{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于互信息的遗传算法在光谱谱段选择中应用
[孔清清 , 宫会丽
, 宫会丽* , 丁香乾, 刘明]
, 宫会丽, 丁香乾, 刘明]
|
|


作者简介: 孔清清, 1992年生, 中国海洋大学信息科学与工程学院硕士研究生 e-mail: kqqinging@163.com
在近红外光谱分析技术中, 建立一个准确、 稳健的定量模型至关重要。 全光谱建模会增加建模和预测时间, 降低模型的稳健性和预测精度, 因此有效的变量选择方法对于模型构建至关重要。 针对该问题, 提出了基于互信息的遗传算法(GAs-MI)对特征变量进行选择, 互信息筛选掉大量无关信息和冗余信息, 遗传算法进一步选择出高辨别力的特征; 并在遗传算法的变异过程中引入Shapley值方法, 减少了人为设定参数的随机性。 为了验证算法的有效性, 选取有代表性的273个烟叶样本为实验材料, 随机选择其中182个样本实现对烟叶总烟碱的PLS定量建模, 剩余样本作为测试集, 以相关系数( R)、 交互验证均方差(RMSECV)和预测均方根误差(RMSEP)为模型评价指标。 实验结果表明, 通过该方法选择的波长建立的模型更加简单、 预测能力更强。
It is vital to establish an accurate and robust quantitative model in near-infrared spectroscopy. The whole spectrum modeling can increase the computational time of modeling and forecasting, and reduce the robustness and precision. Therefore the effective variable selection method is very important for model construction. To address this problem, this paper proposed a genetic algorithm based on mutual information (GAs-MI) to select features. Mutual information filtered out a large number of unrelated information and redundant information. Genetic