


{kind=link}
{kind=link}
{kind=link}
{kind=link}
卷积神经网络用于近红外光谱预测土壤含水率
[王璨1  , 武新慧
, 武新慧1 , 李恋卿2 , 王玉顺1 , 李志伟1, * ]
, 武新慧]
|
|


作者简介: 王 璨, 1991年生, 山西农业大学博士研究生 e-mail: wangcan8206@163.com
近红外光谱分析技术在土壤含水率预测方面具有独特的优势, 是一种便捷且有效的方法。 卷积神经网络作为高性能的深度学习模型, 能够从复杂光谱数据中自主提取有效特征结构进行学习, 与传统的浅层学习模型相比具有更强的模型表达能力。 将卷积神经网络用于近红外光谱预测土壤含水率, 并提出了有效的卷积神经网络光谱回归建模方法, 简化了光谱数据的预处理要求, 且具有更高的光谱预测精度。 首先对不同含水率下土壤样品的光谱反射率数据进行简单的预处理, 通过主成分分析减少光谱数据量, 并将处理后的光谱数据变换为二维光谱信息矩阵, 以适应卷积神经网络特殊的学习结构。 然后基于卷积神经网络算法, 设置双层卷积和池化结构逐层提取光谱数据的内部特征信息, 并采用局部连接和权值共享减少网络参数、 提高泛化性能。 通过试验优化网络结构和各项参数, 最终获得针对土壤光谱数据的卷积神经网络土壤含水率预测模型, 并与传统的BP, PLSR和LSSVM模型进行对比实验。 结果表明在训练样本达到一定数量时, 卷积神经网络的预测精度和回归拟合度均高于三种传统模型。 在少量训练样本参与建模的情况下, 模型预测表现高于BP神经网络, 但略低于PLSR和LSSVM模型。 随着参与训练样本量的增加, 卷积神经网络的预测精度和回归拟合度也随之稳定提升, 达到并显著优于传统模型水平。 因此, 卷积神经网络能够利用近红外光谱数据对土壤含水率做出有效预测, 且在较多样本参与建模时取得更好效果。
The technology of near infrared spectroscopy that has unique advantage in the prediction of soil moisture content is a convenient and effective method. Convolutional neural network (CNN) is a deep learning model with high performance. Using CNN, effective features data can be extracted from complex spectral data and the inner structure of feature data can be learned. Compared with traditional surface learning models, convolutional neural network has more powerful modeling capability. In this research, the CNN was used to predict the soil moisture content by near infrared spectroscopy. An efficient modeling method of CNN for spectral regression was proposed. The pretreatment process of spectral data was simplified and the accuracy of spectral prediction was improved by this modeling method. In this paper, firstly, the simple pretreatment was used to treat the spectral reflectance data of soil samples under different moisture contents. Principal component analysis was used to reduce the amount of spectral data and the correlation of the features. The processed spectral data was transformed into 2-dimensional spectral information matrixes to meet the special learning structure of CNN. Secondly, the convolutional neural network was used to build the regression model for the prediction of soil moisture content. The first four stages of this CNN model were composed of two types of layers: convolutional layers and pooling layers. Inner features of the input spectral data were obtained by composing convolutional layers and pooling layers, each transforms the representation at one level into a representation at a higher, slightly more abstract level. With the composition of enough such transformations, very effective inner features of spectral data can be extracted. There were two key ideas behind the CNN model that can reduce the number of parameters of the network: local connections and shared weights. In addition, these ideas can also improve the generalization performance of the CNN model. The model structure and parameters were optimized by carrying out experiments. Finally, the CNN model with improved regression structure of soil spectral data was built for the prediction of soil moisture content. The CNN model was compared with the BP, PLSR and LSSVM models, and these three traditional models were commonly used in the prediction of soil moisture content. The results showed that when the number of training samples reached to some degree, the prediction accuracy and regression fitting degree of the CNN model were higher than those of the traditional models. The performance of the CNN model were much higher than the BP neural network which had the same network training method with the CNN model, but slightly lower than the PLSR and LSSVM models when a small number of training samples were used in the modeling. The prediction accuracy of the CNN model greatly increased with the number of training samples growing. So did the regression fitting degree of the CNN model. In the end, the performance of the CNN model was significantly better than the traditional models. Therefore, the CNN method could be used to effectively predict the soil moisture content by the near infrared spectral data, and better results are obtained when more training samples are involved in modeling.
