



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于高光谱技术检测全蛋粉掺假的研究
[刘平 , 马美湖
, 马美湖* ]
, 马美湖]
|
|


作者简介: 刘 平, 女, 1990年生, 华中农业大学食品科学技术学院硕士研究生 e-mail: 13554081678@163.com
传统食品掺假分析多集中于检测特定已知或者怀疑可能存在的掺假物, 然而由于掺假形式的多样性以及新的掺假物不断出现, 使得传统检测方法具有局限性。 目前, 全蛋粉作为鲜蛋理想替代品掺假现象十分严重, 然而不管是国内还是国外, 其掺假检测都鲜有研究。 因此, 为了探索一种快速检测全蛋粉掺假的方法, 研究尝试使用最近快速发展起来的具有绿色、 无损等优点的高光谱技术来检测全蛋粉掺假的可行性。 从不同地区收集不同品牌的鸡蛋全蛋粉, 按不同比例分别掺入淀粉、 大豆分离蛋白、 麦芽糊精以及三种掺假物的混合物进行试验样品的制备。 样品进行光谱采集后, 采用ENVI软件选取感兴趣区域(ROI)后提取出平均光谱。 根据获得的光谱数据建立全波段下支持向量机(SVM)模型进行掺假的判别并采用偏最小二乘回归(PLSR)模型建立全波段与掺假浓度之间的关系。 结果显示, 采用径向基核函数所建立的SVM模型, 其分类的正确率达到90%以上, 基于PLSR建立掺假模型实际值与预测值相关系数
Traditional analysis of food adulteration is more concentrated in the detection of specific known or suspected adulterants which may exist. However, due to the variety of adulteration and the emergence of new adulterants, the traditional detection methods have limitations. Currently,as an ideal substitute for fresh egg,the adulteration of egg powder is serious, but the problem is rarely studied both at home and abroad. In order to explore a rapid detection method of whole egg powder adulteration, this study attempted to use hyperspectral technology green and nondestructive in its advantages to detect the feasibility of whole egg powder with several adulterants. Different brands of egg powder were collected from different area and the common adulterants (starch, soy isolate protein, maltodextrin and mixture) were added in in proportion. After spectral acquisition, the region of interest (ROI) was