algorithm further selected the features with high discernment. Shapley value method was introduced to reduce the randomness of artificial setting parameters in the mutation process of genetic algorithm. In order to validate the validity of the algorithm, 273 representative tobacco samples were selected as the experimental materials. 182 samples were randomly selected to construct the PLS quantitative model of tobacco nicotine,and the remaining samples were used as the test set. The Correlation Coefficient (R), the Root Means Square Error of Cross Validation (RMSECV) and the Root Mean Square Error of Prediction (RMSEP) were used as the model evaluation indexes. The experimental results showed that the model established by the selected wavelength was simpler and more predictive.
近红外定量建模与预测分析是目前最为常用的快速高效分析技术, 已经广泛应用于食品、 烟草、 石油等行业[1, 2, 3]。 近红外光谱具有高维、 非线性等特点, 波长选择在近红外光谱定量建模分析技术中起着至关重要作用。 目前波长选择方法主要有相关系数法、 逐步回归法、 模拟退火算法、 间隔偏最小二乘法(iPLS)、 遗传算法(GA)等[4, 5, 6]。 而遗传算法是公认的具有较强鲁棒性的优化算法, 具有隐含并行性和全局搜索特性两大显著特点, 且遗传算法已经被广泛的应用于特征选择。 但若输入特征过多, 算法收敛难, 其在高维特征数据的应用是困难的。 面对遗传算法在高维特征数据下应用差的问题, 研究者大都采用将近红外光谱分成不同的区域, 然后利用遗传算法选择出相关区域进行建模。 