

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外光谱的不同牌号聚乳酸识别方法
[朱世超 , 游剑, 晋刚
, 游剑, 晋刚* , 雷玉, 郭雪媚]
, 游剑, 晋刚, 雷玉, 郭雪媚]
|
|


作者简介: 朱世超, 1995年生, 华南理工大学硕士研究生 e-mail: zhushichao1995@163.com
塑料牌号是塑料生产公司根据原料性质、 用途的差异而内部制定的编号。 通过检测材料的物理化学性能能间接识别其牌号, 但速度慢且具有破坏性。 因此, 利用了近红外光谱(near infrared spectroscopy, NIR)技术对不同牌号的聚乳酸(polylactic acid), PLA)进行识别。 采用主成分分析法(principle component analysis, PCA)分别与马氏距离(mahalanobis distance, MD)、 人工神经网络(artificial neural network, ANN)和支持向量机(support vector machine, SVM)结合的模型进行分析预测。 在900~1 700 nm的波长范围, 采用三种不同牌号的聚乳酸共90个样本的光谱进行建模, 另取这3种牌号共90个样本进行识别, 比较三种预测模型对PLA牌号的识别能力。 结果表明, 在对样品的光谱数据做主成分分析后, 以验证集的前两个主成分做散点图, 发现明显的聚类现象, 以前9个主成分得分作为输入变量所建立的马氏距离判别、 人工神经网络判别、 支持向量机判别均能够对不同牌号的聚乳酸有效识别。 最好的判别方法——马氏距离判别正确率能够达到98.9%。 因此, 近红外光谱能够对不同牌号的PLA进行无损、 快速、 准确的识别。
The type of plastics is the serial number that manufacturing companies formulated based on thenature and application of raw materials. Detecting the physical and chemical properties of plasticscan indirectly identify their types, but these test methods are time-consuming and destructive. In this work, near-infrared spectroscopy technology was used to identify different types of Poly(lactic acid)(PLA). In addition, three models, PCA-MD, PCA-ANN and PCA-SVM, were applied for the analysis and prediction of the sample. In the wavelength range of 900~1 700 nm, a total of 90 samples of three different types of PLA were used to establish the model and another 90 samples of these three types