土壤含水率是土壤理化特性中的一项重要指标。 水分作为土壤中作物吸收的主要物质, 与作物的长势和发育状况紧密联系, 是精准农业灌溉所要考虑的主要因素[1]。 因此, 土壤水分的监测一直是农业领域所关注的问题。 土壤水分对光谱具有很强的吸收特性, 对土壤光谱反射特征有显著影响[2]。 近红外光谱分析技术在土壤含水率预测方面有独特的优势, 是一种便捷且有效的方法, 有着广泛的研究和应用基础[3, 4]。 早期研究发现土壤反射光谱存在由水分所引起的吸收带, 提出可由这些波段的反射率值计算土壤含水率, 随后的研究给出了不同的光谱数据建模方法, 主要有线性回归、 反向传播神经网络(backpropagation network, BP)、 偏最小二乘回归(partial least squares regression, PLSR)和最小二乘支持向量机(least squares support vector machine, LSSVM)[5, 6, 7, 8, 9, 10, 11, 12]。 其中BP, PLSR和LSSVM等模型的预测精度普遍高于线性回归方法, 是目前常用的光谱数据建模方法。 通过前人的研究可以发现, 当前近红外光谱预测土壤含水率普遍采用的方法是寻找特征波段, 进而通过上述方法建立预测模型。 研究多集中在光谱数据预处理和有效特征波段的筛选方法上, 少见有相关光谱回归模型的提出与改进。 而高性能的光谱数据建模方法, 能够简化光谱数据的预处理要求, 同时也是保证光谱预测精度的关键。
卷积神经网络(convolutional neural network, CNN)由Yann LeCun提出, Krizhevsky等[13]对其进行改进, 在机器学习领域取得了重要的突破。 CNN是一种高性能的深度学习方法, 该构架的提出首先是为了最小化多维数据的预处理要求[14]。 CNN通过多层卷积和池化操作可以自主学习并提取数据每个局部特征, 获取相对于显式特征提取方法更加有效的抽象特征映射。 CNN目前在图像识别领域表现最为突出[15], 其他相关基础较少, 但已有研究表明, 利用CNN结构对数据进行实值回归也能取得较好效果。
由于CNN模型具有从复杂数据中选择并提取有效特征的优点和良好的模型表达能力, 因此研究针对不同含水率下黄棕壤的光谱反射率数据集, 通过CNN模型自主提取特征数据并预测土壤含水率值。 首先通过常用光谱预处理及主成分分析降低光谱数据量, 然后将样本光谱数据转换成二维光谱信息矩阵, 利用CNN结构建立土壤含水率预测模型。 并与传统的BP, PLSR以及LSSVM算法进行对比, 结果表明卷积神经网络能够取得较好效果, 当训练样本超过一定数量时, 表现优于当前常用模型。 这是一种光谱数据建模新方法, 可为相关研究提供基础和借鉴。
在对数据建模的过程中, 为了加快CNN的训练速度, 需要减少单一样本的数据量。 经过试验表明, 虽然采用原始光谱数据参与建模能取得最佳效果, 但网络收敛速度较慢, 需要更长的训练时间。 在保证模型性能的前提下, 利用主成分分析(principal component analysis, PCA)方法可以大幅度减少数据量, 使模型在高效训练的同时达到所期望的预测能力。 PCA通过一系列线性变换将原始数据转换为一组各维度线性无关的表示。 PCA算法原理和实现步骤已有许多相关研究, 此处不再做详细说明。
由于CNN特殊的深度学习结构, 需对输入网络的光谱数据进行一些简单的处理。 采用构建光谱信息矩阵的方法, 将每个样本的光谱数据向量转换为二维光谱信息矩阵, 以适应卷积层的相关操作要求, 充分发挥模型表达能力。 具体处理方法如下:
设x为某一样本的光谱数据向量, 且为列向量形式, 则该样本的二维光谱信息矩阵为
假设x是三维光谱数据列向量, 则一个典型的二维光谱信息矩阵为