如祝诗平等[7]利用遗传算法选择出近红外光谱谱区参与建模; 邹小波等[8]将近红外光谱分成不同的区域, 将选择的光谱区域中的波长变量进行PLS建模。 上述方法取得了一定的效果, 但光谱区域选择所选的特征变量含有冗余信息且可能导致部分相关性强的特征变量未被选择, 从而影响模型的准确性和适用性。
针对上述问题, 我们提出了基于互信息的遗传算法, 通过互信息筛选掉大量无关信息和冗余信息, 将筛选后的数据作为改进遗传算法的输入, 选择出适应性更强的特征; 改进遗传算法的变异概率根据输入的不同自动调整, 从而避免了人为设定阈值的主观不合理性。 为了验证算法的有效性, 全光谱、 去水波段光谱、 互信息所选光谱、 遗传算法选取光谱建立的模型进行比较, 以交互验证均方差(RMSECV)、 预测均方根差(RMSEP)和相关系数(R)为模型评价指标。
本方法分两个步骤进行。 第一步以条件互信息选择出与待测成分相关的特征, 这一步不仅考虑候选特征与待测成分的相关性并且考虑候选特征的冗余性。 第二步以第一步所选特征作为遗传算法的输入, 遗传算法变异过程运用Shapley值方法对基因进行变异操作, 得出更优秀的染色体, 这一步则通过遗传算法来寻找高辨别力的特征子集并避免了人为主观设定阈值的随机性。
互信息属于信息论的范畴, 是为了客观地测度信道中流通的信息[9]。 定义互信息I(X; Y)联合概率空间p(x, y)中的统计平均值Y对X的平均互信息量
平均互信息I(X; Y)克服了互信息量I(x; y)的随机性, 成为一个确定的量。 I(X; Y)表示收到Y前后关于X的不确定度减少量, 从Y获得的关于X的平均信息量。 平均互信息具有对称性, 即I(X; Y)=I(Y; X)。
互信息在数据挖掘和数据分析领域中, 用来评价一个事件的出现对于另外一件事件的出现所贡献的信息量。 因此互信息可以度量两个随机变量X和Y之间的相关程度。 互信息值越大表示两个随机变量相关程度越大, 互信息值为零时表示两个随机变量相互独立[10]。
在已选特征子集S条件下, 特征x与待测成分C的条件互信息为
已选特征子集S={s1, s2, …, sk}, i=1, 2, …, k; 当S=⌀时, 令|S|=1。 通过式(2)判断特征x是否与待测成分C相关。
p(x)函数估计方法为
其中xi为第i个样本数据, h为平滑参数, 设为h=1/m, m为样本数, n为样本维度, Σ 为协方差矩阵。