of PLA were taken for prediction and identification. Comparing the identification ability of three prediction models to PLA types, we can find that the scatter plot of the first two principal components scores of the validation set had an obvious clustering phenomenon after the PCA of the spectral data. The first nine principal component scores were taken as the input variables of Mahalanobis distance, ANN and SVM discriminants, and these discriminants effectively identified the type of PLA, among which the accuracy of the best discriminant——Mahalanobis distance can reach 98.9%. Therefore, near infrared spectroscopy can be used for nondestructive, fast and accurate identification of different types of PLA.
近红外光谱识别快速、 简单、 对样品无损[1], 广泛应用于木材[2], 中药[3], 食品[4]等领域。 近红外光谱谱带多为重叠的宽谱带, 几乎没有“ 指纹性” [5], 不能根据峰的归属进行定性分析, 也不能简单地根据面积的大小进行定量分析, 含有的信息隐藏在重叠峰之中, 需结合化学计量学方法提取光谱信息。 裘正军等基于近红外光谱利用主成分分析、 BP神经网络实现了对可乐品牌的有效识别, 识别准确率达100%。 Li等[7]基于近红外光谱利用模式识别实现了对柚子品种的有效识别。 其中反向传播神经网络(back propagation neural network, BPNN)与最小二乘支持向量机(least squares support vector machine, LS-SVM)均达到97%~92%的识别率。 目前, 近红外光谱识别技术在高分子材料领域的应用主要为塑料种类的识别。 李晓英等[7]基于红外光谱利用相关法对5种塑料进行了识别, 94个样本的预测准确率达94.6%; 郭慧玲等[8]基于近红外光谱利用多种聚类分析方法对四种塑料进行快速识别, 正确率最高的k-means聚类法对89个未知样本的预测结果准确率达92.1%。 与识别塑料种类相比, 塑料牌号差异带来的光谱差异无疑更小, 因此, 对塑料牌号识别的难度更大, 目前与此相关的研究还很少。
聚乳酸(PLA)是由乳酸为主要原料得到的聚合物, 生产过程无污染, 具有可生物降解的特性, 是理想的绿色高分子材料。 PLA适用的工业场合因牌号而有所不同。 不同牌号的PLA外形相近, 极易混淆, 而塑料牌号的差异反映在塑料加工工艺的不同导致的熔融指数差异, 如注塑成型工艺下, PLA的熔指为10~30 g/10 min。 而在挤出纺丝加工下, PLA的熔指为4~8 g/10 min[9]。 一般需要通过测PLA的熔指、 分子量等来对不同牌号的PLA进行识别, 检测速度慢且会对样品造成损伤。 因此, 寻求一种能够无损、 快速、 准确的识别方法来实现对PLA牌号有效识别是有必要的。
