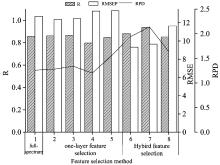
使用RFR作为回归模型, 表2比较了三类方法的建模性能。 其中, 第一类是原始光谱特征的建模效果; 第二类是使用单一特征选择算法进行特征选择后的建模结果, 该类算法包含四种算法: 蒙特卡洛-无信息变量消除算法(Monte Carlo-uninformative variables elimination, MC-UVE)[8], 竞争自适应重加权采样算法(competitive adaptive reweighted sampling, CARS)[5], 连续投影算法(successive projections algorithm, SPA)[14]和改进的随机森林特征选择算法(Improved-RF)。 第三类是使用本算法进行特征选择后的建模效果, 该类算法包含三种算法: MC-UVE-Improved-RF, CARS-Improved-RF和SPA-Improved-RF。 原始特征与两类特征选择算法所建模型的性能和精度分别以选出特征波段的数量、 建模时间、 相关系数(r)、 均方根误差(RMSE)和预测分析相对误差(RPD)为评价指标。 同时, 利用所建模型在测试集上进行预测, 图4对比了原始特征与两类特征选择算法的预测结果。
| 表2 原始特征与两类特征选择算法性能比较 Table 2 Comparison of performance between original features and two different feature selection methods |
由表2可知, 与原始特征和单一特征选择算法相比, 本算法选出的特征波长数量较少, 建模时间较短, 而模型精度明显较高。 对全波段光谱变量直接采用改进的随机森林特征选择算法(Improved-RF), 选出的特征波长数量较多, 建模时间较长, 而建模精度较低。 其原因可能是, Improved-RF算法的计算复杂度较高, 且对多重共线性问题不敏感, 导致单独使用该算法无法完全去除原始特征中的冗余与不相关特征。
由图4可以看出, 本算法预测集r较高, RMSE较低, 其RPD均明显高于1.6, 而原始光谱特征和单一特征选择算法预测集的RPD均在1.4以下。 对比结果表明, 混合式特征选择算法选出的特征值最少, 建模时间最短, 而预测效果最好; 原始光谱特征模型的特征值最多, 建模时间最长, 预测效果最差; 单一特征选择算法预测效果介于二者之间。 这是因为: 原始光谱特征模型含有大量的冗余与噪声信息, 精确度会受制于噪声信息的影响。 单一特征选择模型只采用一种机器学习算法作为评价指标, 往往造成所选择的特征中存在冗余特征, 导致模型预测精度较低。 经过特征初选, 精选和迭代三个阶段, 混合特征选择模型能有效删除大量冗余信息, 减少计算成本, 突出不同样本的光谱差异, 准确的挑选关键特征进行建模。