在遗传算法中人为固定变异概率的均匀变异方式适用于算法初级运行阶段, 随着算法搜索过程的执行, 这种方式会破坏最优解的稳定性。 因此, 提出基于Shapley值动态执行变异操作。
Shapley值法是一种博弈论方法, 用于解决多人合作分配收益的数学方法。 在博弈论中, 合作才可能会创造更大的效益[11, 12]。 设参与者合作的收益实值函数为ν , 函数定义在参与者N的非空子集S上, N={1, 2, …, n}, 则
式(5)表示没有参与者合作的总收益, ν (N)表示N个参与者共同合作的总收益, ν ({i})第i参与者不与其他参与者合作的收益, 式(6)代表了所有参与者合作的总收益大于参与者的收益之和。
Shapley值的无偏估计为
式中, ν (S)-ν (S\{i})表示参与者i对联盟S的边际贡献, ω (|S|)表示收益分配权重, |S|表示联盟S中参与者的个数。
采用Shapley值描述在多维特征数据集下, 每个基因(特征)在遗传算法过程中对染色体的重要性。 把一条染色体的n个基因(n个特征数量)看成N个参与者, 编码为“ 0” 的特征组成集合A, 编码为“ 1” 的特征组成集合B。 集合A中的元素ai与集合B组成一个新集合X, 即X=({ai}∪ B), i=1, 2, …, la(la为集合A的长度)。 计算ai在联盟X的Shapley值, 选出Shapley值最大特征amax。 amax的Shapley值最大, 说明其对联盟X贡献最大, 则将amax加入到集合B中, amax的值由“ 0” 变为“ 1” 。 集合B中的元素bj与集合A组成新的集合Y, Y=({bj}∪ A), j=1, 2, …, lb(lb为集合B的长度)。 计算bj在联盟Y的Shapley值, 选出Shapley值最大的特征bmax, 则将bmax加入到集合A中, bmax的值由“ 1” 变为“ 0” 。 由此方法来实现遗传算法的变异操作。
通过基于互信息的遗传算法选择出与待测成分相关性较大、 适应能力更强的特征进行建模。
具体方法和步骤如下:
Step 1 由1.1所述方法, m个样本n维特征光谱数据矩阵X=
通过式(2)循环计算在已选特征子集S条件下, 所有特征x与待测成分C的条件互信息, 根据如下情况判断特征x是否加入已选特征子集:
(1)当I(x|S; C)=0, 表示特征x不提供与待测成分C相关的新信息, 特征x被舍弃。
(2)当I(x|S; C)> 0, 表示特征x提供与待测成分C相关的新信息, 特征x加入已选特征子集S。
(3)当I(x|S; C)< 0, 表示特征x不提供与待测成分相关的新信息, 且特征x减少了待测成分C和特征子集S之间的互信息, 证明x是冗余信息。 所以这种情况下, 特征x不加入已选特征子集S。