extracted by ENVI and the mean spectra were extracted. Firstly, the support vector machines (SVM) models were founded to identify the adulteration and the Partial least squares (PLSR) model was used to establish the relationship between the full bands and adulteration concentration. The results showed that the correctness of the SVM model based on RBF kernel function was more than 90%, and the correlation coefficient between the actual value and the prediction value of the adulteration model based on PLSR was higher than 0.90. In order to simplify the model, the regression coefficient method (RC) and the successive projections algorithm (SPA) were used to extract the characteristic wavelengths, and the RC-PLSR model and SPA-PLSR were established according to the spectral data at the characteristic wavelength. The results showed that the simplified models still have good performance, indicating that the hyperspectral technique to detect adulteration of whole egg powder is feasible.
食品掺假是一个全球性问题, 不仅影响消费者的健康和安全, 而且还歪曲了特定产品的质量, 有时会导致有害健康甚至致命的后果。 全蛋粉具有高质量的蛋白质、 均衡的矿物质和维生素且具有安全便于携带的优点, 成为鸡蛋的理想替代品[1]。 随着蛋粉的市场需求量不断增加, 同时由于其质地为粉末状掺入其他物质不易察觉, 某些蛋粉生产企业在蛋粉中掺入更廉价的物质以降低成本, 使得消费者的权益受到损害, 也使正规蛋粉产业的生产和销售受到威胁。
当前, 中国关于食品掺假事件时有报道, 因此在食品安全方面急需有效的检测方法。 一般来说, 对于物质的掺假检测会涉及到很多方法, 包括感官识别法、 高效液相色谱法、 气质联用、 酶联免疫法、 聚合酶键式反应(polymerase chain reaction, PCR)技术等, 每一种方法都有它的优势和劣势。 比如, 感官评价需要高素质、 经验丰富的检验员并且容易受主观因素的影响; 高效液相色谱和气质联用可以做到非常精确的结果但是不仅需要熟练的操作人员而且机器本身十分昂贵; 酶联免疫法可以识别特异性抗原成本低适宜液体样品, 但是其对高温非常敏感且对于植物蛋白常出现交叉反应影响准确性; PCR技术可以识别特异性DNA序列但成本极高[2]。