由表2和图4可以看出, 混合特征选择算法的三种算法中, CARS-Improved-RF特征选择算法取得最佳预测效果, 所建模型的相关系数为0.936 9, 均方根误差为9.661 5, 预测分析相对误差为2.14。
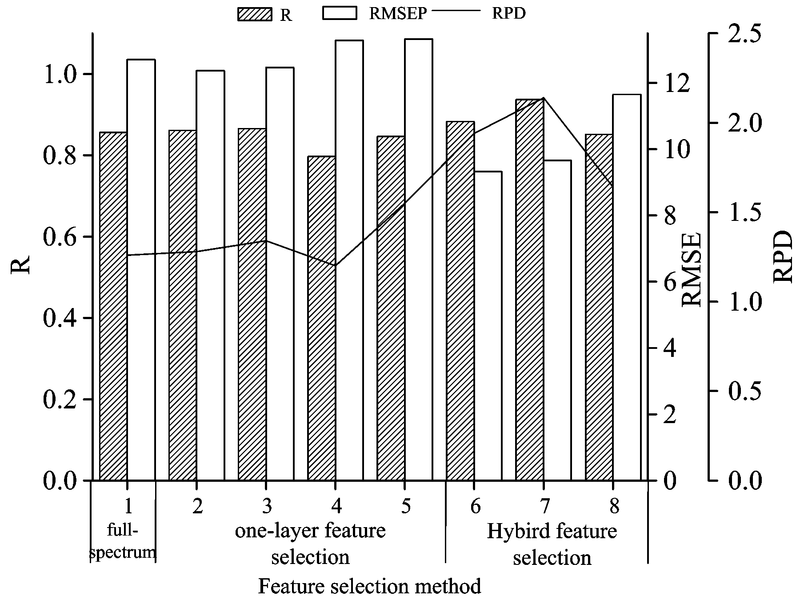 | 图4 原始特征与两类特征选择算法预测性能比较3.2 混合式特征选择算法最优光谱子集的选择与分析Fig.4 Comparison of performance between original features and two different feature selection methods |
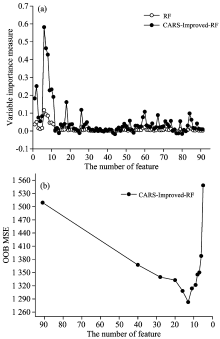
为了探究最优特征光谱子集的提取过程, 首先采用CARS算法进行波段预选, 然后再使用Improved-RF算法做特征精选和迭代。 以反演效果最优的CARS-Improved-RF算法为例, 通过结合改进的随机森林变量重要性度量方法以及迭代特征选择的过程, 图5展示了该算法特征提取的过程。
首先以CARS预选得到的120个样本91维光谱矩阵作为原始训练集, 然后根据算法2计算每个波长变量的最终重要性得分, 计算结果如图5(a)中CARS-Improved-RF算法所示。 为了验证CARS-Improved-RF算法在变量重要性排序方面的有效性, 在相同原始训练集上采用Bagging重采样方式随机生成十个不同的训练集, 利用随机森林本身的变量重要性度量方法分别计算每个训练集中所有变量的变量重要性得分, 对十次计算的结果取平均值作为随机森林(random forest, RF)中每个特征值的最终重要性得分。 图5(a)比较了RF和CARS-Improved-RF两种算法计算出的重要性得分之间的差异。 对于关键特征, CARS-Improved-RF算法的得分明显高于RF, 而两种算法对于冗余特征的重要性得分计算结果大致相同。 上述实验结果表明, CARS-Improved-RF算法能明显拉大关键特征与冗余特征的区分度, 使关键特征在迭代特征选择阶段更容易被选中。 CARS-Improved-RF算法在变量重要性排序方面具有明显优势, 原因主要是式(3)改进了随机森林本身的变量重要性度量算法, 在保持冗余特征变量重要性得分不变的基础上, 提高了关键特征的重要性得分, 使其与冗余特征的区分度更加明显, 为迭代特征选择阶段提供了准确的特征值变量重要性评分。