Step 2 由Step 1得到的已选特征子集S作为遗传算法输入。 遗传算法的设计如下:
(1)编码方式染色体种群每一个染色体代表特征子集的候选集, 已选特征子集S={s1, s2, …, sk}里的每个特征代表一个基因, 对每一个染色体进行二进制串编码, “ 1” 表示特征被选择, “ 0” 表示特征不被选择。
(2)初始群体的大小根据Step 1中得到已选特征子集S的大小|S|确定。
(3)适应度函数采用交互验证法评价模型的预测能力。 用PLS交互验证得到相关系数(R)和预测均方根误差(RMSEP), PLS因子数设定为10。 适应度函数设为F=R/(1+RMSEP)[4]。
(4)选择: 采用基于排名的轮盘法选择方案, 为了保证快速收敛, 采用精英策略, 在当前种群中只有最好的20%染色体能够进入到下一代进行交叉和变异。
(5)交叉: 采用两点交叉方式, 交叉概率0.8。
(6)变异: 变异操作采用1.2所述方法, 为保证变异概率在0.001~0.1之间取值, 设定变异操作执行L/20次, L为染色体长度。
重复(4), (5)和(6), 当繁殖代数达到预设最大代数T时, 算法停止。
选取山东、 云南、 四川、 福建、 湖南5个产区的273个代表性烟叶样本。 从中随机选取182个样本为训练集, 其余91个样本为测试集。 样本烟碱含量分布范围在1.22%~4.58%。
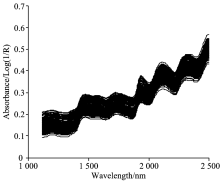
光谱采集过程: 实验使用丹麦FOSS公司生产的Foss DS2500光谱仪, 光谱采样间隔0.5 nm, 光谱扫描范围1 120~2 500 nm, 分辨率约为8 nm, 扫描次数64次。 将样品置于烘箱中, 60 ℃干燥4 h, 然后磨碎过40目筛, 密封储存平衡后将每个样品称重15 g。 光谱仪自检通过后, 将称重样品置于5 cm直径的洁净样品杯中, 用压样器轻压, 放入光谱扫描仪上进行扫描, 室温保持。 为了降低样品表面不均匀和外界环境的影响, 每个样品重复装样测定三次, 三次结果的平均值为样品光谱。 样本原始光谱图如图1所示。
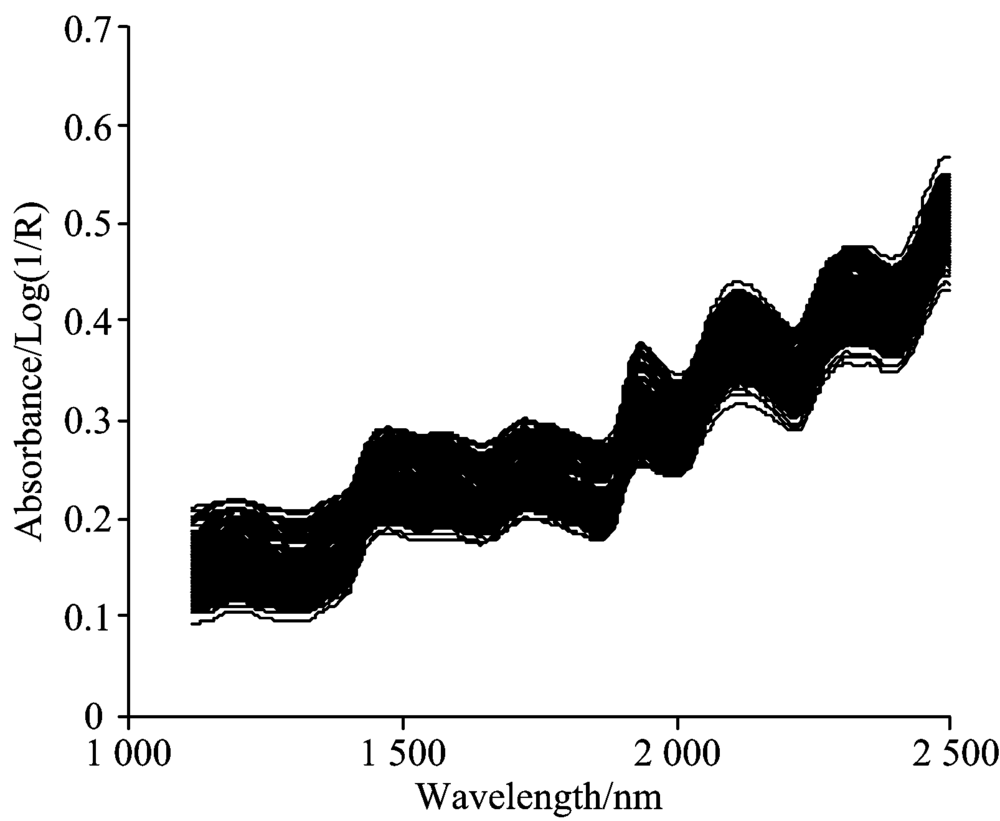 | 图1 原始光谱Fig.1 The raw spectra |
光谱预处理过程: 选用二阶导数加Norris(5)点平滑预处理方法去除高频随机噪声、 仪器随机误差以及样品不均匀导致的基线漂移对光谱数据的影响。