高光谱技术作为一种无损检测技术迅速发展起来, 与其他光谱技术相比信息更全面, 目前高光谱技术被广泛应用于食品成分检测、 产地和种类鉴别、 掺假检测等方面。 Mohammed等利用高光谱检测技术将羊肉和掺入猪肉及各种内脏的羊肉进行有效的区分, 同时对掺入潜在掺假物猪肉的羊肉进行了定量预测[3]; Wu等第一次采用高光谱技术检测对虾中掺假的明胶[4]; Xiong等探究了基于高光谱图像的特征光谱信息与纹理信息在快速鉴别土鸡与普通肉鸡上的可能性, 实验基于全波长光谱、 特征波长光谱、 纹理变量的融合数据分别建立LS-SVM和ANN鉴别模型, 基于融合数据建立的LS-SVM和ANN的CCR 分别为95%和92.5%, 均高于基于特征波长光谱/纹理变量所建LS-SVM和ANN, 证明了高光谱成像技术的特征光谱与图像纹理数据的融合可实现土鸡与普通肉鸡的快速鉴别[5]。 然而当前将高光谱技术应用到鉴别全蛋粉掺假的研究还鲜有报道。 本工作尝试应用高光谱技术来检测全蛋粉掺假, 以期能为蛋粉产业的品质监管提供有用的信息。
1.1.1 干蛋粉掺假物
大桥牌淀粉, 购于武汉市教育超市; 谷神牌大豆分离蛋白, 购于百盛生物科技公司; 麦芽糊精, 购于百盛生物科技公司
1.1.2 真蛋粉样品
收集实验室自制、 湖北神地农业科贸有限公司、 江苏康德蛋业有限公司、 安徽红日食品有限责任公司、 亳州市众意蛋业有限责任公司、 河南中信生物科技有限公司的全蛋粉共6种, 以增加它们之间的变异性, 称取真蛋粉30份, 放置于4 ℃冰箱中贮藏。
1.1.3 掺假蛋粉样品
对掺假物质(淀粉、 大豆分离蛋白、 麦芽糊精), 过1 mm标准筛理。 用电子分析天平准确称量, 随机抽取不同品牌的全蛋粉分别掺入质量浓度2%, 4%, 6%, 8%, 10%, 12%, 14%, 16%, 18%, 20%的淀粉, 每个浓度5个样品; 分别掺入质量浓度1%, 5%, 10%, 20%, 30%, 40%, 50%的大豆分离蛋白, 每个浓度5个样品; 分别掺入质量浓度1%, 5%, 10%, 20%, 30%, 40%, 50%的麦芽糊精, 每个浓度5个样品。 对于多种物质混合掺假, 分别掺入浓度为20%(10%大豆蛋白、 麦芽糊精和淀粉各5%; 10%大豆蛋白、 10%麦芽糊精; 10%大豆蛋白、 10%淀粉)、 30%(大豆蛋白、 麦芽糊精和淀粉各10%; 20%大豆蛋白、 10%麦芽糊精; 20%大豆蛋白、 10%淀粉)和40%(20%大豆蛋白、 麦芽糊精和淀粉各10%; 30%大豆蛋白、 10%麦芽糊精; 30%大豆蛋白、 10%淀粉)的掺假物, 每个掺假浓度分为三种掺假形式(括号内显示), 每种掺假形式5个样品。 将混合后的干粉置于50 mL聚丙烯离心管中, 用旋涡混合器振荡超过1 min, 以确保掺假物颗粒均匀分布在干粉中。 将配制好的样品放入塑料培养皿(直径47 mm, 高度7.0 mm)每个培养皿略满, 无压缩干粉末, 然后用玻璃棒顶端平整样品使样品表面平滑, 并用勺子去除多余的粉末。 最终每个培养皿中大约装有样品10 g。 采用随机抽样的分配原则, 随机选取3/5作为校正集, 2/5作为预测集。 最终校正集共有样品117个(真样品18个, 掺假样品99个), 验证集共有样品78个(真样品12个, 掺假样品66个)。
采用的高光谱成像系统如图1所示, 光谱仪波长范围: 400~1 000 nm; 光谱分辨率8 nm; 有效像素1 392× 1 040, 卤素灯灯泡安置在图像采集暗箱上部。 采集图像时将装满样品的培养皿放置于移动平台上, 为了使得图像不失真对实验参数进行了设置, 最终将相机曝光时间设定为20 ms, 平台的移动速度设为2 mm· s-1。