将光谱分析与化学计量学结合, 获取PLA的近红外光谱信息, 利用主成分分析对塑料样品的有效光谱信息进行提取并通过Matlab软件建立马氏距离、 人工神经网络、 支持向量机判别方法, 并验证了各判别方法的识别效果, 实现对不同牌号PLA的有效识别, 提供一种在生产中能够快速有效的检测PLA牌号的识别手段。
实验采用三种不同牌号的PLA粒料(PLA-2003D, PLA-6202D, PLA-6361D, NatureWorks), 熔指分别为5~7, 15~30, 70~85 g/10 min。 采用105Ge-110型全电动注塑机(东华机械公司)在同种工艺参数下注塑出直径为100 mm, 厚度为3 mm的圆形样本。
采用NIRQUEST系列中的512型近红外光谱仪(Ocean Optics Inc., USA), 分辨率为3.1 nm。 光源: 100 W高功率卤钨灯, 检测器: G9204-512 InGaAs线性阵列检测器, 探头: QR400-7-VIS-NIR型漫反射式探头, 软件: 科斯凯光谱采集软件(广州标旗)。
光谱采集范围900~1 700 nm, 积分时间100 ms, 平均次数20次。 每种塑料样本均为60个, 一共180个样本, 90个样本作为校正集, 90个样本作为验证集, 每个圆形样板采集一条光谱, 共180条。
利用Matlab 2016a版软件对样品的原始光谱进行处理算法的编写, 其中光谱预处理方法按顺序进行7点移动平滑、 一阶求导、 最大值归一化。 利用主成分分析对预处理后的全波段的光谱数据进行数据降维, 在降维数据的基础上用马氏距离、 人工神经网络、 支持向量机判别对不同牌号的PLA进行分类识别。
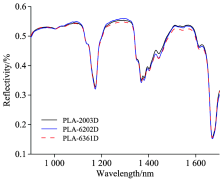
三个不同牌号塑料的原始近红外光谱图如图1所示, 由该图可见三种牌号的PLA反射率无明显差异, 但在一些峰的高度、 宽度上存在细微差异, 很难通过肉眼对谱图进行分类, 需要结合预处理与化学计量学的方法进行进一步分析。
 | 图1 三种不同牌号PLA的原始近红外光谱图Fig.1 Raw NIR spectra of three different types of PLA |
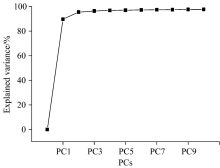
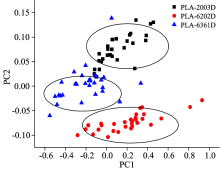
使用Matlab软件对预处理后的校正集和验证集进行主成分分析, 使得512× 180的原始光谱矩阵降维至179× 180, 得到的前10个主成分的累计贡献率如图2所示, 经计算, 前9个主成分的累计可信度为97.62%, 因此前9个主成分可以充分代表原始的光谱数据。 将前9个主成分作为后面马氏距离、 人工神经网络、 支持向量机判别的输入变量。 前2个主成分的叠加可信度为95.47%, 可以将验证集的前2个主成分做二维散点图, 定性观察验证集数据的聚类情况, 如图3所示, 可见, 除个别界外样本外, 三个牌号的PLA能够很好的各自聚为一类。 但是该二维散点图只能呈现出不同牌号PLA的聚类趋势, 不能把不同牌号的PLA样品全部识别区分, 所以需要建立更精确的模型对PLA的牌号进行识别。