在统计学中, 该方阵是原光谱数据的信息矩阵, 其特性是包含数据的所有原始信息, 且能够体现数据方差和协方差的相对大小。 构建二维光谱信息矩阵能够保持原光谱数据特征和空间关联性, 同时符合CNN结构的输入要求。 在光谱分析方面, 二维光谱信息矩阵类似于二维同步相关光谱等高图, 其特性是能够从一定程度反映光谱数据的波动情况。 更有利于CNN学习光谱数据的内部结构, 取得更好的模型表达效果。
CNN通过逐层特征提取学习多维阵列数据内部的本质联系, 采用四个关键设计来利用自然信号的属性: 局部连接、 权值共享、 池化和多层网络的使用。 作为一种非线性算法, CNN与BP神经网络具有相同的训练方式, 主要区别在于CNN具有卷积和池化等特殊结构对输入数据的内部特征进行提取学习。 此外, CNN通过局部连接和权值共享有效减少了网络的训练权值和误差衰减, 使多层神经网络的优势得以体现, 在网络层数上多于BP神经网络。
典型的CNN结构如图1所示。 除输入外的最初两个阶段由卷积层和池化层组成, 然后与传统的多层感知器全连接, 最后获得输出。
 | 图1 典型卷积神经网络结构Fig.1 The architecture of a typical CNN |
卷积层中的单元被组织在特征图中, 且每个单元通过一组被称为滤波器的权值与上一层的局部相连接, 然后这个局部加权和通过一个非线性函数进行激活。 所以卷积层的第k个特征图由式(3)定义
式(3)中,
池化层的作用是对卷积层提取的局部特征进行下采样, 减少网络自由参数并提高特征数据的鲁棒性, 一般采用均值池化或最大池化方法。 池化层由式(4)定义
式(4)中:
最后将池化层输出的特征图进行光栅化处理, 并与多层感知器(multilayer perceptron, MLP)全连接。 通过求解网络损失函数极小化问题来估计网络参数, 利用反向传播算法使全部滤波器中的权值得到训练。
以江苏省句容市内采集的农田土壤样本为研究对象, 主要土壤类型为黄棕壤, 在我国中东部地区分布广泛, 具有较强代表性。 取样深度为土壤剖面0~20 cm范围, 采用十字交叉法在采样范围内取10份土样。 置土壤样品于室内自然风干, 剔除杂质, 经研磨后过2 mm孔径筛(10目), 放入105 ℃恒温干燥箱中48 h。 处理完备的土样放入玻璃容器中待用。
制备土壤从饱和到风干状态不同含水率梯度的样品并作光谱测定。 方法是从每份土壤样本中取出质量相同的3份土样, 分别置于大小相同的铝盒中(直径5 cm, 高1.6 cm), 称重后缓慢向其中注水, 使土壤样品中的水含量达到轻微过饱和状态。 观察并等待土壤表面的自由水完全消失, 将土壤表面刮平, 开始进行光谱数据的测定。 每隔1 h对土壤样品进行一次测定, 8 h后根据样本的含水率情况进行最后两次测定。 由此得到不同含水率下的土壤光谱反射率数据, 同时利用经典的烘干称重法计算土壤含水率。
光谱数据的测定使用美国ASD FieldSpec3地物光谱仪, 光谱范围350~2 500 nm, 采样间隔为1.377 nm(350~1 000 nm)和2 nm(1 000~2 500 nm)。 实验在室内进行, 采用5° 视场角探头, 距土壤样本表面25 cm。 主动光源为2个50 W标准卤素灯, 置于样本顶部对称的两侧, 天顶角为15° , 距土壤样本表面50 cm。 利用白板对光谱仪进行标准化, 提高测定精度。 对每个样品进行6次重复光谱测定, 取其平均值作为土壤样本的光谱反射率数据。
根据光谱曲线情况剔除11组无效数据, 最终获得289组有效样品数据, 含水率覆盖范围3.85%~31.72%, 样本统计属性如表1所示。
| 表1 土壤样本含水率统计 Table 1 The statistics of the soil moisture content |