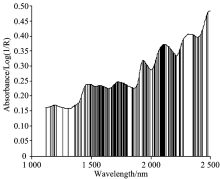
将上述得到的光谱数据作为实验对象。 首先, 以全光谱2 760个特征波长为基于互信息的遗传算法波长选择对象, 经过算法第一步得到已选特征子集S, 集合S的长度|S|=152, 即算法第一步选择出与待测成分相关且冗余信息少的特征波长为152个。 根据式(2)计算条件互信息, 所选特征子集如图2所示。
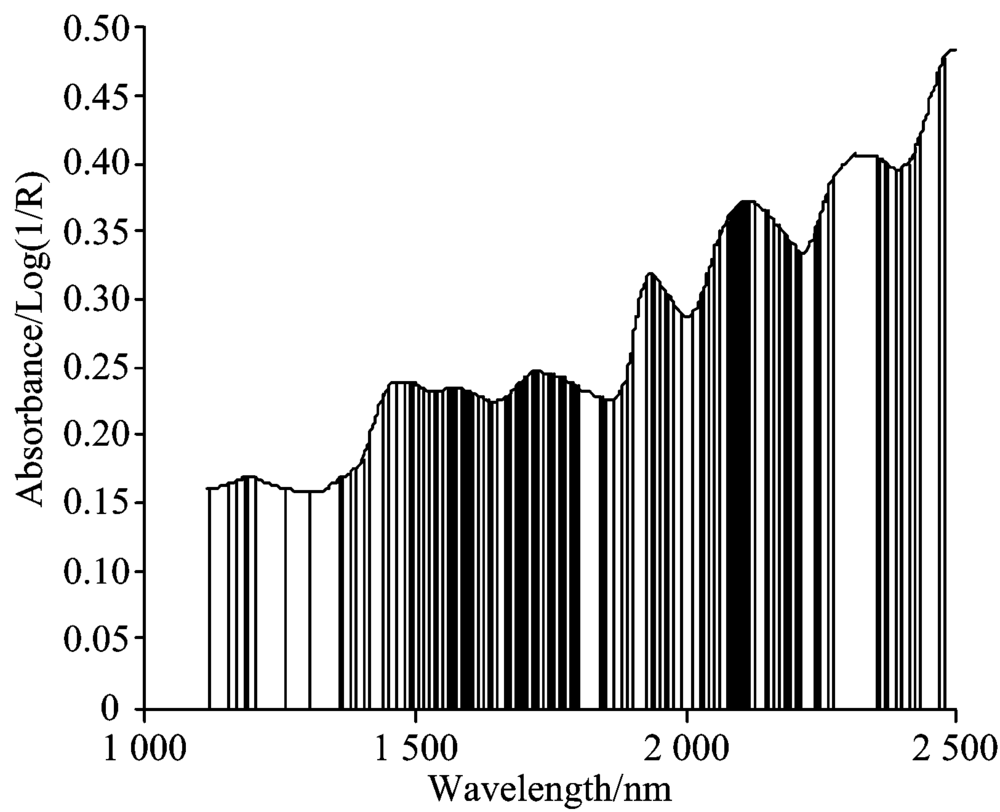 | 图2 互信息选择的特征Fig.2 Features selected by MI |
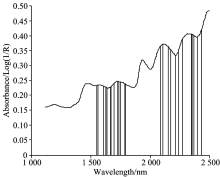
图2表明了与近红外光谱高维数据相比, 选择出的特征子集剔除了大量的噪声和冗余信息。 但经过互信息的选择, 所选的特征子集还会含有少量的冗余信息, 且包含适应力差、 抗干扰能力差的特征信息。 因此采用遗传算法来进行第二步的特征选择, 将特征子集S的152个特征波长作为改进的遗传算法的输入。 根据多次实验验证, 设定第二步改进遗传算法的初始种群大小为60, 交叉方式采用两点交叉方式。 所选特征波长如图3所示。
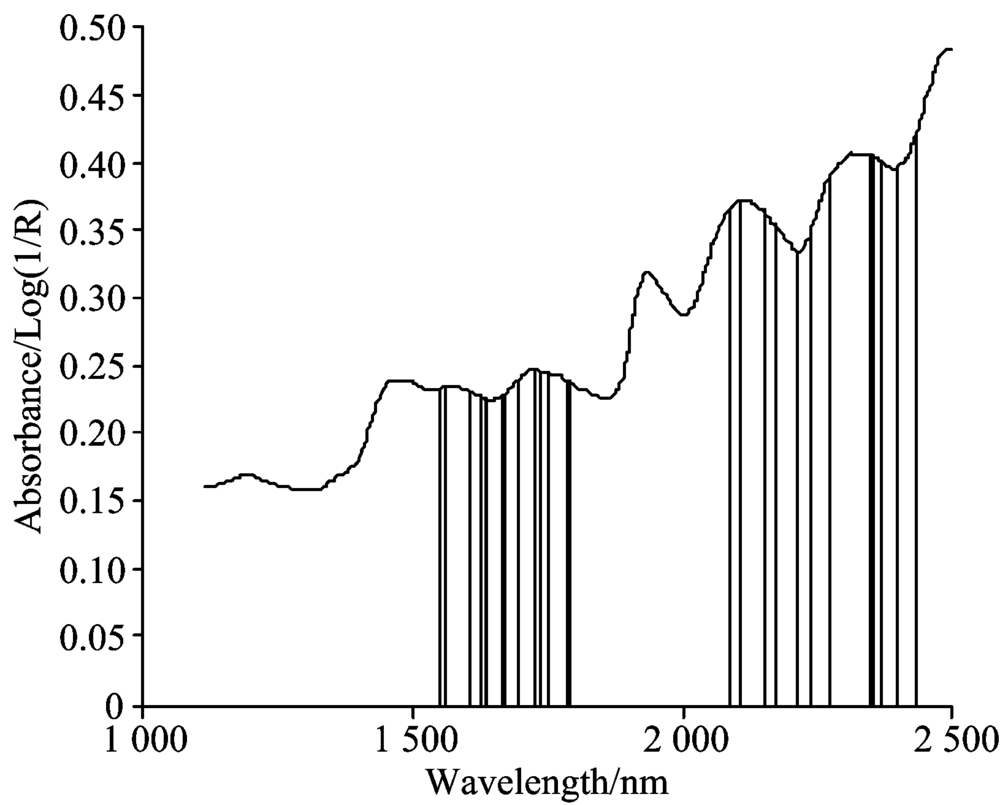 | 图3 GAs-MI选择的特征Fig.3 Features selected by GAs-MI |
图3所示改进遗传算法所选特征波长数为27, 所选特征无冗余、 适应力强、 抗干扰能力强。 通过基于互信息的遗传算法, 最终选择出具有高辨别力的特征子集。 以互信息选择的特征子集作为改进遗传算法的输入, 大大降低了算法的复杂度, 提高了算法效率。
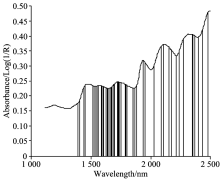
与遗传算法(GA)相比较。 遗传算法初始种群大小设为60, 交叉概率为0.8, 变异概率为0.05, 适应度函数与本方法相同。 遗传算法选择出53个特征波长, 如图4所示。
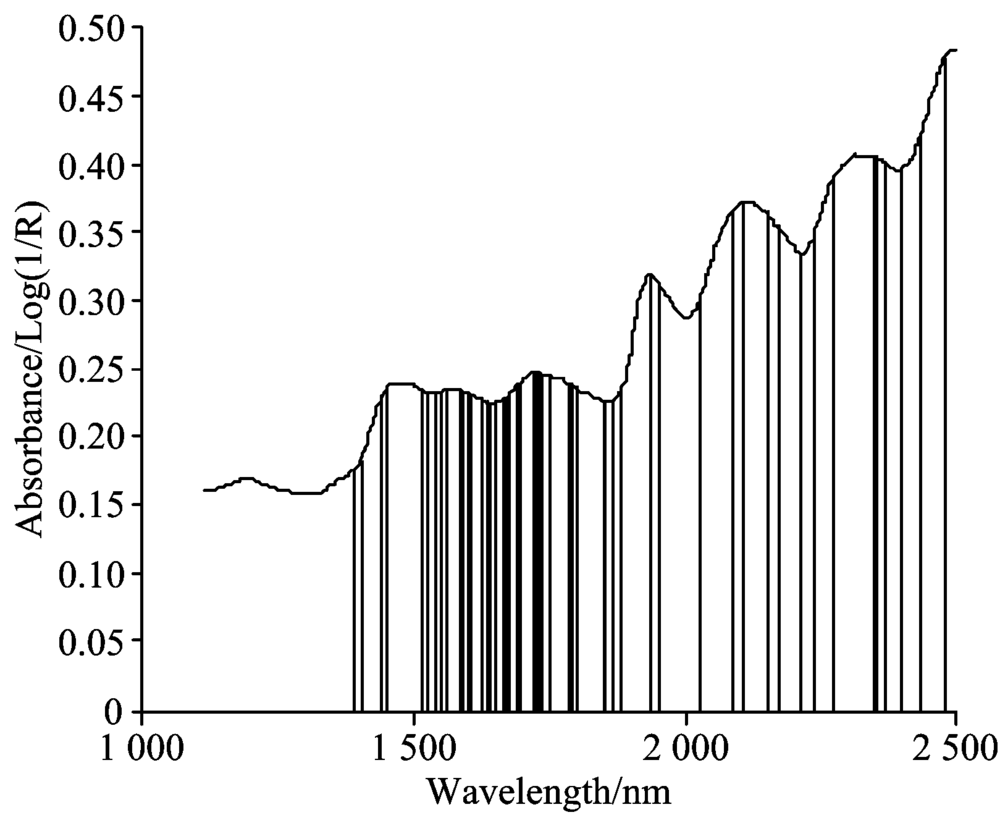 | 图4 遗传算法选择的特征Fig.4 Features selected by GA |
本文提出的GAs-MI方法解决了遗传算法在高维数据下收敛速度慢、 算法过程复杂、 应用困难的问题。 图4与图3相比, 遗传算法所选特征数目明显要比GAs-MI方法所选特征数目大。 因遗传算法的局部搜索能力差, 在搜索过程中会把与待测成分相关性不高的特征选入最优组合, 而GAs-MI方法在互信息过程中已经剔除了与待测成分相关性不高的特征。 变异过程通过Shapley值加以控制, 避免了现有方法设置变异概率的随机性, 特征波长与待测成分越相关、 优化组合的收益越大就越容易变异, 反之亦然。