 | 图1 高光谱系统Fig.1 Structure of hyperspectral imaging system |
1.3.1 图像校正
在高光谱成像系统中, 为了减少摄像头中暗电流带来的影响, 获取的高光谱原始图像用式(1)进行黑白场的校正[4]
式(1)中, R为校正后的高光谱图像, R0为原始高光谱图像, B为黑场图像, W为白场图像。 所有校正后的图像都用作以后提取光谱信息, 重要波长选择以及掺假含量预测的分析基础。
1.3.2 感兴趣区域(RIO)的选择
感兴趣区域的提取是高光谱检测的关键步骤, 直接影响后续模型的精度。 一般来说分为矩阵区域法和图像分割法, 本研究中, 采用矩阵区域法选择出100像素× 100像素的区域作为感兴趣区域, 然后通过计算RIO内所有像素的反射率平均值得到每个样本的平均光谱数据, 重复此操作获得所有样品的高光谱数据。
1.3.3 图像预处理
高光谱成像系统采集的光谱信息不仅包含样本自身的有用信息, 同时也含有一些无关信息和噪声, 其对后续模型的建立以及精度都会产生影响。 为了减少系统噪音以及产生的杂散光等影响, 提高所建模型的预测能力和稳健性, 要对光谱进行预处理[6]。 常用的光谱预处理方法有平滑、 变量标准化(SNV)、 多元散射校正(MSC)和导数法、 基线校正、 标准化等[7]。 本研究将对光谱进行不同的预处理, 并根据模型的预测能力对预处理方法进行选择, 最后得到最佳的处理方式。
1.4.1 多元数据分析
支持向量机模型, 是一种基于统计学习理论的机器学习方法, 它可以克服传统方法的大样本要求与维数灾难及局部收敛, 能够较好地解决神经网络难以解决的小样本、 高维数和存在局部极小点等实际问题[8], 通过此模型可以对真假全蛋粉进行有效分类。 大的光谱数据包含了大量的隐藏信息, 这也与掺假含量的预测有很大的关系。 因此, 重要的是要选择一个可靠的建模方法建立定量分析的校准模型。 目前, 有多种建模方法, 比如偏最小二乘回归模型(PLSR)[9]、 多元线性回归模型(MLR)[3]、 人工神经网络(ANN)[10], 支持向量机模型(SVM)[11]等。 本研究采用偏最小二乘回归预测全蛋粉中掺假的量, 它是一种应用非常广泛且高效的预测方法, 其目的就是寻找到两个数据集合即光谱数据和掺假含量数据集之间的数学关系, PLSR同时对光谱X变量和掺假含量Y变量进行分解, 获得描述X与Y之间最大协方差的潜在变量(LVs), 潜在变量的最佳数目最终应用于获得可靠的预测模型。 最终, 根据LV的累积贡献率和预测残差平方和建立光谱和掺假含量之间的回归模型。
1.4.2 特征波长的选取
因为所获得的高光谱图像是高维的, 因此在多变量分析中存在多重共线性的问题。 在整个光谱中的一些波长与掺假含量的预测无关, 因此删除这些不相关的波长不仅可以提高计算的速度并且可以使模型更容易解释。 在全波长中提取重要波长的方法多种多样, 如回归系数法(RC)、 连续投影算法(SPA)、 独立成分分析法(PCA)、 遗传算法(GA)等[11]。 本研究, 采用回归系数法及连续投影法选取重要波长, 然后分别建立了特征波长下的PLSR模型。
1.4.3 模型的评价
回归模型的性能主要是通过样本参考值和预测值之间的相关系数(R2)和均方根误差(RMSE)进行评价。 模型的均方根误差越接近0, 相关系数越接近 1, 则模型的预测性能越好, 精度越高[10]。 本研究主要采用校正集和预测集样本的相关系数(