利用ViewSpec软件对采集的样本光谱数据进行平滑和拼接校正, 并消除其他干扰。 经过简单的预处理后, 将数据导出。 通过MATLAB R2016b软件对导出的光谱数据进行PCA处理, 经过试验, 设置主成分数为20, 理论方差累计贡献率达100%。 有效减少了样本数据量, 对后期CNN建模具有积极意义。 将PCA后的光谱数据进行归一化处理, 并按上述方法变换为光谱信息矩阵, 最后每个样本的矩阵大小为20× 20。
基于caffe深度学习框架建立预测模型, 采用MATLAB接口进行编程。 利用已有样品数据进行反复试验, 对网络结构进行改进与调整, 以土壤样品光谱信息的最佳回归效果为引导, 最终确立土壤含水率的CNN预测模型结构, 具体结构如图2所示。
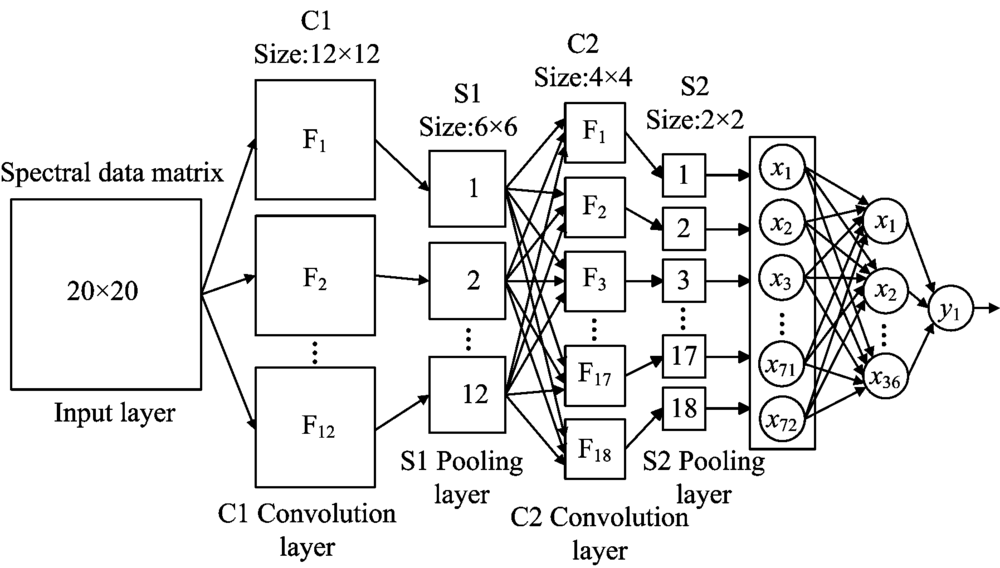 | 图2 卷积神经网络预测模型结构Fig.2 The architecture of CNN prediction model |
设置网络第1卷积层的卷积核大小为9× 9, 数量为12, 激活函数为RELU(rectified linear units, RELU); 第2卷积层的卷积核大小为3× 3, 数量为18, 每个输出特征图由不同的卷积核在前一层所有特征图上作卷积并将对应元素累加后加偏置, 再通过RELU函数激活得到; 池化层采用均值池化方法, 下采样尺度均为2× 2。 MLP隐层神经元个数设置为光栅化层的一半, 输出层为单神经元, 用于实值回归。 网络利用BP算法进行训练, 设置卷积核权值随机初始化, 偏置为全0初始化, 采用留一交叉验证法选取最佳参数。 损失函数定义为欧氏距离, 通过式(5)计算
其中yp是网络预测值, yt是实验测定值。 通过试验设定网络学习率为0.6, 最大迭代次数为1 000, 网络训练过程中的损失函数如图3所示。 可以看出, 网络随着迭代次数的增加逐渐收敛, 曲线在宏观上平滑下降, 说明学习状态良好, 无过拟合状态出现。
 | 图3 模型训练过程中的损失函数值Fig.3 The value of loss function in the process of model training |
选用目前研究中常用的BP, PLSR和LSSVM算法作为对比实验。 BP神经网络选用单隐层结构, PLSR模型设置为全因子回归, 采用留一交叉验证。 LSSVM模型的核函数设置为径向基函数, 利用留一交叉验证法确定最佳参数, 其中γ =24.826, σ 2=3.587。
将全部289个有效样本划分为训练集和测试集, 数据划分规则为所得训练集和测试集具有相似的统计特性。 其中训练集样本202个用于建立模型, 测试集样本87个用于检验模型预测性能, 训练集占全部样本量的比例为0.7, 交叉验证数据包含在训练集中。 进行5次重复训练与测试并取平均值, 所得结果如表2所示。 从模型的回归拟合度和预测精度两个方面考察模型性能, 采用的统计评价指标为: 建模均方根误差RMSEC、 决定系数
| 表2 不同模型下的土壤含水率预测结果 Table 2 The predicted results of soil moisture content under different model |
由表2可知, 对相同光谱数据的土壤含水率的回归预测, CNN模型所取得的效果优于BP, PLSR和LSSVM模型。 在建模样本的回归拟合度和精度方面: CNN模型的决定系数最大,
通过以上分析, CNN模型能够用于近红外光谱预测土壤含水率, 而且相比于BP, PLSR和LSSVM模型具有更高的回归拟合度和预测精度。 采用CNN建模方法能够在有效简化光谱数据预处理过程的同时达到更好的回归效果, 是一种高性能的土壤含水率预测模型。 研究表明CNN模型独特的深度学习结构可以提取并学习光谱数据的内部特征, 获取更加有效和细致的局部抽象特征映射, 利用这些数据特征进行土壤含水率的实值回归能取得更好的效果。 此外, CNN模型的网络组成方式能够降低不相关数据的干扰, 提高模型的鲁棒性和实际泛化能力, 具有更稳定的光谱预测效果。 传统的预测模型并不具备CNN的数据特征分析提取过程, 在训练前需要对光谱数据进行人工筛选和更多的预处理过程, 所以在模型性能上不如CNN, 但是表现也较为良好。 CNN模型的多层网络结构决定了其需要更多的样本来进行训练。 当训练样本较少时, 可能效果并不理想, 随着训练集样本量的增加, 模型预测能力也将得到进一步提升。