根据图5 (a)中CARS-Improved-RF算法得到的最终变量重要性评分, 对所有特征值从大到小排序, 选出累积贡献率达到90%的特征波段作为初始特征子集进行迭代特征选择。 该算法进行迭代特征选择的全过程如图5(b)所示。 由图5(b)可以看出, 袋外数据集的均方误差OOBMSE整体变化趋势呈现先降低再升高的变化过程。 当迭代到13个特征值时, OOBMSE达到最低值, 发生该变化的主要原因是由于样品光谱中的大量噪声和冗余特征的消除提高了反演精度。 当特征数量小于13时, OOBMSE开始上升, 可能是由于错误的剔除了与土壤速效钾含量有关的关键特征变量, 导致误差增大, 模型反演效果变差。 因此, 经过十二次迭代特征选择过程, 确定了由13个特征组成的特征子集为CARS-Improved-RF算法特征选择的最终结果。 可见, 把迭代选择变量的思想引入随机森林变量选择中, 不需要人为设定剔除变量的比例, 通过迭代特征选择使得自变量的选择更加准确, 达到最大限度地提高模型反演精度的目的。
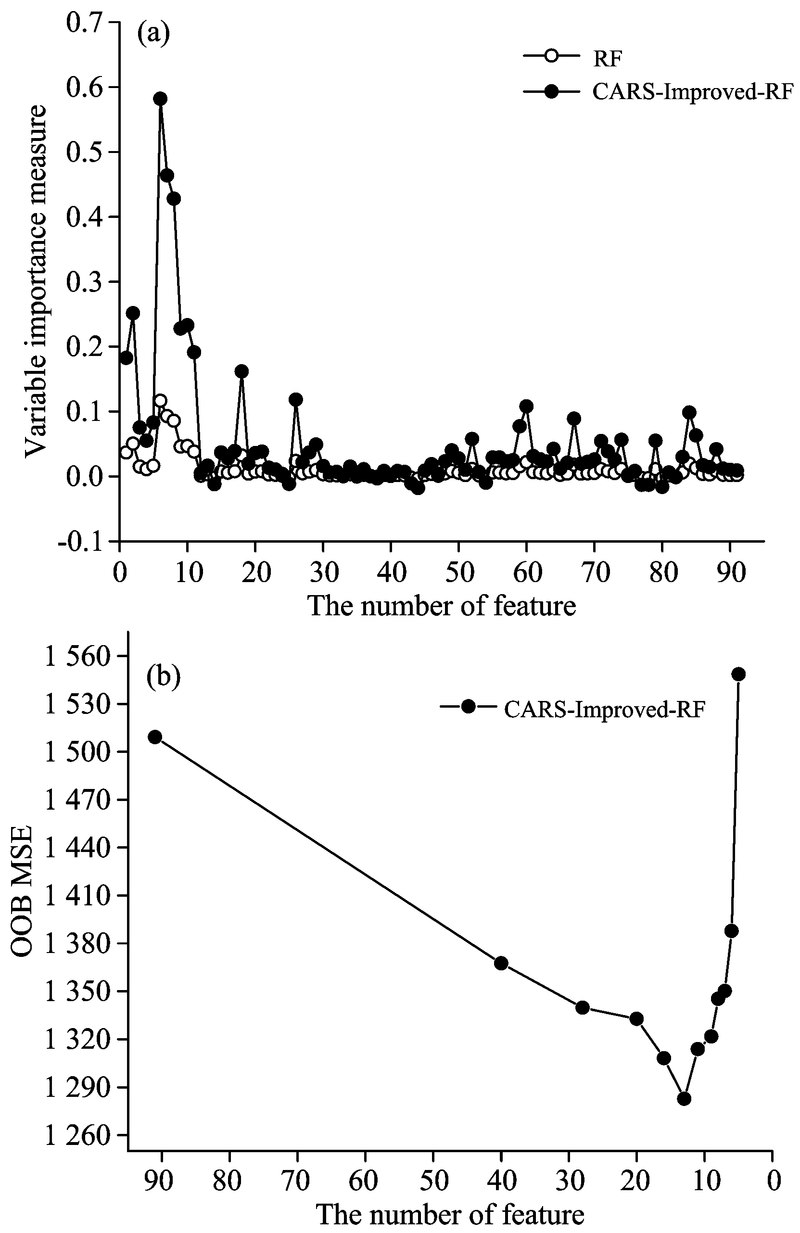 | 图5 CARS-Improved-RF算法特征提取过程 (a): 变量重要性排序改进的结果; (b); 迭代特征选择的结果Fig.5 CARS-Improved-RF algorithm for features extraction process (a): Result of VIM improvement; (b): Result of recursive feature selection |
回归模型的选择对于建模质量和效率有很大影响。 文献[15]研究表明, 随机森林的特征选择方法与随机森林回归相结合, 所建模型的预测性能均优于其他回归模型。
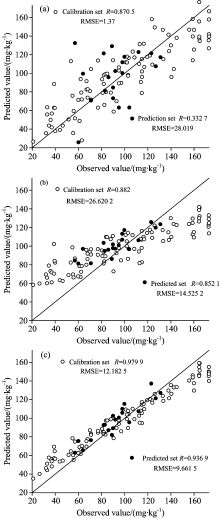
在CARS-Improved-RF混合式特征选择算法的基础上, 同时选取RFR, PLSR和Bagging[16]作为回归模型。 三个模型校验集和预测集样本的反演值和实测值之间的关系如图6所示。