本研究的流程见图2。
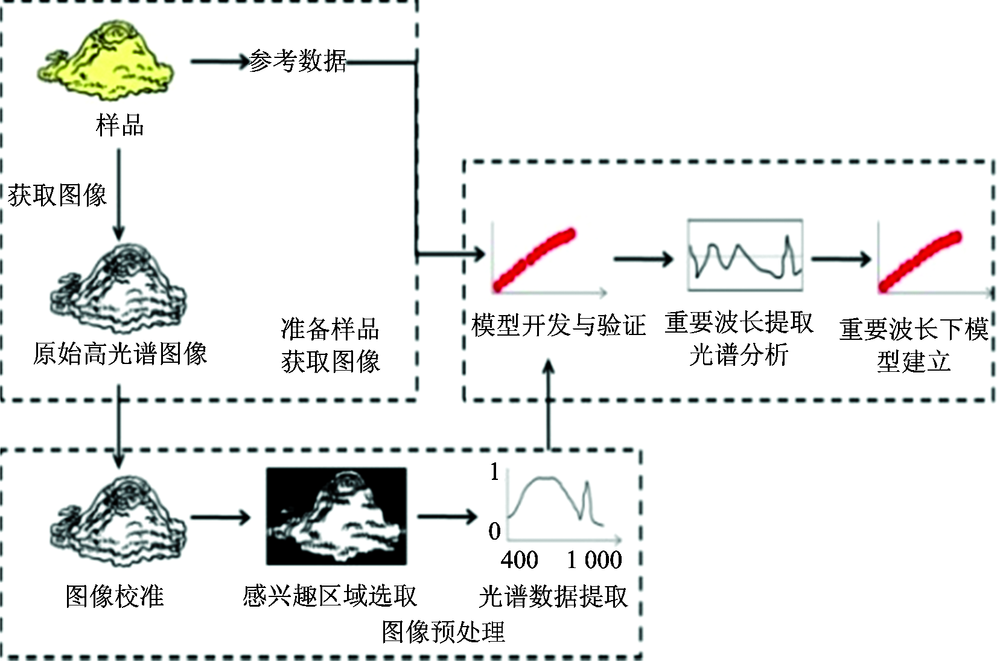 | 图2 主要步骤流程图Fig.2 Flowchart of the main steps for analyzing hyperspectral images |
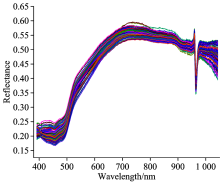
图3为所有样品高光谱图像, 样品的光谱重叠性严重, 不能通过肉眼进行有效识别, 但可以看出总体趋势是随着掺假含量的升高, 反射率在不断提高。 总体上来看, 不同掺假浓度的样品是具有可以区分性的, 这也为以后的分类以及掺假含量的预测提供了一定的基础。
 | 图3 所有样品高光谱图Fig.3 Reflectance of all samples |
SVM核函数采用了径向基核函数, 最终利用留一交叉验证法确定参数(C, γ )的设置[12]。
如表1全蛋粉掺假的SVM模型的预测结果所示, 校正集和预测集分别有7个和5个掺假样品被误判, 判别正确率分别为94.02%和93.59%, 可以看出校正集和预测集判别正确率都达到90%以上, 说明在全波段数据范围下, SVM模型可以对全蛋粉是否掺假进行有效判别。
| 表1 全蛋粉掺假SVM的预测结果 Table 1 Predictive result of SVM model of whole egg powder adulteration |
为了消除所采集的光谱中无关信息和系统噪声等, 研究对原始光谱进行了光谱预处理。 系统研究了SNV, MSC, S-G平滑, Normalize以及Baseline等几种不同的预处理方法, 然后分别基于各预处理光谱建立全波长PLSR模型。 从表2看, 通过进行不同的预处理, 模型的性能和稳健性都得到了不同程度的提高, 使得PLSR模型获得了更高的相关系数和更低的预测均方根误差。 因此, 后续模型的建立等都采取最佳的预处理方式。
| 表2 基于不同预处理方式建立的全蛋粉掺假的全波段下的PLSR模型的预测结果 Table 2 Predictive result of PLSR model for egg powder adulteration based on different pretreatment at full wavelength |
如表2所示, 可以看到全蛋粉掺假(淀粉、 大豆蛋白、 麦芽糊精、 混合物)的PLSR模型所对应的最佳处理方式分别是Baseline, Normalize, Baseline和无预处理, 所建立的PLSR模型的
全光谱波长数据量大且相邻波长数据点存在冗余和共线性问题, 同时其高维性限制了其在线应用[13]。 因此, 需要从全波长光谱中挑选出最具代表性的特征波长, 从而满足快速检测的要求。 本研究采用了回归系数法(RC)和连续投影法(SPA)两种方法。
图4为采用回归系数法提取特征波长的回归系数图, 不同波长所对应的回归系数表示该波长点的预测性能, 因此通常选取回归系数曲线中的波峰和波谷作为特征波长进行提取[3], 如图4所示在全蛋粉掺假的研究中, 淀粉、 大豆蛋白、 麦芽糊精及混合物的掺假选出的特征波长分别为8个(392.46, 530.64, 665.04, 862.26, 960.24, 967.77, 1 023.04, 1 026.81), 11个(484.16, 559.53, 579.63, 697.7, 771.82, 849.7, 925.07, 953.96, 964.01, 971.54, 1 041.81), 11个(405.02, 486.67, 558.27, 565.81, 642.43, 695.19, 768.05, 923.81, 952.7, 960.24, 969.03)和7个(487.93, 667.56, 734.13, 920.04, 943.9, 961.49, 972.8)。 而基于连续投影法选出的特征波长的结果如表3所示。