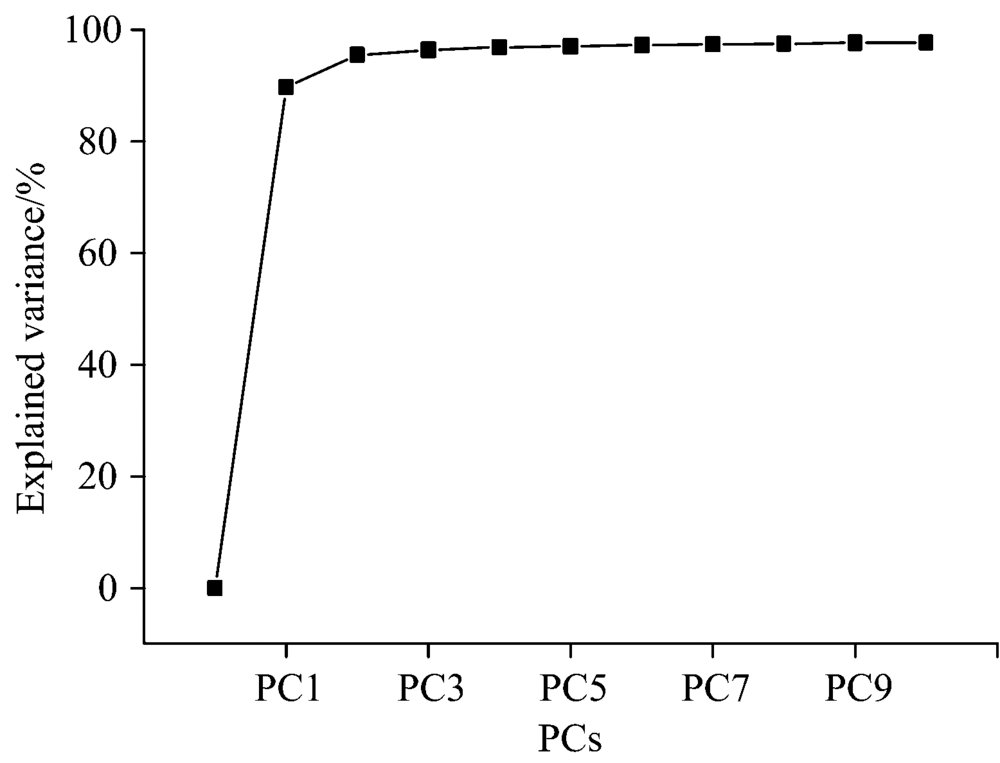 | 图2 校正集与验证集样本光谱主成分分析 主成分累计解释变量图Fig.2 Explained variance of the PCA model based on NIR spectra of calibration and validation set |
 | 图3 验证集光谱前2主成分得分图Fig.3 Plot of first two principal components scores for validation set |
将每个牌号PLA的30个校正集的主成分得分求平均, 记为该牌号PLA的中心, 求每个验证集到各牌号PLA中心的马氏距离, 验证集距离哪个中心近, 则判定验证集属于该牌号的PLA。 因验证集较多, 无法列出每个验证集距离各中心的马氏距离, 所以计算验证集到各中心的平均马氏距离, 大致观察判别情况, 如图4所示, 可见验证集距离对应中心的平均马氏距离较其他牌号更小, 能够达到识别效果。 统计验证集的识别结果如表1, 可以看出除了2003D这个牌号的PLA出现了一例误判, 其他两个牌号均全部预测正确, 识别正确率能够达到98.9%。
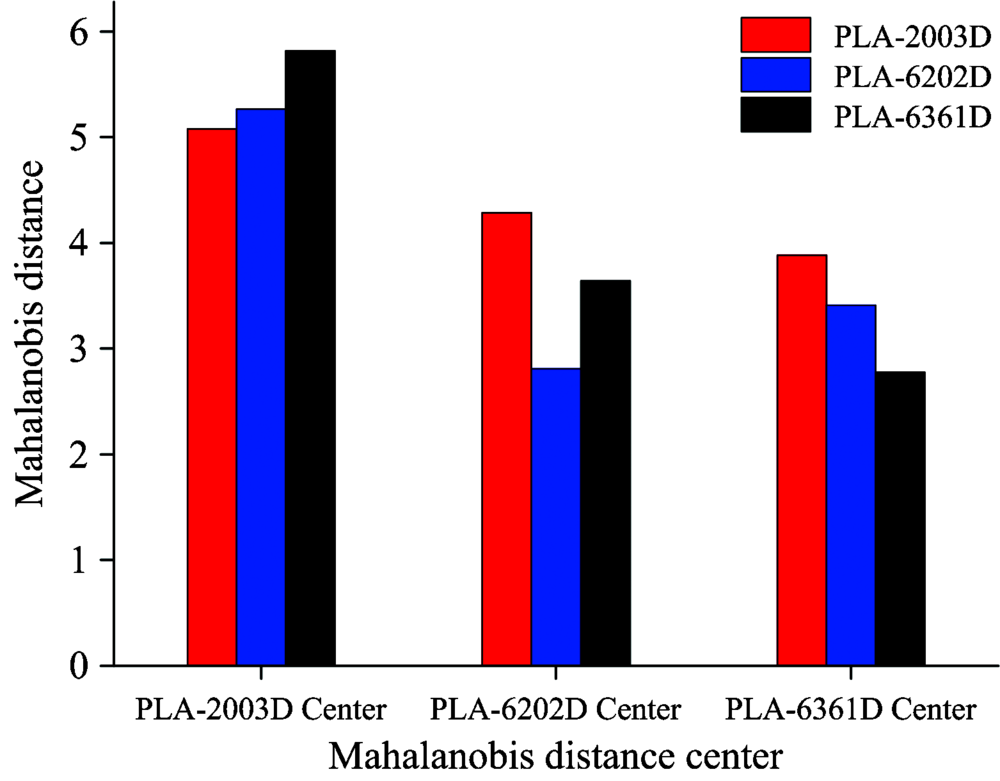 | 图4 验证集到各中心的平均马氏距离Fig.4 Average Mahalanobis Distance of validation set to each center |
| 表1 基于马氏距离判别的不同牌号PLA识别结果 Table 1 Identification results of different types of PLA based on the Mahalanobis Distance discriminant |
利用人工神经网络, 将校正集的前九个主成分得分作为输入, 100, 010和001分别代表2003D, 6202D和6361D的输出对网络进行训练, 90组校正集数据中, 70%用来构建网络, 15%用来验证网络, 15%用来测试网络。 此处采用的神经网络类型为反向传播人工神经网络(back propagation-artificial neural networks, BP-ANN), 隐藏神经元节点数决定了神经网络的结构, 且对判别正确率有较大影响。 为获得最佳的识别效果, 改变隐藏神经元节点数, 根据验证集的均方根误差与识别正确率找出最优预测效果的神经网络, 如图5所示。 由均方误差与正确率的数值可以发现设置隐藏神经元节点为9个时, 识别正确率最高, 均方误差最低, 网络分类能力最佳, 正确率达到了96.7%, 细分到牌号的验证集的识别结果如表2。
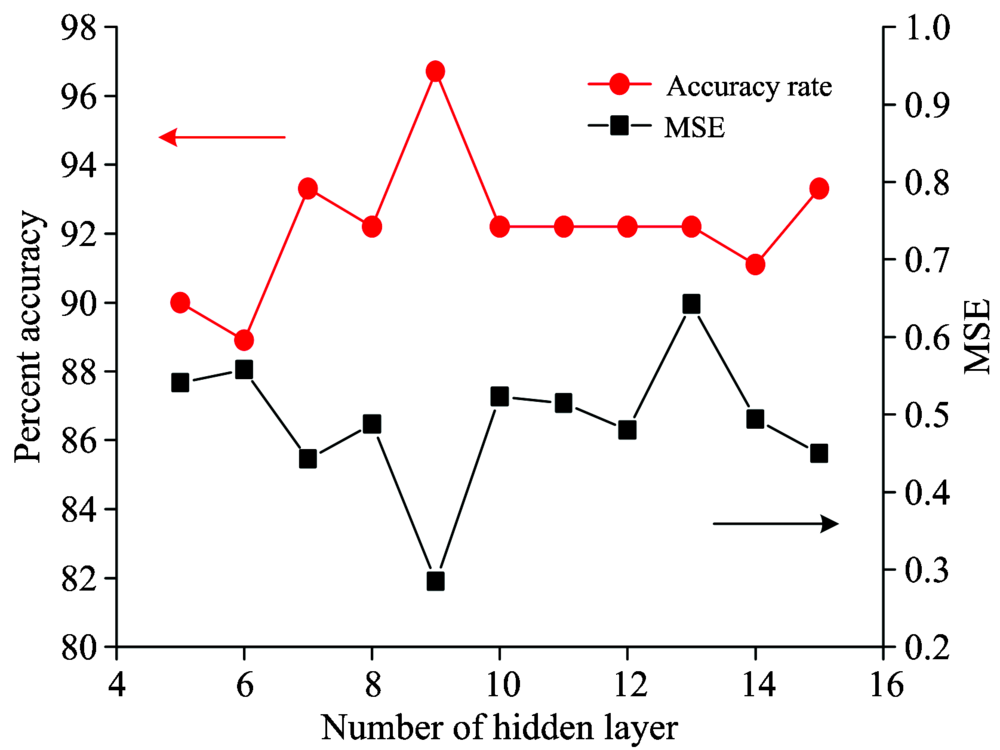 | 图5 不同隐藏节点数对应的验证集的 正确率及均方误差Fig.5 Percent accuracy and mean squared error of validation set with different nodes in hidden layer |
| 表2 基于人工神经网络判定的不同牌号PLA识别结果 Table 2 Identification results of different types of PLA based on the artificial neutral network discriminant |