为了验证提出的算法性能, 分别以全光谱2 760波长数、 去水波段光谱2 340波长数、 互信息选择出的152个波长数、 遗传算法(GA)选择出的53个波长数、 GAs-MI选择出的27个波长数作为PLS建模特征波长来构建总烟碱含量模型。 以相关系数(R)、 预测均方根差(RMSEP)和交互验证均方差(RMSECV)为模型评价指标, 结果如表1所示。
| 表1 不同波长的PLS模型参数 Table 1 PLS model parameters with different wavelengths |
由表1可以看出, 本方法所构建总烟碱含量模型的RMSECV和RMSEP比其他方法都低, 相关系数R比其他方法都高。 说明本方法所构建的总烟碱定量模型更加稳定、 预测能力更好。 全光谱中含有大量噪声、 背景信息、 冗余信息等, 这些信息会大大降低模型的性能。 因此, 以全光谱建模的各模型评价指标最差。 去水波段所建模型优于全光谱建立的模型, 是因为去水波段去除了水分特征吸收峰, 减少了水分特征的干扰。 互信息所选波长建立的模型性能明显优于全光谱和去水波段建立的模型, 主要因为互信息去除了大量噪声、 背景信息和大部分冗余信息, 但其选择出的波长变量仍含有少量冗余信息, 并且其中部分变量适应力差, 因此模型性能次于基于GAs-MI方法建立的模型性能。 从表1可以看出, GA方法与GAs-MI方法所选特征建立的模型性能更优, 因两种方法通过特征选择剔除了大量噪声、 背景信息、 冗余信息等干扰信息。 GAs-MI方法比GA方法的模型评价指标更好的原因是GAs-MI方法避免了GA方法在高维数据下全局搜索过程中选择相关性弱的特征, 并且减少了运算量。
基于互信息的遗传算法解决了高维近红外光谱建模计算时间长、 预测能力差的问题。 该方法发挥了遗传算法的并行性和全局搜索的优势, 降低了遗传算法在高维空间下的计算复杂度, 解决了遗传算法在高维空间应用困难的问题。 采用非人为设定变异算子的方法降低了人为设定阈值的主观影响, 将更优秀的特征选择出来。 实验结果表明, 本模型更加简单、 具有较好稳健性、 预测能力更强。 该算法可以为烟草质量检测和质量分析提供良好的依据。 结合实际应用, 如何降低算法计算复杂度、 提高算法效率, 仍是未来研究的重要方面。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|