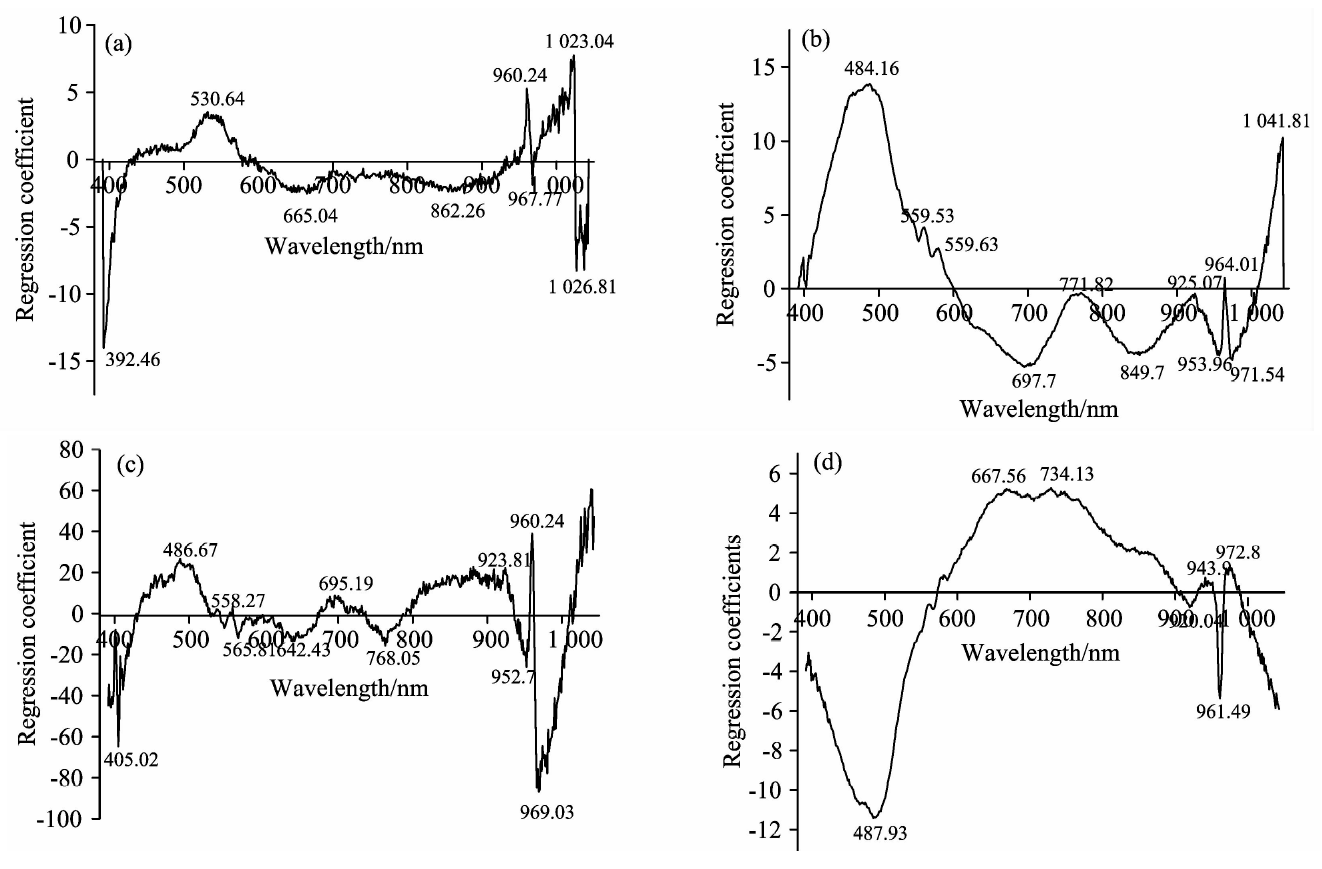 | 图4 样品回归系数图 (a), (b), (c), (d)分别为全蛋粉中掺淀粉、 大豆蛋白、 麦芽糊精及混合物的回归系数图Fig.4 Regression coefficients for selecting important wavelengths (a), (b), (c), (d) represent regression coefficients of starch, soy protein, maltodextrin and mixture adulteration, respectively |
| 表3 基于SPA法的特征波段的选取 Table 3 Characteristic wavelengths based on SPA |
选取特征波长后, 根据两种方法获得的特征波长分别建立RC-PLSR和SPA-PLSR简化模型。 建模过程中, 为了检验模型是否过拟合采用了留一交互验证的方法。 所得结果如表4所示。 可以看出在全蛋粉掺假研究中淀粉、 大豆蛋白、麦芽糊精和混合物掺假经过相关系数法获取的波长所得到的RC-PLSR模型其
| 表4 基于特征波长下全蛋粉掺假的PLSR模型的预测结果 Table 4 Predictive result of PLSR model for whole egg powder adulteration at characteristic wavelengths |
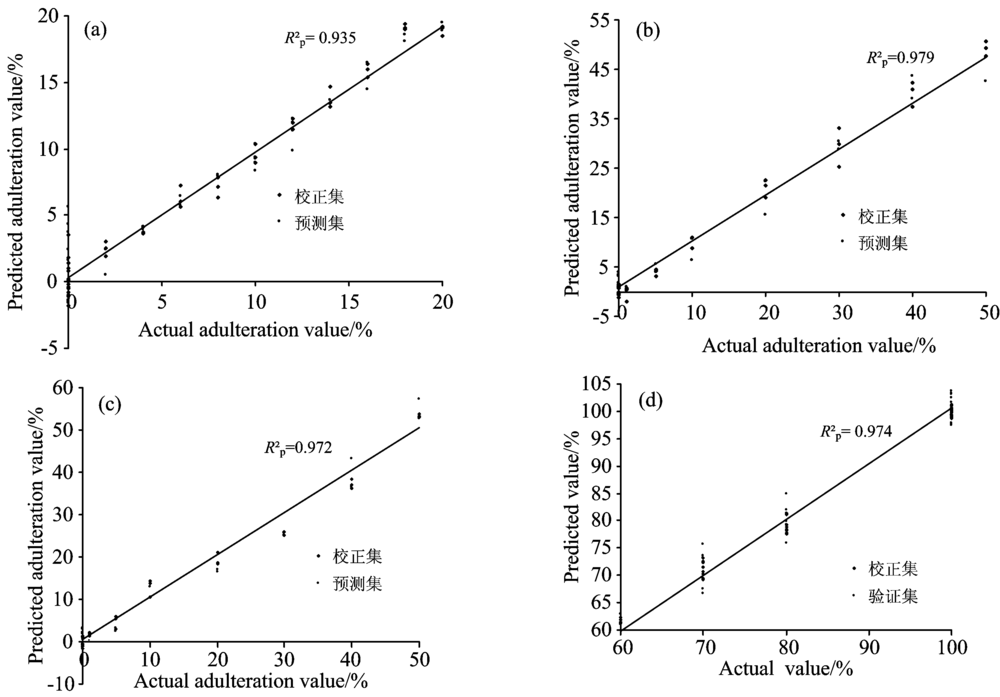 | 图5 掺假模型中预测值与真实值的相关关系 (a), (b), (c), (d)分别代表全蛋粉中掺淀粉、 大豆蛋白、 麦芽糊精及混合物的掺假模型中预测值与真实值的相关关系Fig.5 Performance between predicted value and true value in the adulteraction model (a), (b), (c), (d) represent the relationship between predicted value and true value in the model of starch, soy protein, maltodextrin and mixture adulteration, respectively |
随着蛋粉的市场需求量在不断的增加, 其掺假问题也越来越受到市场研究者以及消费者的关注, 本研究将高光谱技术应用于蛋粉掺假的检测。 实验结果显示, 高光谱技术结合适当的多元化学计量学方法可以有效的识别蛋粉的掺假。 通过采集真实样品和掺假样品的高光谱图像并提取平均光谱, 然后用校正集样本的光谱与掺假含量值建立PLSR回归模型, 全蛋粉掺假的研究中, 淀粉、 大豆蛋白、 麦芽糊精和混合物掺假
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|