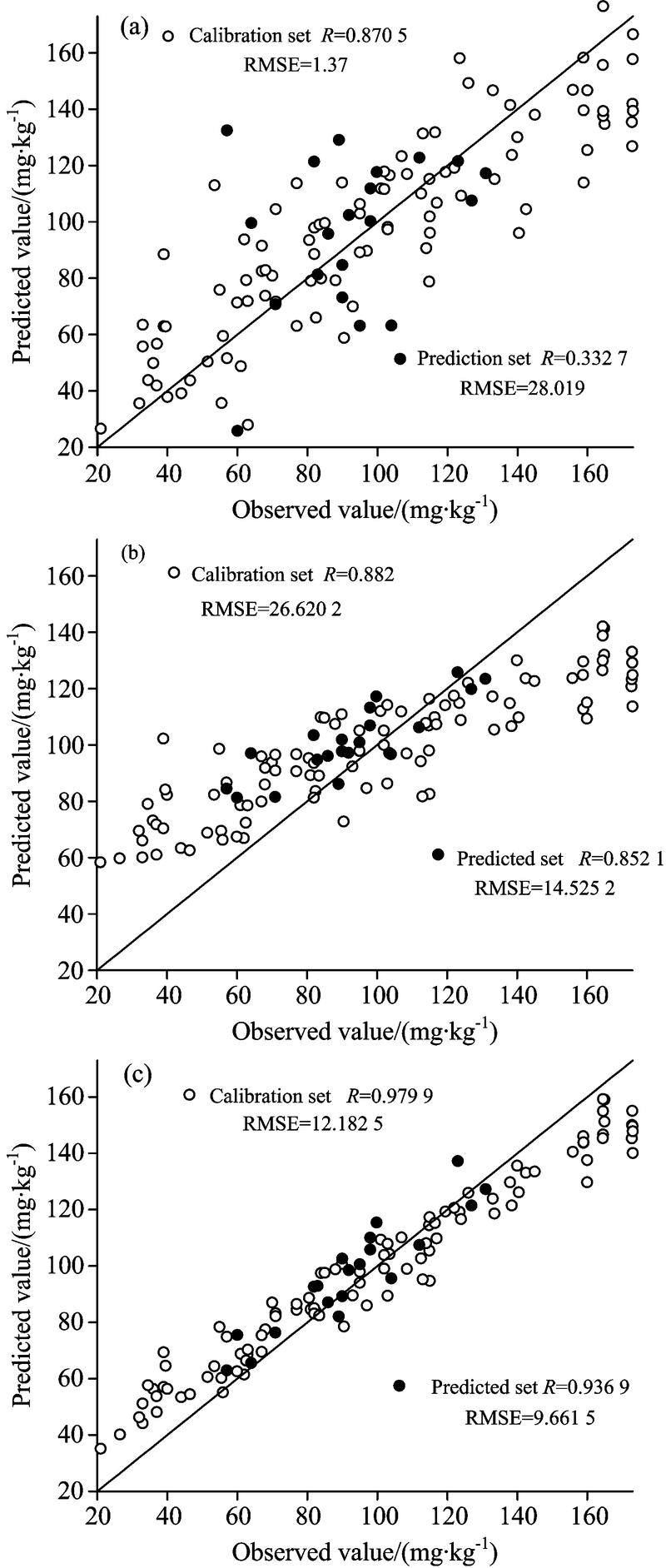 | 图6 三个不同模型的校正与预测结果 (a): CARS-Improved-RF-PLSR; (b): CARS-Improved-RF-Bagging; (c): CARS-Improved-RF-RFRFig.6 Calibration and prediction results of three different models (a): CARS-Improved-RF-PLSR; (b): CARS-Improved-RF-Bagging; (c): CARS-Improved-RF-RFR |
分析图6发现, 与PLSR和Bagging相比, RFR无论是建模精度还是预测精度都有显著的提高, r和RMSE分别达到0.936 9和9.661 5。 这是因为: 首先, 相比于PLSR, RFR生成决策树样本和选取最优特征值都是随机的, 有效的避免了PLSR易出现的过拟合现象。 此外, PLSR对于参数的敏感度较高, 而RFR对于其两个参数是不敏感的, 即使设为缺省值, 也能得到较好的预测结果。 其次, RFR是在Bagging回归的基础上选择最佳属性建立决策树, 最大限度的降低了树之间的相关性, 因此RFR具有较高的预测精度和较强的泛化能力。
可见, 与PLSR和Bagging回归相比, RFR更适用于土壤速效钾高光谱反演领域。
针对从土壤速效钾光谱中挖掘关键特征较为困难导致高光谱反演模型预测精度较低的问题, 提出了一种基于随机森林的混合式特征选择算法。 首先采用Wrapper型特征选择算法进行特征预选, 剔除冗余特征和大量噪声数据, 然后利用改进的随机森林特征选择算法对预选后的特征进行精选和迭代, 在此阶段通过加大关键特征与冗余特征的区分度以及采用迭代特征选择的方式来提高获取关键特征的准确性, 解决目前土壤样本速效钾含量反演精度较低的问题。 该算法用于大沽河流域土壤样品真实数据集上的主要结论如下:
(1)提出的混合式特征选择算法将原始光谱的2 051波段优选至13个敏感波段, 在显著降低模型复杂性的基础上达到了提高预测效果的目的。
(2)分别对最优光谱子集建立三种不同的回归反演模型, 实验结果表明, RFR更适用于土壤速效钾高光谱反演领域。
(3)通过与单一特征选择算法及原始光谱特征模型相比较, 可以得出, 基于随机森林的混合式特征选择算法预测效果最好, 可以准确剔除冗余和噪声信息, 缩短校正集建模时间, 明显提高反演精度。
因此, 基于随机森林的混合式特征选择算法与随机森林回归算法的结合在土壤速效钾高光谱反演问题中具有明显优势, 可为在线土壤养分传感器研发提供一定理论依据。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|