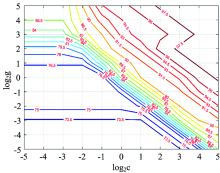
支持向量机是由AT& T Bell实验室的Vapnik等[10]提出的用于回归和分类的机器学习新方法。 对比于神经网络, 支持向量机能够很好的预防欠学习与过学习的发生。 将校正集的前9个主成分作为输入, 以1, 2和3分别代表2003D, 6202D和6361D的输出, 以径向基函数(radial basis function, RBF)为核函数(将数据映射到高维的函数), 构建支持向量机模型。 提高SVM分类正确率的核心问题为惩罚因子(cost, c)和核函数参数(gamma, g)的选择, 通过设置交叉验证和网格搜索[11], 将校正集分为三部分进行交叉验证, 惩罚因子与核函数参数步进大小为1, 在2-5~25的参数范围内, 不同惩罚因子与核函数参数组合下得到的交叉验证正确率如图6所示, 其中正确率的步进大小为1.5%。 得到最优的惩罚因子参数c=32, 核函数参数g=2。
 | 图6 不同惩罚因子与核函数参数组合下的交叉验证正确率Fig.6 The cross validation accuracy under different combinations of cost and gamma |
为了方便使用, 采用台湾大学林智仁教授开发的Libsvm[12], Libsvm是支持向量机的开源软件包, 现已被业界广为用来解决分类问题、 回归问题和分布估计等[13]。 以惩罚因子参数c=32, 核函数参数g=2建立支持向量机模型对验证集进行识别, 结果如表3所示, 识别正确率能够达到97.8%。
| 表3 基于支持向量机判定的不同牌号PLA识别结果 Table 3 Identification results of different types of PLA based on the support vector machine discriminant |
应用近红外光谱针对三种不同牌号的PLA进行了识别, 首先利用Matlab软件使用PCA对原始的512× 180光谱矩阵降维至179× 180, 前9个主成分得分足够代替原始的高维数据, 利用前两个主成分做二维散点图可发现不同牌号的PLA具有明显的各自聚类。 随后将前9个主成分作为输入变量, 分别进行了马氏距离判别、 人工神经网络判别、 支持向量机判别。 结果显示: 马氏距离判别存在一例PLA-2003D的误判, 正确率能够达到98.9%。 改变隐藏神经元节点数建立不同复杂程度的神经网络, 当隐藏神经元节点数为9个时, 人工神经网络判别正确率最高, 存在一例PLA-6202D和两例PLA-6361D的误判, 正确率能够达到96.7%, 通过网格搜索与交叉验证的方法, 发现惩罚因子参数c=32, 核函数参数g=2时, 支持向量机判别正确率最高, 存在两例PLA-6361D的误判, 正确率能够达到97.8%。 可见, 所使用的三个判定手段正确率均较高, 实现了三种不同牌号PLA的有效识别。 因此认为, 近红外光谱可作为一种有效的手段对不同牌号PLA进行识别, 为进一步研究PLA掺杂废料、 老料的鉴别提供了参考。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|