为了研究不同的训练集样本量对CNN建模效果的影响, 采用相同的规则对训练集和测试集重新划分, 进行建模实验并计算相关评价指标, 同时进行BP, PLSR和LSSVM模型的对比实验。 训练集样本占全部样本的比例为0.5~0.9, 只对测试集样本的回归拟合度和预测精度进行评价, 取5次重复试验的平均值-所得结果如表3所示。
| 表3 不同训练集样本量下各模型的预测结果 Table 3 The predicted results of training sets with different sample sizes |
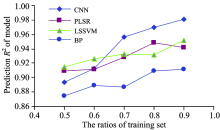
根据模型评价原则, 通过对比表3中数据可知, 当训练集比例为0.5时, CNN模型的回归拟合度和预测精度不如PLSR和LSSVM模型, 但优于BP神经网络, 其中LSSVM模型效果最好。 当训练集比例为0.6时, CNN模型与PLSR模型具有相似的预测能力, 但实际表现仍不如LSSVM模型。 随着训练集所占比例的增加, 各模型的性能均有所提升, 其中CNN模型的提升幅度最为明显。 当训练集所占比例大于等于0.7以后, CNN模型在所有模型中表现最佳, 各项指标均在一定程度上优于BP, PLSR和LSSVM模型。
同时对各模型的预测决定系数变化情况进行比较, 如图4所示。 CNN模型的预测决定系数随着训练样本的增加而持续增大, 在所有模型中增长幅度最大。 PLSR和LSSVM模型的增长幅度较小, 且出现停止增长的情况。 BP神经网络虽然也有增长, 但其预测决定系数始终低于其他模型。 总体来说, CNN模型能够从增长的样本光谱数据中获取更多的有利信息以快速提高模型性能。 说明CNN模型在有较多样本参与建模的情况下, 能够显著提高回归拟合度, 性能大幅优于传统模型。 在大数据环境下是一种更为有效的光谱回归建模方法, 能够基于光谱数据做出更加精确的预测。
 | 图4 各模型的预测决定系数Fig.4 The prediction R2 of each model |
将卷积神经网络用于近红外光谱预测土壤含水率, 提出了有效的CNN光谱数据回归建模方法, 并取得了较好效果。 首先对不同含水率下土壤的光谱反射率数据进行常用的预处理以及主成分分析处理, 减少光谱数据量。 将处理后的光谱数据变换为二维光谱信息矩阵, 以适应CNN模型特殊的深度学习结构, 并保持原数据的特征信息和空间关联性。 所建CNN回归模型利用卷积和池化操作逐层提取数据的抽象特征映射, 从而学习数据内部的结构特征及其本质联系。 通过局部连接和权值共享的网络结构减少自由参数, 提升模型泛化能力。 通过试验改进与调整网络参数, 得到高性能的CNN光谱回归预测模型。 利用该模型对土壤含水率进行预测, 并与BP, PLSR和LSSVM模型进行对比。 在训练样本达到一定数量时, 其预测精度和回归拟合度均高于传统模型, 且具有更强的泛化性能。 少量训练样本参与建模的情况下模型性能优于BP, 但略低于PLSR和LSSVM。 随着训练数据量的增加, CNN模型的预测能力稳步提升, 达到并显著优于传统模型水平。 因此, CNN模型对于大样本量的光谱数据进行回归建模能取得更好的效果, 在大数据环境下更具优势。 不足之处在于建模所需时间较长, 可通过并行运算等技术手段来弥补这一缺点, 能够大幅提升卷积神经网络的训练速度。 未来卷积神经网络在近红外光谱检测领域会有更加优秀的表现和更为广泛的应用。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|